MYSQL利用merge存储引擎来实现分表
创建user1和user2两个分表
建表语句如下:只是表名不一样,其他字段信息及主键一致。
CREATE TABLE IF NOT EXISTS user1(
id INT(11) NOT NULL AUTO_INCREMENT,
NAME VARCHAR(50) DEFAULT NULL,
sex INT(1) NOT NULL DEFAULT '0',
PRIMARY KEY (id)
)ENGINE=MYISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1;CREATE TABLE IF NOT EXISTS user2(
id INT(11) NOT NULL AUTO_INCREMENT,
NAME VARCHAR(50) DEFAULT NULL,
sex INT(1) NOT NULL DEFAULT '0',
PRIMARY KEY (id)
)ENGINE=MYISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1;加入测试数据:
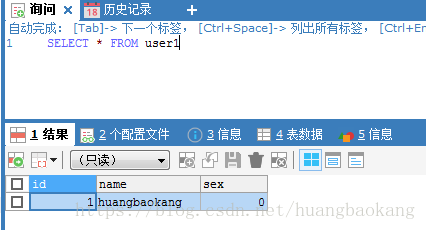
INSERT INTO user1(NAME,sex) VALUES('huangbaokang',0)
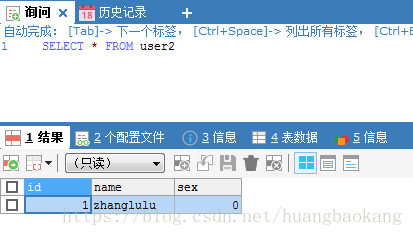
INSERT INTO user2(NAME,sex) VALUES('zhanglulu',0)创建总表:
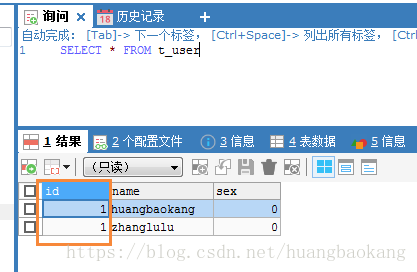
CREATE TABLE IF NOT EXISTS t_user (
id INT(11) NOT NULL AUTO_INCREMENT,
name VARCHAR(50) DEFAULT NULL,
sex INT(1) NOT NULL DEFAULT '0',
INDEX(id)
) ENGINE = MRG_MYISAM UNION =(user1,user2) INSERT_METHOD LAST CHARSET UTF8;采用merge类型,insert_method为last
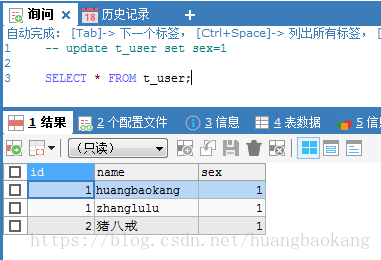
查询结果如下:
往t_user表中插入一条数据:
INSERT INTO t_user(NAME,sex) VALUES('猪八戒',1);- 1
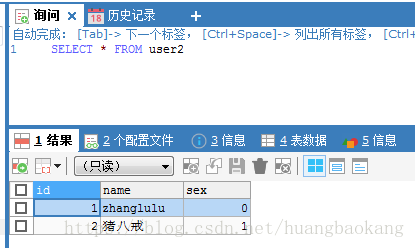

插入到了user2表中,因为INSERT_METHOD为last,最后插入的是user2表。
业务分表实现
当一个项目数据库表设计的时候没有考虑到分表时,时间久而久之,表的数据量会非常巨大,如某某平台注册信息表。
假如我有一张用户表user,有50W条数据,现在要拆成二张表user1和user2,每张表25W条数据,
INSERT INTO user1(user1.id,user1.name,user1.sex)SELECT (user.id,user.name,user.sex)FROM user where user.id <= 250000
INSERT INTO user2(user2.id,user2.name,user2.sex)SELECT (user.id,user.name,user.sex)FROM user where user.id > 250000这样我就成功的将一张user表,分成了二个表,这个时候有一个问题,代码中的sql语句怎么办,以前是一张表,现在变成二张表了,代码改动很大,这样给程序员带来了很大的工作量,有没有好的办法解决这一点呢?办法是把以前的user表备份一下,然后删除掉,上面的操作中我建立了一个t_user表,只把这个t_user表的表名改成user就行了。但是,不是所有的mysql操作都能用的。
如:
如果你使用 alter table 来把 merge 表变为其它表类型,到底层表的映射就被丢失了。取而代之的,来自底层 myisam 表的行被复制到已更换的表中,该表随后被指定新类型。
更新t_user表,看会不会影响其他表数据。执行如下:
UPDATE t_user SET sex=1再次查询,发现是可以修改存储在其他表的数据。
MYSQL利用merge存储引擎来实现分表的更多相关文章
- 利用merge存储引擎来实现分表
我觉得这种方法比较适合,那些没有事先考虑,而已经出现了得,数据查询慢的情况.这个时候如果要把已有的大数据量表分开比较痛苦,最痛苦的事就是改代码,因为程序里面的sql语句已经写好了,现在一张表要分成几十 ...
- Mysql的Merge存储引擎实现分表查询
对于数据量很大的一张表,i/o效率底下,分表势在必行! 使用程序分,对不同的查询,分配到不同的子表中,是个解决方案,但要改代码,对查询不透明. 好在mysql 有两个解决方案: Partition(分 ...
- Mysql 之 MERGE 存储引擎
MERGE 存储引擎把一组 MyISAM 数据表当做一个逻辑单元来对待,让我们可以同时对他们进行查询.构成一个 MERGE 数据表结构的各成员 MyISAM 数据表必须具有完全一样的表结构.每一个成员 ...
- MySQL MERGE存储引擎
写这篇文章,主要是因为面试的时候,面试官问我怎样统计所有的分表(假设按天分表)数据,我说了两种方案,第一种是最笨的方法,就是循环查询所有表数据(肯定不能采用):第二种方法是,利用中间件,每天定时把前一 ...
- MySQL支持多种存储引擎
MySQL的强大之处在于它的插件式存储引擎,我们可以基于表的特点使用不同的存储引擎,从而达到最好的性能. MySQL有多种存储引擎:MyISAM.InnoDB.MERGE.MEMORY(HEAP).B ...
- mysql 性能优化索引、缓存、分表、分布式实现方式。
系统针对5000台终端测试结果 索引 目标:优化查询速度3秒以内 需要优化.尽量避免使用select * 来查询对象.使用到哪些属性值就查询出哪些使用即可 首页页面: 设备-组织查询 优化 避免使用s ...
- 使用Merge存储引擎实现MySQL分表
一.使用场景 Merge表有点类似于视图.使用Merge存储引擎实现MySQL分表,这种方法比较适合那些没有事先考虑分表,随着数据的增多,已经出现了数据查询慢的情况. 这个时候如果要把已有的大数据量表 ...
- 用Merge存储引擎中间件实现MySQL分表
觉得一个用Merge存储引擎中间件来实现MySQL分表的方法不错. 可以看下这个博客写的很清楚--> http://www.cnblogs.com/xbq8080/p/6628034.html ...
- MySQL MERGE存储引擎 简介及用法
MERGE存储引擎把一组MyISAM数据表当做一个逻辑单元来对待,让我们可以同时对他们进行查询.构成一个MERGE数据表结构的各成员MyISAM数据表必须具有完全一样的结构.每一个成员数据表的数据列必 ...
随机推荐
- linux 下载jdk 、maven、git
jdk: wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-secureback ...
- Elasticsearch 6.2.3版本 Windows环境 简单操作
背景描述 Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎.无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进.性能最好的.功能最全的搜索引擎库. El ...
- oracle数据字典视图
数据字典的概念 还记得我们在手工建库的时候,运行的两个脚本文件.一个是catalog.sql,另一个是catproc.sql.catalog.sql是用来创建数据库的内部字典表的.catp ...
- java:maven(maven-ssm(聚合,分包开发))
1.maven-ssm: maven-ssm_diy: pom.xml: <?xml version="1.0" encoding="UTF-8"?> ...
- java:Maven(Maven_ssm)
1.maven_ssm: DOS命令向maven仓库导入jar包: mvn install:install-file -Dfile=F:\jars\json-lib-2.4-jdk15.jar -Dg ...
- WinForm和WPF中注册热键
由于.Net没有提供专门的类库处理热键,所以需要直接调用windows API来解决. HotKey为.NET调用Windows API的封装代码,主要是RegisterHotKey和Unregist ...
- 实现 laravel 的artisan
laravel 的 artisan 命令行太好用了,换个框架没有这个功能,于是自己学习实现一些,直接上代码 新建目录 -artisan --bin --src 进入artisan composer i ...
- USACO1.5 Mother's Milk【搜索】
题目传送门 这道题还记得是我当年学广搜的时候做过. 如今再做,做了一个$dfs$版本的,比较简单,直接搞就可以了. 广搜的话,用结构体保存,然后塞到$queue$里面就可以了. /* ID: Star ...
- 第五周总结&实验·
本周总结 1.final声明的变量即成为常量,常量不可以修改. 2.子类能够 ...
- Neo4j下载与使用
Neo4j 官网 : https://neo4j.com/ Neo4j 国内: http://neo4j.com.cn/topic/5b003eae9662eee704f31cee http://we ...