[BigData]关于Hadoop学习笔记第三天(PPT总结)(一)
课程安排
MapReduce原理***
MapReduce执行过程**
数据类型与格式***
Writable接口与序列化机制***
---------------------------加深拓展----------------------
MapReduce的执行过程源码分析
问题:怎样解决海量数据的计算?

MapReduce概述
Mapreduce原理
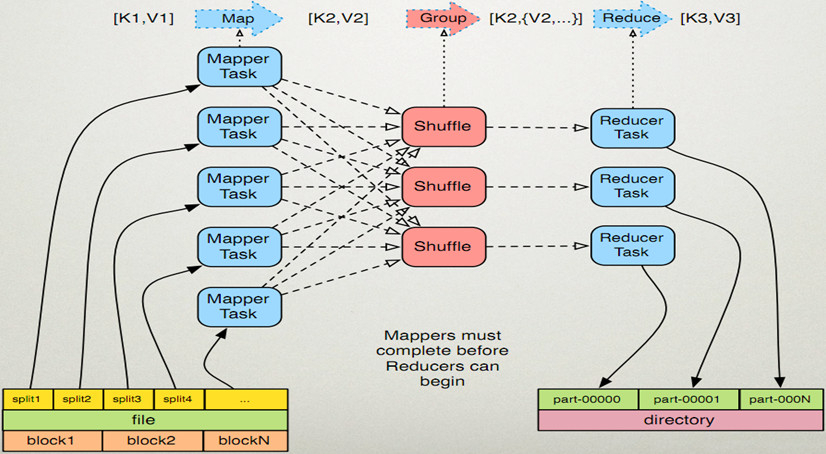
◆执行步骤:
1. map任务处理
1.1 读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。
1.2 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
2.reduce任务处理
2.1写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
2.2把reduce的输出保存到文件中。
map、reduce键值对格式

WordCountApp的驱动代码
Configuration conf = new Configuration(); //加载配置文件
Job job = new Job(conf); //创建一个job,供JobTracker使用
job.setJarByClass(WordCountApp.class); job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class); FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.1.10:9000/input"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.1.10:9000/output")); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); job.waitForCompletion(true);
}
MR流程
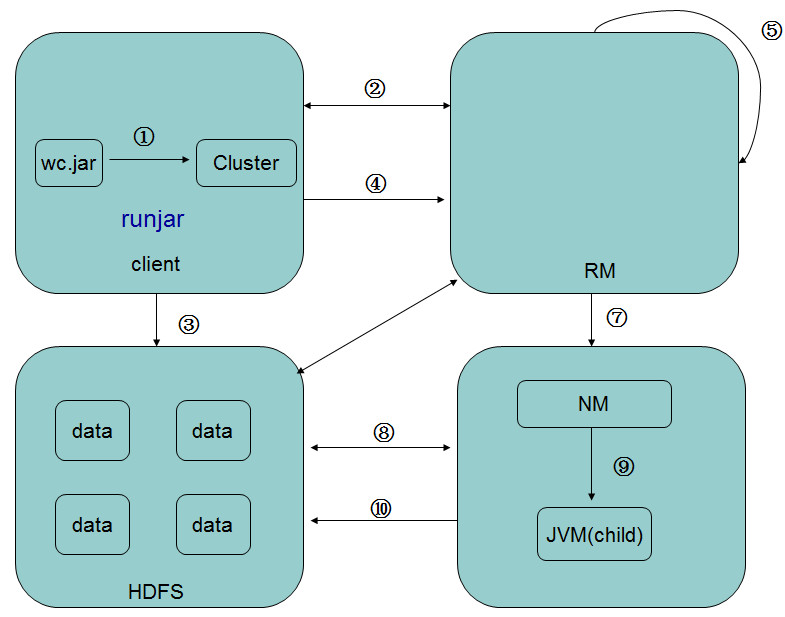
MR过程各个角色的作用
作业提交
任务分配
JobTracker
TaskTracker
JobClient

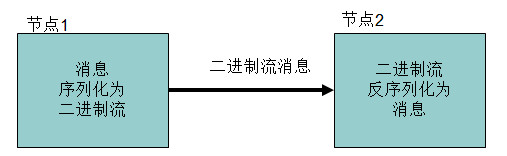
序列化概念
Hadoop序列化的特点
l序列化格式特点:
Hadoop的序列化格式:Writable
Java序列化的不足:
1.不精简。附加信息多。不大适合随机访问。
2.存储空间大。递归地输出类的超类描述直到不再有超类。序列化图对象,反序列化时为每个对象新建一个实例。相反。Writable对象可以重用。
3.扩展性差。而Writable方便用户自定义
Hadoop序列化的作用
l序列化在分布式环境的两大作用:进程间通信,永久存储。
Writable接口

•MR的任意key必须实现WritableComparable接口

常用的Writable实现类
Text一般认为它等价于java.lang.String的Writable。针对UTF-8序列。
例:
Text test = new Text("test");
IntWritable one = new IntWritable(1);


自定义Writable类
Writable

MapReduce输入的处理类
FileInputFormat是所有以文件作为数据源的InputFormat实现的基类,FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法是有不同的子类——TextInputFormat进行实现的。
InputFormat
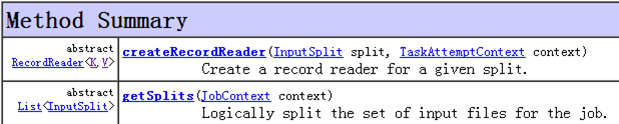
InputFormat 负责处理MR的输入部分.
InputSplit
◆ 在执行mapreduce之前,原始数据被分割成若干split,每个split作为一个map任务的输入,在map执行过程中split会被分解成一个个记录(key-value对),map会依次处理每一个记录。
◆ FileInputFormat只划分比HDFS block大的文件,所以FileInputFormat划分的结果是这个文件或者是这个文件中的一部分.
◆ 如果一个文件的大小比block小,将不会被划分,这也是Hadoop处理大文件的效率要比处理很多小文件的效率高的原因。
◆ 当Hadoop处理很多小文件(文件大小小于hdfs block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个split并分配一个map任务,导致效率底下。
例如:一个1G的文件,会被划分成16个64MB的split,并分配16个map任务处理,而10000个100kb的文件会被10000个map任务处理。
TextInputFormat
◆ TextInputformat是默认的处理类,处理普通文本文件。
◆ 文件中每一行作为一个记录,他将每一行在文件中的起始偏移量作为key,每一行的内容作为value。
◆ 默认以\n或回车键作为一行记录。
◆ TextInputFormat继承了FileInputFormat。
InputFormat类的层次结构

其他输入类
◆ CombineFileInputFormat
相对于大量的小文件来说,hadoop更合适处理少量的大文件。
CombineFileInputFormat可以缓解这个问题,它是针对小文件而设计的。
◆ KeyValueTextInputFormat
当输入数据的每一行是两列,并用tab分离的形式的时候,KeyValueTextInputformat处理这种格式的文件非常适合。
◆ NLineInputformat
NLineInputformat可以控制在每个split中数据的行数。
◆ SequenceFileInputformat
当输入文件格式是sequencefile的时候,要使用SequenceFileInputformat作为输入。
自定义输入格式
1)继承FileInputFormat基类。
2)重写里面的getSplits(JobContext context)方法。
3)重写createRecordReader(InputSplit split, TaskAttemptContext context)方法。
(讲解源代码)
Hadoop的输出
◆ TextOutputformat
默认的输出格式,key和value中间值用tab隔开的。
◆ SequenceFileOutputformat
将key和value以sequencefile格式输出。
◆ SequenceFileAsOutputFormat
将key和value以原始二进制的格式输出。
◆ MapFileOutputFormat
将key和value写入MapFile中。由于MapFile中的key是有序的,所以写入的时候必须保证记录是按key值顺序写入的。
◆ MultipleOutputFormat
默认情况下一个reducer会产生一个输出,但是有些时候我们想一个reducer产生多个输出,MultipleOutputFormat和MultipleOutputs可以实现这个功能。
思考题
[BigData]关于Hadoop学习笔记第三天(PPT总结)(一)的更多相关文章
- [BigData]关于Hadoop学习笔记第四天(PPT总结)(一)
课程安排 Partitioner编程** 自定义排序编程** Combiner编程** 常见的MapReduce算法** ---------------------------加深拓展-------- ...
- Hadoop学习笔记(三):分布式文件系统的写和读流程
写流程:怎么将文件切割成块,上传到服务器 读流程:怎么从不同的服务器来读取数据块 写流程 图一 图二 写的过程中:NameNode会给块分配存储块的位置,每次想要存储文件的时候都会在NameNode创 ...
- [BigData]关于Hadoop学习笔记第二天(PPT总结)(一)
Plan: 分布式文件系统与HDFS HDFS体系结构与基本概念 HDFS的shell操作 java接口及常用api HADOOP的RPC机制 HDFS源码分析 远程debug 自己设计一分布式文件系 ...
- [BigData]关于Hadoop学习笔记第一天(PPT总结)(一)
适合大数据的分布式存储与计算平台 l作者:Doug Cutting l受Google三篇论文的启发 lApache 官方版本(1.0.4) lCloudera 使用下载最多的版本,稳定,有商业支持 ...
- Hadoop学习笔记(三):java操作Hadoop
1. 启动hadoop服务. 2. hadoop默认将数据存储带/tmp目录下,如下图: 由于/tmp是linux的临时目录,linux会不定时的对该目录进行清除,因此hadoop可能就会出现意外情况 ...
- hadoop学习笔记(三):hdfs体系结构和读写流程(转)
原文:https://www.cnblogs.com/codeOfLife/p/5375120.html 目录 HDFS 是做什么的 HDFS 从何而来 为什么选择 HDFS 存储数据 HDFS 如何 ...
- hadoop学习笔记(三):hadoop文件结构
hadoop完整安装目录结构: 比较重要的包有以下4个: src hadoop源码包.最核心的代码所在目录为core.hdfs和mapred,他们分别实现了hadoop最重要的3个模块:基础公共库.H ...
- hadoop学习笔记-目录
以下是hadoop学习笔记的顺序: hadoop学习笔记(一):概念和组成 hadoop学习笔记(二):centos7三节点安装hadoop2.7.0 hadoop学习笔记(三):hdfs体系结构和读 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
随机推荐
- c语言函数的可选性自变量
功能: 宏va_arg()用于给函数传递可变长度的参数列表. 首先,必须调用va_start() 传递有效的参数列表va_list和函数强制的第一个参数.第一个参数代表将要传递的参数的个数. 其次,调 ...
- IE中的文档兼容性
文档兼容性可定义 Internet Explorer 呈现网页的方式, 具体可以参考 https://msdn.microsoft.com/zh-cn/library/cc288325(v=vs.85 ...
- Oracle DB 执行用户管理的备份和恢复
• 说明用户管理的备份和恢复与服务器管理的备份和恢复 之间的差异 • 执行用户管理的数据库完全恢复 • 执行用户管理的数据库不完全恢复 备份和恢复的使用类型 数据库备份和恢复的类型包括: • 用户管理 ...
- hdu 4786 Fibonacci Tree (2013ACMICPC 成都站 F)
http://acm.hdu.edu.cn/showproblem.php?pid=4786 Fibonacci Tree Time Limit: 4000/2000 MS (Java/Others) ...
- sql的存储过程调用
USE [ChangHong_612]GO/****** Object: StoredProcedure [dbo].[st_MES_GetCodeRule] Script Date: 09/10/2 ...
- C#文件后缀名详解
C#文件后缀名详解 .sln:解决方案文件,为解决方案资源管理器提供显示管理文件的图形接口所需的信息. .csproj:项目文件,创建应用程序所需的引用.数据连接.文件夹和文件的信息. .aspx:W ...
- word2007 每页显示表头
word2007 每页显示表头 在Word 2007文档中,如果一张表格需要在多页中跨页显示,则设置标题行重复显示很有必要,因为这样会在每一页都明确显示表格中的每一列所代表的内容.在Word 2007 ...
- VS清除缓存
今天不小心在项目里面把一个 == 写成了 =,结果数据一下子崩溃了. 后来测试,发现,换一个编译环境,或者换一个编译模式比如debug改成release,就好使了. 1 测试流程 2 测试数据 3 ...
- java的BigDecimal
java的BigDecimal 一般设计到高精度的加法或乘法或者阶乘的求和积都会用到BigDecimal这个类. import java.util.*;import java.math.BigDeci ...
- Android布局优化之include、merge、ViewStub的使用
本文针对include.merge.ViewStub三个标签如何在布局复用.有效减少布局层级以及如何可以按需加载三个方面进行介绍的. 复用布局可以帮助我们创建一些可以重复使用的复杂布局.这种方式也意味 ...