MYSQL利用merge存储引擎来实现分表
创建user1和user2两个分表
建表语句如下:只是表名不一样,其他字段信息及主键一致。
CREATE TABLE IF NOT EXISTS user1(
id INT(11) NOT NULL AUTO_INCREMENT,
NAME VARCHAR(50) DEFAULT NULL,
sex INT(1) NOT NULL DEFAULT '0',
PRIMARY KEY (id)
)ENGINE=MYISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1;CREATE TABLE IF NOT EXISTS user2(
id INT(11) NOT NULL AUTO_INCREMENT,
NAME VARCHAR(50) DEFAULT NULL,
sex INT(1) NOT NULL DEFAULT '0',
PRIMARY KEY (id)
)ENGINE=MYISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1;加入测试数据:
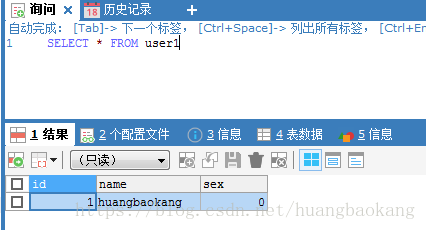
INSERT INTO user1(NAME,sex) VALUES('huangbaokang',0)
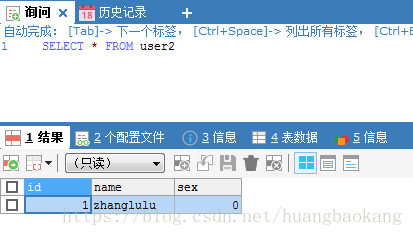
INSERT INTO user2(NAME,sex) VALUES('zhanglulu',0)创建总表:
CREATE TABLE IF NOT EXISTS t_user (
id INT(11) NOT NULL AUTO_INCREMENT,
name VARCHAR(50) DEFAULT NULL,
sex INT(1) NOT NULL DEFAULT '0',
INDEX(id)
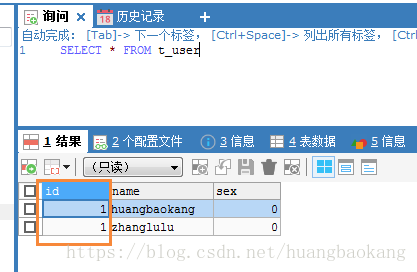
) ENGINE = MRG_MYISAM UNION =(user1,user2) INSERT_METHOD LAST CHARSET UTF8;采用merge类型,insert_method为last
查询结果如下:
往t_user表中插入一条数据:
INSERT INTO t_user(NAME,sex) VALUES('猪八戒',1);- 1
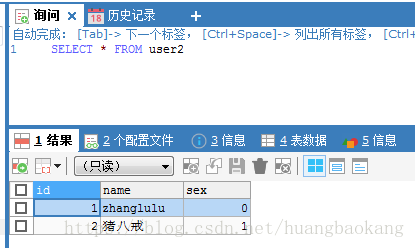

插入到了user2表中,因为INSERT_METHOD为last,最后插入的是user2表。
业务分表实现
当一个项目数据库表设计的时候没有考虑到分表时,时间久而久之,表的数据量会非常巨大,如某某平台注册信息表。
假如我有一张用户表user,有50W条数据,现在要拆成二张表user1和user2,每张表25W条数据,
INSERT INTO user1(user1.id,user1.name,user1.sex)SELECT (user.id,user.name,user.sex)FROM user where user.id <= 250000
INSERT INTO user2(user2.id,user2.name,user2.sex)SELECT (user.id,user.name,user.sex)FROM user where user.id > 250000这样我就成功的将一张user表,分成了二个表,这个时候有一个问题,代码中的sql语句怎么办,以前是一张表,现在变成二张表了,代码改动很大,这样给程序员带来了很大的工作量,有没有好的办法解决这一点呢?办法是把以前的user表备份一下,然后删除掉,上面的操作中我建立了一个t_user表,只把这个t_user表的表名改成user就行了。但是,不是所有的mysql操作都能用的。
如:
如果你使用 alter table 来把 merge 表变为其它表类型,到底层表的映射就被丢失了。取而代之的,来自底层 myisam 表的行被复制到已更换的表中,该表随后被指定新类型。
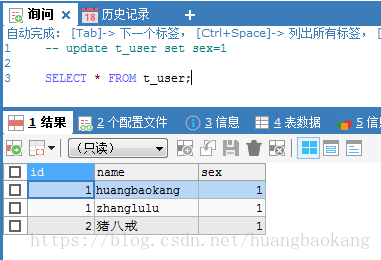
更新t_user表,看会不会影响其他表数据。执行如下:
UPDATE t_user SET sex=1再次查询,发现是可以修改存储在其他表的数据。
MYSQL利用merge存储引擎来实现分表的更多相关文章
- 利用merge存储引擎来实现分表
我觉得这种方法比较适合,那些没有事先考虑,而已经出现了得,数据查询慢的情况.这个时候如果要把已有的大数据量表分开比较痛苦,最痛苦的事就是改代码,因为程序里面的sql语句已经写好了,现在一张表要分成几十 ...
- Mysql的Merge存储引擎实现分表查询
对于数据量很大的一张表,i/o效率底下,分表势在必行! 使用程序分,对不同的查询,分配到不同的子表中,是个解决方案,但要改代码,对查询不透明. 好在mysql 有两个解决方案: Partition(分 ...
- Mysql 之 MERGE 存储引擎
MERGE 存储引擎把一组 MyISAM 数据表当做一个逻辑单元来对待,让我们可以同时对他们进行查询.构成一个 MERGE 数据表结构的各成员 MyISAM 数据表必须具有完全一样的表结构.每一个成员 ...
- MySQL MERGE存储引擎
写这篇文章,主要是因为面试的时候,面试官问我怎样统计所有的分表(假设按天分表)数据,我说了两种方案,第一种是最笨的方法,就是循环查询所有表数据(肯定不能采用):第二种方法是,利用中间件,每天定时把前一 ...
- MySQL支持多种存储引擎
MySQL的强大之处在于它的插件式存储引擎,我们可以基于表的特点使用不同的存储引擎,从而达到最好的性能. MySQL有多种存储引擎:MyISAM.InnoDB.MERGE.MEMORY(HEAP).B ...
- mysql 性能优化索引、缓存、分表、分布式实现方式。
系统针对5000台终端测试结果 索引 目标:优化查询速度3秒以内 需要优化.尽量避免使用select * 来查询对象.使用到哪些属性值就查询出哪些使用即可 首页页面: 设备-组织查询 优化 避免使用s ...
- 使用Merge存储引擎实现MySQL分表
一.使用场景 Merge表有点类似于视图.使用Merge存储引擎实现MySQL分表,这种方法比较适合那些没有事先考虑分表,随着数据的增多,已经出现了数据查询慢的情况. 这个时候如果要把已有的大数据量表 ...
- 用Merge存储引擎中间件实现MySQL分表
觉得一个用Merge存储引擎中间件来实现MySQL分表的方法不错. 可以看下这个博客写的很清楚--> http://www.cnblogs.com/xbq8080/p/6628034.html ...
- MySQL MERGE存储引擎 简介及用法
MERGE存储引擎把一组MyISAM数据表当做一个逻辑单元来对待,让我们可以同时对他们进行查询.构成一个MERGE数据表结构的各成员MyISAM数据表必须具有完全一样的结构.每一个成员数据表的数据列必 ...
随机推荐
- Typography 字体
Typography 字体 我们对字体进行统一规范,力求在各个操作系统下都有最佳展示效果. ¶中文字体 和畅惠风 PingFang SC 和畅惠风 Hiragino Sans GB 和畅惠风 Micr ...
- Linux(Debian)发行版中文输入法
Linux发行版下有两大输入法框架:ibus 和fcitx,其中fcitx 的体验要比ibus 好,因此选择 fcitx 框架,并安装中文输入法. 中文输入法中你可以选择fcitx-pinyin or ...
- neutron网络服务
一.neutron 介绍: 1. Neutron 概述 传统的网络管理方式很大程度上依赖于管理员手工配置和维护各种网络硬件设备:而云环境下的网络已经变得非常复杂,特别是在多租户场景里,用户随时都可能需 ...
- 【Deep Learning Nanodegree Foundation笔记】第 0 课:课程计划
第一周 机器学习的类型,以及何时使用机器学习 我们将首先简单介绍线性回归和机器学习.这将让你熟悉这些领域的常用术语,你需要了解的技术进展,并了解深度学习在更大的机器学习背景中的位置. 直播:线性回归 ...
- python基础--面向对象之绑定非绑定方法
# 类中定义的函数分为两大类, #一,绑定方法(绑定给谁,谁来调用就自动将它本身当做第一个参数传入) # 1,绑定到类的方法:用classmethod装饰器装饰的方法. # 对象也可以掉用,仍将类作为 ...
- AGC035 B - Even Degrees【思维·树形结构的妙用】
题目传送门 一句话题意: 首先,每一条边会产生1个入度,1个出度,因此,如果边的数量是奇数的话,图的所有节点的总出度就是奇数,不可能每个节点的出度都是偶数,因此无解. 有解时,我们先找出原图中的一棵生 ...
- python的并发GIL 了解
gil 又称 global interpreter lock (全局解释器锁) #python 中一个线程对应于c语言中的一个线程 #gil使得同一个时刻只有一个线程在一个cpu上执行字节码,无法将 ...
- Oracle中的=:
dept_code=:dCode =:在这里的意思是变量绑定
- [ASP.NET] [JS] GridView点击高亮当前选择行,并在点击另一行时恢复上一选择行背景颜色
在ASP.NET中的gridview控件里面可以通过设定其OnRowDataBound事件来进行实现高亮当前行的操作 前端控件的设置: 只要设置好OnRowDataBound属性即可,会自动在.cs文 ...
- HDU 1003 Max Sum (动态规划 最大区间和)
Max Sum Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Sub ...