四十二:数据库之SQLAlchemy之数据查询懒加载技术
懒加载
在一对多,或者多对多的时候,如果要获取多的这一部分的数据的时候,通过一个relationship定义好对应关系就可以全部获取,此时获取到的数据是list,但是有时候不想获取全部数据,如果要进行数据筛选就需要遍历筛选,就比较麻烦,可以从查询返回值里面入手,比如在获取到的数据里面还要加个过滤条件,则需要在relationship中加一个参数:lazy='dynamic',以后通过relationship定义的对应关系获取到的就不是一个列表,而是一个AppenderQuery对象,这种对象既可以添加新数据,也可以跟Query对象一样对数据进行二次过滤
准备工作
from datetime import datetime from sqlalchemy import create_engine, Column, Integer, String, Float, Text, ForeignKey, DateTime
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship, backref # 数据库信息
host = '127.0.0.1'
port = '3306'
database = 'db_to_sqlalchemy'
username = 'root'
password = '123456' # 数据库类型+连接数据库的插件,这里使用的pymysql
DB_URI = f'mysql+pymysql://{username}:{password}@{host}:{port}/{database}' engine = create_engine(DB_URI) # 创建引擎
Base = declarative_base(engine) # 使用declarative_base创建基类
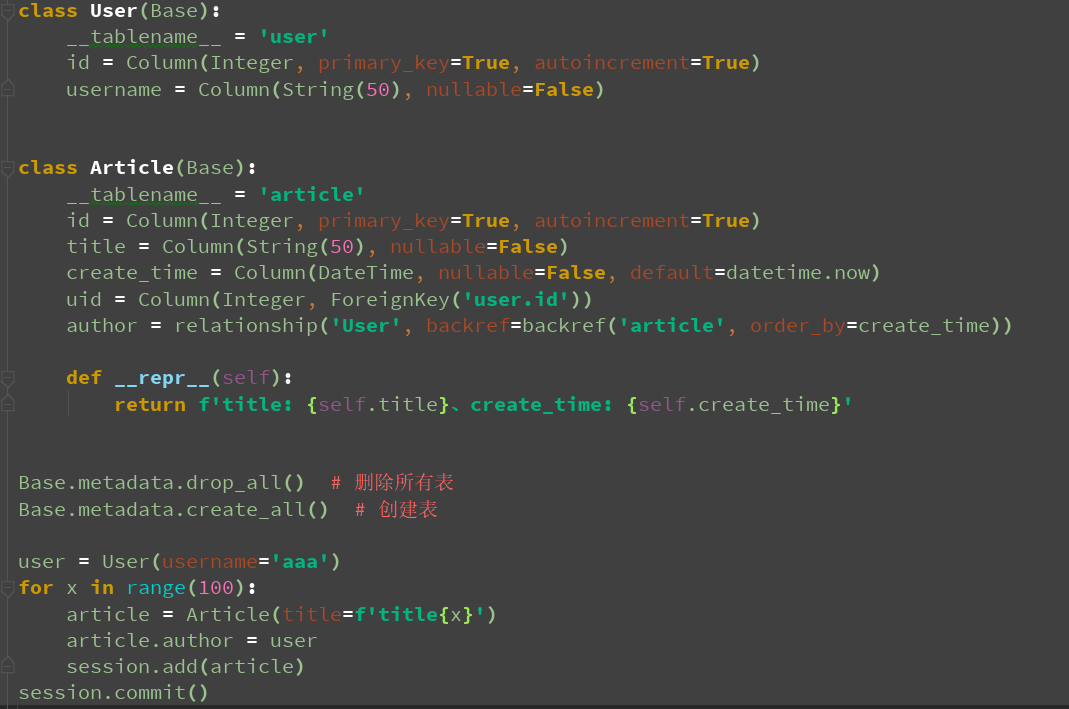
session = sessionmaker(engine)() class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False) class Article(Base):
__tablename__ = 'article'
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
create_time = Column(DateTime, nullable=False, default=datetime.now)
uid = Column(Integer, ForeignKey('user.id'))
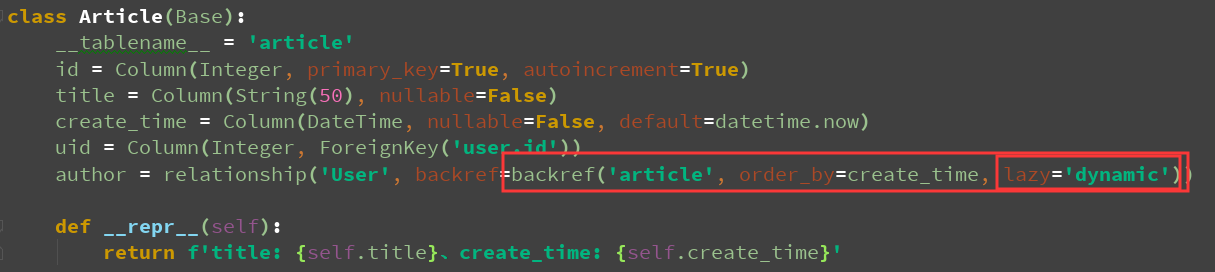
author = relationship('User', backref=backref('article', order_by=create_time)) def __repr__(self):
return f'title: {self.title}、create_time: {self.create_time}' Base.metadata.drop_all() # 删除所有表
Base.metadata.create_all() # 创建表 user = User(username='aaa')
for x in range(100):
article = Article(title=f'title{x}')
article.author = user
session.add(article)
session.commit()
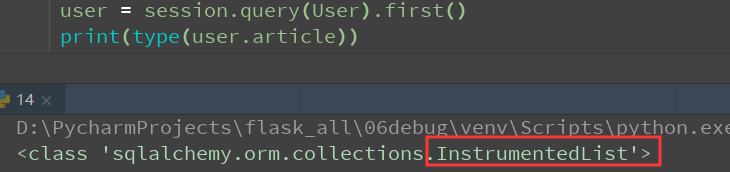
默认返回的是list对象
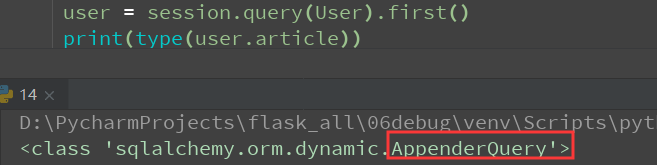
指定懒加载属性lazy='dynamic'
返回的是AppendQuery对象
导入看源码


以上可以看出,返回的对象会有AppendQuery和Query的全部特性,即可以使用Query的方法进行数据二次过滤
如,查user表第一条数据对应在article表里面所有数据的id大于95的数据

有AppendQuery特性,也就是说可以添加数据

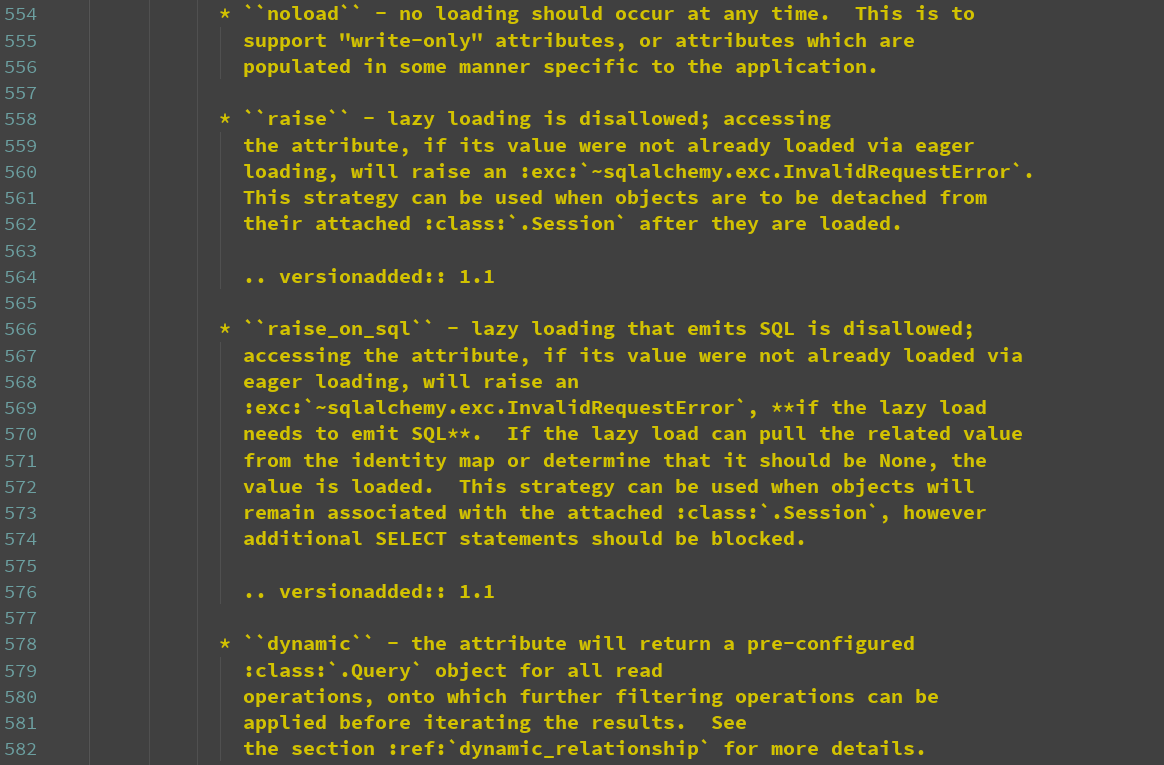
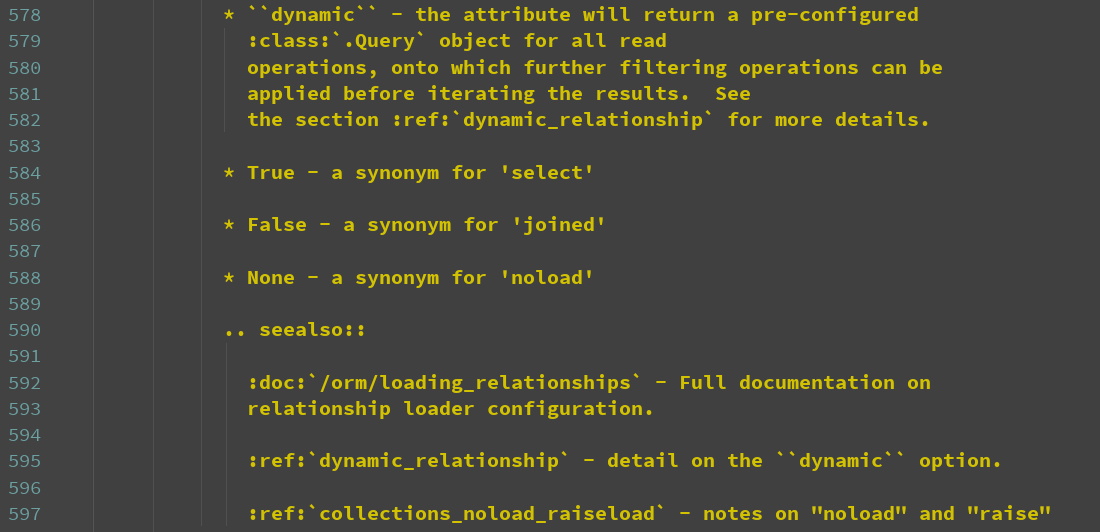
lazy支持的参数
首先,默认的是select

支持的参数
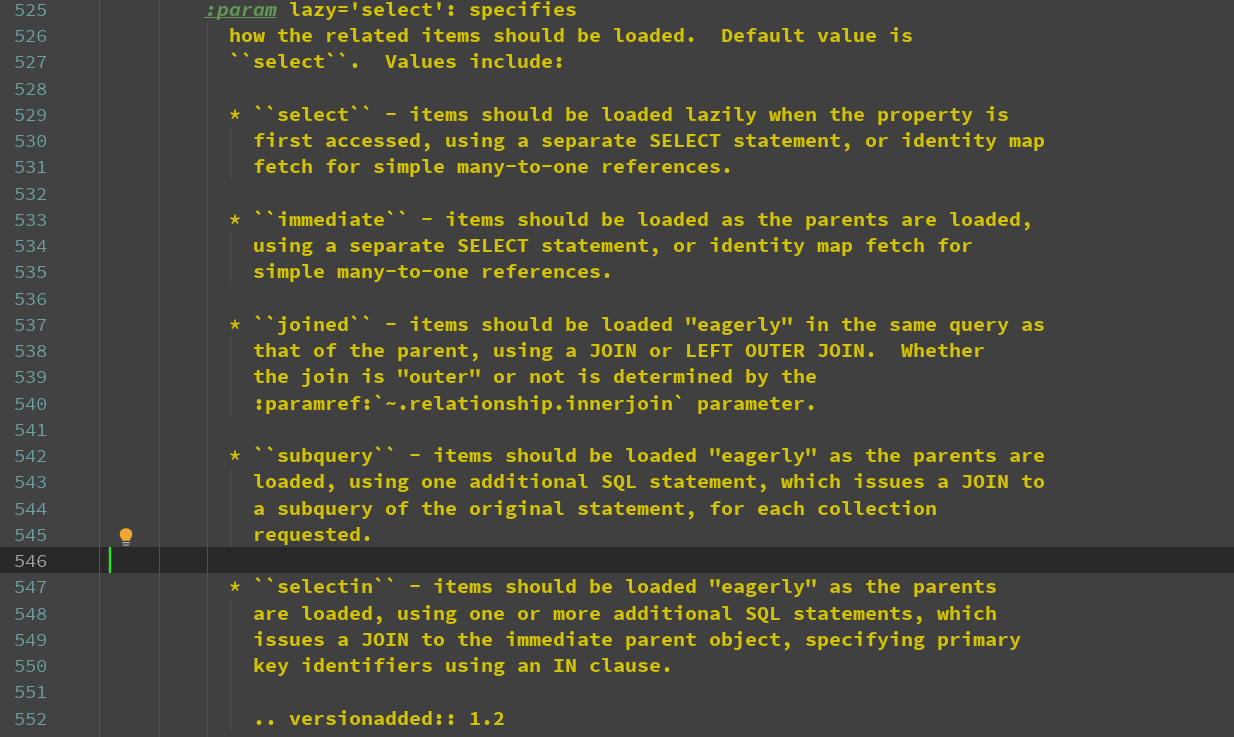
select:如果没有调relationship对应的字段,则不会获取多的这一边的数据,一旦调用此属性,则获取所有对应的数据,返回列表
immediate:不管是否调用relationship对应的字段,都会则获取所有对应的数据,返回列表
joined:将relationship对应的字段查找回来的数据,通过join的方式加到主表数据中
subquery:子查询的方式
四十二:数据库之SQLAlchemy之数据查询懒加载技术的更多相关文章
- vue 中监测滚动条加载数据(懒加载数据)
vue 中监测滚动条加载数据(懒加载数据) 1:钩子函数监听滚动事件: mounted () { this.$nextTick(function () { window.addEventListene ...
- 数据解析,懒加载,代理ip
在前面的requests流程中,还缺少了一步重要的流程,就是在持久化存储之前需要进行制定的数据解析.因为在大多数情况下,我们都会使用聚焦爬虫,也就是爬取页面中的指定部分数据值,而不是整个页面的数据. ...
- 潭州课堂25班:Ph201805201 django 项目 第二十二课 文章主页 新闻列表页面滚动加载,轮播图后台实现 (课堂笔记)
新建static/js/news/index.js文件 ,主要用于向后台发送请求, // 新建static/js/news/index.js文件 $(function () { // 新闻列表功能 l ...
- Java Selenium (十二) 操作弹出窗口 & 智能等待页面加载完成 & 处理 Iframe 中的元素
一.操作弹出窗口 原理 在代码里, 通过 Set<String> allWindowsId = driver.getWindowHandles(); 来获取到所有弹出浏览器的句柄, 然 ...
- 四十:数据库之SQLAlchemy实现排序的三种方式
SQLAlchemy实现排序有三种方式一:order_by:查询的时候使用此方式根据某个字段或模型下的属性进行排序二:模型定义的时候,指定排序方式三:一对多的时候,relationship的order ...
- Android笔记(四十二) Android中的数据存储——SQLite(四)update
update方法的四个参数: update()方法参数 对应的sql部分 描述 table update table_name 更新的表名 values set column=xxx ContentV ...
- Unity3D学习笔记(十二):2D模式和异步资源加载
2D模式和3D模式区别:背景纯色,摄像机2D,没有深度轴 精灵图片设置 Normal map,法线贴图,更有立体感 Sprite (2D and UI),2D精灵贴图,有两种用途 1.当做UI贴图 2 ...
- JPA数据懒加载LAZY配合事务@Transactional使用(三)
上篇博文<JPA数据懒加载LAZY和实时加载EAGER(二)>讲到,如果使用懒加载来调用关联数据,必须要保证主查询session(数据库连接会话)的生命周期没有结束,否则,你是无法抽取到数 ...
- DataTable 删除数据后重新加载
DataTable 删除数据后重新加载 一.总结 一句话总结: 判断datatable是否被datatable初始化或者是否执行了datatable销毁函数,如果没有,就销毁它 if ($('#dat ...
随机推荐
- 2019/9/18 IIS服务器 ftp站安装:隔离模式
net user ftp1 /add 添加两个账户 在d盘下创建ftp站的文件夹ftptest,进入文件夹,创建文件夹LocalUser,进入LocalUser 分别创建administrator ...
- NB-IOT双工模式
半双工(Half Duplex)数据传输指数据可以在一个信号载体的两个方向上传输,但是不能同时传输.例如,在一个局域网上使用具有半双工传输的技术,一个工作站可以在线上发送数据,然后立即在线上接收数据, ...
- c++ 数组 结构体
接下来的一点时间我将会记录下我看的c++的一些心得体会,人贵在坚持,希望我可以一直坚持下去!!Go Fighting! 一.c++复合数据类型: 数组类型的一些注意事项: sizeof的用法: 当 ...
- WEB 服务应用 Nginx之安装篇
一.Nginx 源码包安装与配置 1.环境准备 操作系统.内核版本: CentOS 6.8 2.6.32-642.el6.x86_64 Nginx 软件版本: nginx-1.10.2 2.创建Ng ...
- php多个数组组合算法 火车头免登录发布接口代码备忘
火车头发布产品的时候,有颜色.尺码.性别等等产品属性,需要进行不重复的组合,变成不重复的数组 <?php function comb($a){ $a = array_filter($a); $o ...
- GO (待更新)
日期20190531,GO AND TOOLS FOR HOME 0 环境搭建 https://golang.org/dl/ Install the Go tools If you are upgr ...
- 使用RedisTemplate的操作类访问Redis(转载)
原文地址:http://www.cnblogs.com/luochengqiuse/p/4641256.html private ValueOperations<K, V> valueOp ...
- python 单元测试_读写Excel及配置文件(八)
一.安装openpyxl模块 openpyxl模块:是用于解决Excel(WPS等均可使用)中扩展名为xlsx/xlsm/xltx/xltm的文件读写的第三方库.xls文件要使用xlwt .wlrd两 ...
- 关于css阴影和浮动
盒子阴影box-shadow box-shadow:0 0 1px #000 inset; 水平 垂直 模糊 颜色 : [1] inset代表框内阴影,不加inset代表框外阴影 [2]第1个 ...
- WTL自定义控件:需要的头文件
这两天自定义了一个Edit控件,继承自CEdit,如下: class CCheckEditEx : public CWindowImpl< CCheckEditEx, CEdit > 需要 ...