CentOS7搭建Hadoop2.8.0集群及基础操作与测试
环境说明
|
示例环境 |
|||||
|
主机名 |
IP |
角色 |
系统版本 |
数据目录 |
Hadoop版本 |
|
master |
192.168.174.200 |
nameNode |
CentOS Linux release 7.4.1708 (Core) |
2.8.0 |
|
|
slave1 |
192.168.129.201 |
dataNode |
CentOS Linux release 7.4.1708 (Core) |
2.8.0 |
|
准备工作
JDK安装
确认本机安装的JDK版本为1.7以上,建议为1.8.
查看本机安装JDK
rpm -e --nodeps 'rpm -qa | grep java'如:安装过其他版本的JDK,移除原JDK
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.131-11.b12.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.141-2.6.10.5.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.141-2.6.10.5.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.131-11.b12.el7.x86_64下载JDK
curl -O http://download.oracle.com/otn-pub/java/jdk/8u161-b12/2f38c3b165be4555a1fa6e98c45e0808/jdk-8u161-linux-x64.tar.gz?AuthParam=1520556529_7efdd22074a16eff52be3c1e15843903解压
tar -zxvf jdk-8u161-linux-x64.tar.gz配置环境变量
gedit ~/.bashrc或
vim ~/.bashrc配置添加如下图:

立即生效
source ~/.bashrc修改本机信息
修改主机名(分别在两台虚拟机修改为:master、slave1、..):
vi /etc/hostname增加IP与主机映射:
vi /etc/hosts
#增加以下内容:
192.168.174.200 master
192.168.174.201 slave1SSH免密码登录
打开终端执行如下命令进行检验
rpm -qa | grep ssh如果返回的结果如下图所示,包含了 SSH client 跟 SSH server,则不需要再安装。

若需要安装,则可以通过 yum 进行安装(安装过程中会让你输入 [y/N],输入 y 即可):
yum install openssh-clients
yum install openssh-server设置免登录
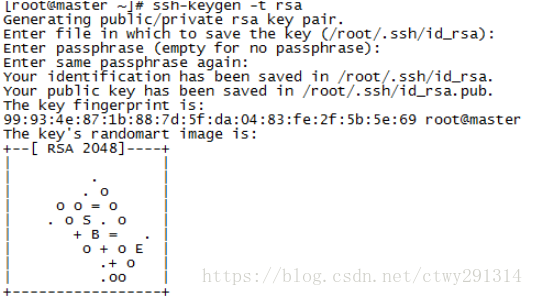
主节点
ssh localhost
查看用户主目录.ssh文件夹下
cd .ssh/
ssh-keygen -t rsa#连续回车,系统自动生成图形公钥
#将生成的公钥id_rsa.pub 内容追加到authorized_keys
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
从节点
ssh localhost
查看用户主目录.ssh文件夹下
cd .ssh/
ssh-keygen -t rsa#连续回车,系统自动生成图形公钥
#将从节点的id_rsa.pub复制到主节点并改名为id_rsa.pub.s1
scp id_rsa.pub master:/root/.ssh/id_rsa.pub.s1
主节点
#将从节点的id_rsa.pub.s1公钥追加到主节点的authorized_keys中
cat id_rsa.pub.s1 >> authorized_keys
#将生成的包含从节点的秘钥的authorized_keys 复制到从节点的.ssh目录下
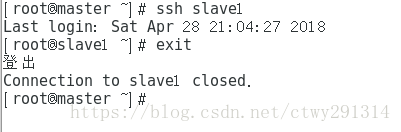
scp authorized_keys slave1:/root/.ssh/验证ssh的免密码登录:
在master中输入:ssh slave1是否需要密码,如果不需要,则ssh免密码配置成功。
安装ZooKeeper
wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz解压
tar -zxvf zookeeper-3.4.10.tar.gz移动文件夹
mv zookeeper-3.4.10 /usr/local/haddop修改配置
cd /usr/local/hadoop/zookeeper-3.4.10/conf
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg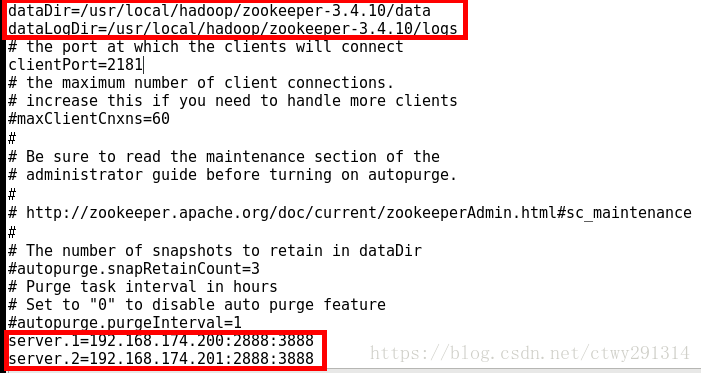
复制到从机
scp zookeeper-3.4.10 slave1:/usr/local/hadoop/根据dataDir进行X的配置(主从机均执行)
cd /usr/local/hadoop/zookeeper-3.4.10
mkdir data
cd data
vim myid
#之后会产生一个新文件,直接在里面写 X 即可
#比如我配置的三个server,myid里面写的X就是server.X=ip:2888:3888 中ip所对应的X
server.1=192.168.174.200:2888:3888【192.168.174.200服务器上面的myid填写1】
server.2=192.168.174.201:2888:3888【192.168.174.201服务器上面的myid填写2】启动(主从均执行)
cd /usr/local/hadoop/zookeeper-3.4.10/bin
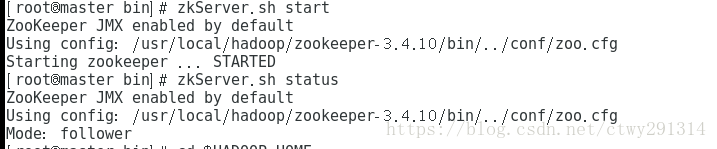
zkServer.sh start检查状态
zkServer.sh status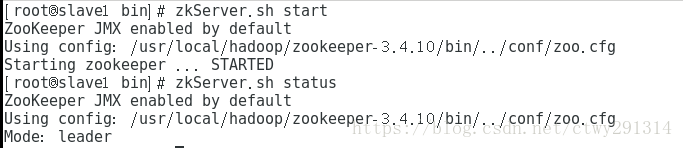
Hadoop安装及配置
下载
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz解压
tar -zxvf hadoop-2.8.0.tar.gz移动文件夹
mv hadoop-2.8.0 /usr/local/haddop配置环境变量
参照上节JDK安装配置环境变量
修改配置文件
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop/core-site.xml文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/data/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>修改hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/hdfs/nn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/data/hadoop/hdfs/snn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:/data/hadoop/hdfs/snn</value>
</property>
<property>
<name>fs.datanode.data.dir</name>
<value>file:/data/hadoop/hdfs/dn</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>新建并且修改mapred-site.xml
在该版本中,有一个名为mapred-site.xml.template的文件,复制该文件,然后改名为mapred-site.xml,命令是:
cp /usr/local/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>修改slaves文件
修改/usr/local/hadoop/hadoop-2.8.0/etc/hadoop/slaves文件,将里面的localhost删除,添加如下内容:
slave1修改yarn-site.xml文件
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop/yarn-site.xml文件,
在<configuration>节点内加入配置(注意了,内存根据机器配置越大越好,我这里只配2个G是因为机器不行):
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8090</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:/data/hadoop/yarn/nm</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>说明:yarn.nodemanager.vmem-check-enabled这个的意思是忽略虚拟内存的检查,如果你是安装在虚拟机上,这个配置很有用,配上去之后后续操作不容易出问题。如果是实体机上,并且内存够多,可以将这个配置去掉。
启动hadoop
在namenode上执行初始化
因为master是slave1是datanode,所以只需要对master进行初始化操作,也就是对hdfs进行格式化
cd /user/local/hadoop/hadoop-2.8.0/bin执行初始化脚本,也就是执行命令:
./hadoop namenode -format关闭防火墙,CentOS7下,命令:
systemctl stop firewalld.service启动Hadoop集群
sbin/start-all.sh启动后,master上进程和slave进程列表
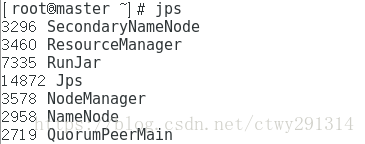

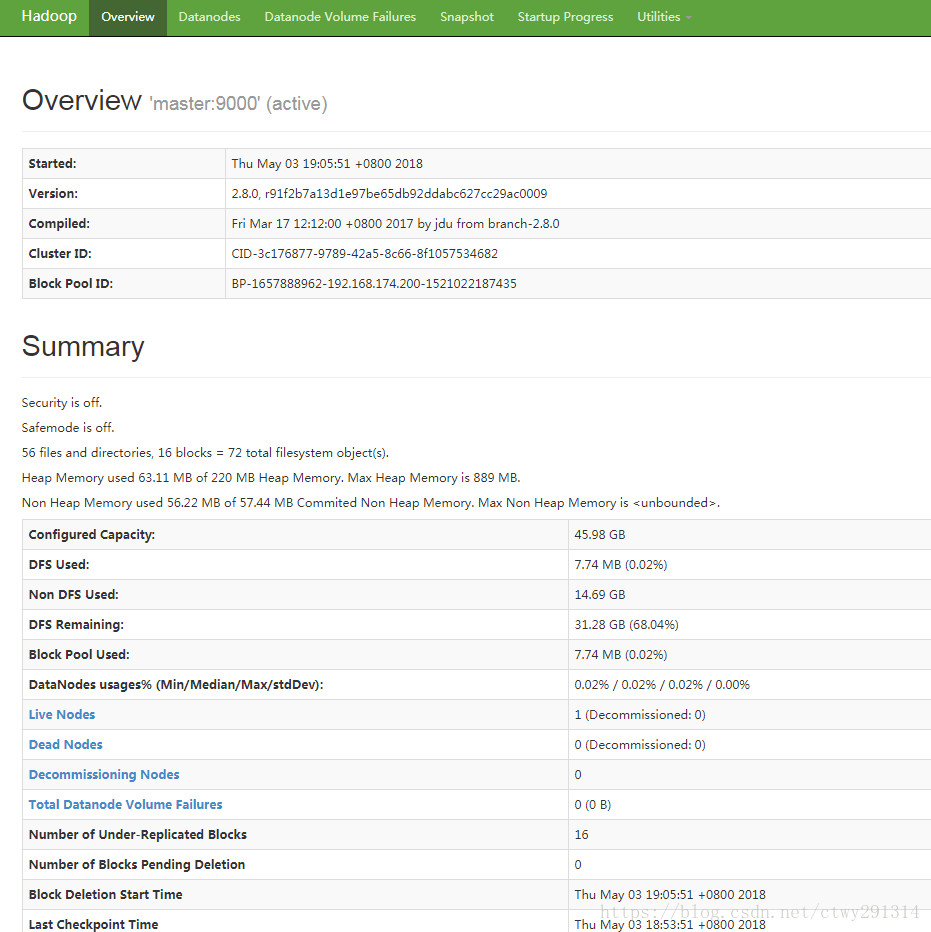

至此Hadoop集群搭建完毕
CentOS7搭建Hadoop2.8.0集群及基础操作与测试的更多相关文章
- CentOS6.4上搭建hadoop-2.4.0集群
公司Commerce Cloud平台上提供申请主机的服务.昨天试了下,申请了3台机器,搭了个hadoop环境.以下是机器的一些配置: emi-centos-6.4-x86_64medium | 6GB ...
- ubuntu14.04搭建Hadoop2.9.0集群(分布式)环境
本文进行操作的虚拟机是在伪分布式配置的基础上进行的,具体配置本文不再赘述,请参考本人博文:ubuntu14.04搭建Hadoop2.9.0伪分布式环境 本文主要参考 给力星的博文——Hadoop集群安 ...
- CentOS7搭建Hadoop-3.3.0集群手记
前提 这篇文章是基于Linux系统CentOS7搭建Hadoop-3.3.0分布式集群的详细手记. 基本概念 Hadoop中的HDFS和YARN都是主从架构,主从架构会有一主多从和多主多从两种架构,这 ...
- 在CentOS7下搭建Hadoop2.9.0集群
系统环境:CentOS 7 JDK版本:jdk-8u191-linux-x64 MYSQL版本:5.7.26 Hadoop版本:2.9.0 Hive版本:2.3.4 Host Name Ip User ...
- 第八章 搭建hadoop2.2.0集群,Zookeeper集群和hbase-0.98.0-hadoop2-bin.tar.gz集群
安装配置jdk,SSH 一.首先,先搭建三台小集群,虚拟机的话,创建三个 下面为这三台机器分别分配IP地址及相应的角色:集群有个特点,三台机子用户名最好一致,要不你就创建一个组,把这些用户放到组里面去 ...
- 搭建hadoop2.6.0集群环境
一.规划 (一)硬件资源 10.171.29.191 master 10.171.94.155 slave1 10.251.0.197 slave3 (二)基本资料 用户: jediael 目录: ...
- 搭建hadoop2.6.0集群环境 分类: A1_HADOOP 2015-04-20 07:21 459人阅读 评论(0) 收藏
一.规划 (一)硬件资源 10.171.29.191 master 10.171.94.155 slave1 10.251.0.197 slave3 (二)基本资料 用户: jediael 目录: ...
- Linux基于Hadoop2.8.0集群安装配置Hive2.1.1及基础操作
前言 安装Apache Hive前提是要先安装hadoop集群,并且hive只需要在hadoop的namenode节点集群里安装即可,安装前需保证Hadoop已启(动文中用到了hadoop的hdfs命 ...
- 分布式Hbase-0.98.4在Hadoop-2.2.0集群上的部署
fesh个人实践,欢迎经验交流!本文Blog地址:http://www.cnblogs.com/fesh/p/3898991.html Hbase 是Apache Hadoop的数据库,能够对大数据提 ...
随机推荐
- 求大师点化,寻求大文件(最大20G左右)上传方案
之前仿造uploadify写了一个HTML5版的文件上传插件,没看过的朋友可以点此先看一下~得到了不少朋友的好评,我自己也用在了项目中,不论是用户头像上传,还是各种媒体文件的上传,以及各种个性的业务需 ...
- JSP上传整个文件夹
文件上传是最古老的互联网操作之一,20多年来几乎没有怎么变化,还是操作麻烦.缺乏交互.用户体验差. 一.前端代码 英国程序员Remy Sharp总结了这些新的接口 ,本文在他的基础之上,讨论在前端采用 ...
- Java——类
[类]
- open 函数处理文件
open函数用于文件处理 操作文件时,一般需要经历如下步骤:1 打开文件 2 操作文件 f = open("文件名" , ' 打开文件方式' ) 文件句柄 ...
- flask的请求上下文request对象
Flask从客户端收到请求时,要让视图函数能访问请求对象request ,才能处理请求.我们可以将request对象作为参数传到试图函数里,比如: from flask import Flask, r ...
- springBoot项目常用maven依赖以及依赖说明
springBoot项目常用maven依赖以及依赖说明 1:maven-compiler-plugin <build> <plugins> <!-- 指定maven编译的 ...
- 用Vue来实现音乐播放器(十六):滚动列表的实现
滚动列表是一个基础组件 他是基于scroll组件实现的 在base文件夹下面创建一个list-view文件夹 里面有list-view.vue组件 <template> < ...
- 使用Dockerfile封装Django镜像
第一步: 在/opt下建立了docker目录,下载一个django-2.1.7的源码包, touch Dockerfile和run.sh,其中run.sh是用来执行Django的bash脚本,Dock ...
- 阶段1 语言基础+高级_1-3-Java语言高级_05-异常与多线程_第5节 线程池_1_线程池的概念和原理
线程的底层原理 集合有很多种,线程池的集合用LinkedList最好
- window.open弹窗阻止问题解决之道
https://segmentfault.com/a/1190000015381923https://segmentfault.com/a/1190000014988094https://www.cn ...