搭建hadoop集群 单机版
二、在Ubuntu下创建hadoop用户组和用户
1、创建hadoop用户组
- sudo su //进入管理员root用户
- sudo addgroup hadoop
2、创建hadoop用户
- sudo adduser –ingroup hadoop hadoop
3、给hadoop用户添加权限,打开/etc/sudoers文件
- sudo gedit /etc/sudoers
三、在Ubuntu下安装JDK
- 由于下面使用的是hadoop2.7.3,所以此处至少安装JDK1.7
- 记得先切换成hadoop用户
在Ubuntu下安装JDK图文解析 : http://blog.csdn.net/chongxin1/article/details/68957808
四、修改机器名
1、打开/etc/hostname文件
- sudo su
- sudo gedit /etc/hostname
2、将/etc/hostname文件中的yangcx-virtual-machine改为你想取的机器名
- sudo gedit /etc/hosts
为了后面在windows系统中调用linux系统的hadoop服务,所以应该把127.0.0.1修改为实际IP地址,如:192.168.168.200
五、安装ssh服务
此处采用在线安装方法,所以首先要保证Ubuntu系统能够上网。
VMware Ubuntu如何连接互联网: http://blog.csdn.net/chongxin1/article/details/68959150
1、更新源列表
- sudo apt-get update
2、安装ssh
- sudo apt-get install openssh-server
3、查看ssh服务是否启动
- sudo ps -e |grep ssh
六、建立ssh无密码登录本机
1、创建ssh-key,,这里我们采用rsa方式
- ssh-keygen -t rsa -P "" //(P是要大写的,后面跟"")
2、进入~/.ssh/目录下,将id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的
- cd ~/.ssh
- cat id_rsa.pub >> authorized_keys
3、登录localhost
- ssh localhost
4、执行退出命令
- exit
七、下载hadoop
hadoop百度网盘下载地址:http://pan.baidu.com/s/1pKQsHJ1
官网下载地址:http://hadoop.apache.org/
下载步骤一:
找到"Getting Started" ----->"Download Hadoop from the release page"
下载步骤二:
找到"Download the release hadoop-X.Y.Z-src.tar.gz from a mirror site
下载步骤三:
下载步骤四:
八、安装Hadoop
1、假设hadoop-2.7.3.tar.gz在桌面,将它复制到安装目录 /usr/local/下1
- sudo cp hadoop-2.7.3.tar.gz /usr/local
2、解压hadoop-2.7.3.tar.gz
- cd /usr/local/
- sudo tar -zxf hadoop-2.7.3.tar.gz
3、将解压出的文件夹改名为hadoop
- sudo mv hadoop-2.7.3 hadoop
4、将该hadoop文件夹的属主用户设为hadoop
- sudo chown -R hadoop:hadoop hadoop
5、打开hadoop/etc/hadoop/hadoop-env.sh文件
- cd hadoop/etc/hadoop
- sudo gedit hadoop-env.sh
6、配置hadoop/etc/hadoop/hadoop-env.sh(找到#export JAVA_HOME=...,去掉,然后加上本机jdk的路径)
把 ${JAVA_HOME} 修改为本机JDK实际的路径
7、打开hadoop/etc/hadoop/core-site.xml文件,编辑如下:
- sudo gedit core-site.xml
- <property>
- <name>fs.default.name</name>
- <value>hdfs://192.168.168.200:9000</value>
- </property>
192.168.168.200 : 本机IP地址,此处不用localhost,为了在windows能够访问
9000:默认端口
8、打开hadoop/etc/hadoop/mapred-site.xml文件,编辑如下:
- //复制并重命名
- cp mapred-site.xml.template mapred-site.xml
- //编辑器打开此新建文件
- sudo gedit mapred-site.xml
- <configuration>
- <property>
- <name>mapred.job.tracker</name>
- <value>localhost:9001</value>
- </property>
- </configuration>
9、打开hadoop/etc/hadoop/hdfs-site.xml文件,编辑如下:
- sudo gedit hdfs-site.xml
- <configuration>
- <property>
- <name>dfs.name.dir</name>
- <value>/usr/local/hadoop/namenode</value>
- </property>
- <property>
- <name>dfs.data.dir</name>
- <value>/usr/local/hadoop/datanode</value>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- </configuration>
九、在单机上运行hadoop
1、格式化hdfs文件系统
- cd /usr/local/hadoop
- bin/hadoop namenode -format
2、启动hdfs
- cd /usr/local/hadoop
- ./sbin/start-dfs.sh
- jps
3、快捷启动配置
- //配置hadoop环境变量
- sudo gedit /etc/profile
- export HADOOP_HOME=/usr/local/hadoop
- export PATH="$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH"
- export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
之后即可直接调用start-dfs.sh启动hadoop,无需进入hadoop的安装目录。
4、停止hdfs
- ./sbin/stop-dfs.sh
十、测试hadoop是否安装成功
1、测试用浏览器访问: http://localhost:50070 或者 http://192.168.168.200:50070
2、上传文件测试
- Hello World
- Hello Tom
- Hello Jack
- Hello Hadoop
- Bye hadoop
- bin/hadoop fs -put words.txt /
3、配置启动YARN
①配置etc/hadoop/mapred-site.xml:
- mv mapred-site.xml.template mapred-site.xml
- <configuration>
- <!-- 通知框架MR使用YARN -->
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- </configuration>
②配置etc/hadoop/yarn-site.xml:
- <configuration>
- <!-- reducer取数据的方式是mapreduce_shuffle -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- </configuration>
③YARN的启动与停止
- //启动
- ./sbin/start-yarn.sh
- 停止
- ./sbin/stop-yarn.sh
4、运行一个简单的MP程序
- ./bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
- wordcount hdfs://localhost:9000/words.txt hdfs://localhost:9000/out
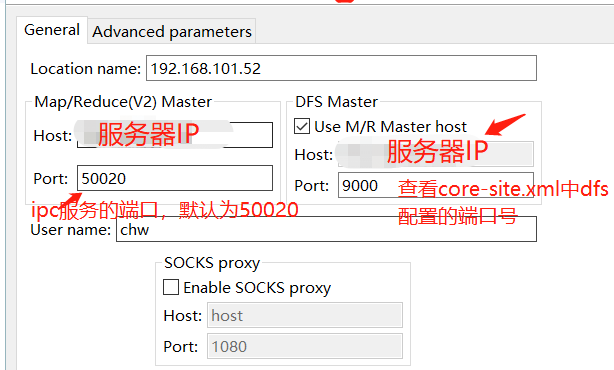 Username随意写
Username随意写添加
firewall-cmd --zone=public --add-port=80/tcp --permanent (--permanent永久生效,没有此参数重启后失效)
重新载入
firewall-cmd --reload
查看
firewall-cmd --zone=public --query-port=80/tcp
删除
firewall-cmd --zone=public --remove-port=80/tcp --permanent
搭建hadoop集群 单机版的更多相关文章
- Linux下搭建Hadoop集群
本文地址: 1.前言 本文描述的是如何使用3台Hadoop节点搭建一个集群.本文中,使用的是三个Ubuntu虚拟机,并没有使用三台物理机.在使用物理机搭建Hadoop集群的时候,也可以参考本文.首先这 ...
- 使用Windows Azure的VM安装和配置CDH搭建Hadoop集群
本文主要内容是使用Windows Azure的VIRTUAL MACHINES和NETWORKS服务安装CDH (Cloudera Distribution Including Apache Hado ...
- virtualbox 虚拟3台虚拟机搭建hadoop集群
用了这么久的hadoop,只会使用streaming接口跑任务,各种调优还不熟练,自定义inputformat , outputformat, partitioner 还不会写,于是干脆从头开始,自己 ...
- 搭建Hadoop集群 (三)
通过 搭建Hadoop集群 (二), 我们已经可以顺利运行自带的wordcount程序. 下面学习如何创建自己的Java应用, 放到Hadoop集群上运行, 并且可以通过debug来调试. 有多少种D ...
- 搭建Hadoop集群 (一)
上面讲了如何搭建Hadoop的Standalone和Pseudo-Distributed Mode(搭建单节点Hadoop应用环境), 现在我们来搭建一个Fully-Distributed Mode的 ...
- 搭建Hadoop集群 (二)
前面的步骤请看 搭建Hadoop集群 (一) 安装Hadoop 解压安装 登录master, 下载解压hadoop 2.6.2压缩包到/home/hm/文件夹. (也可以从主机拖拽或者psftp压缩 ...
- Hadoop入门进阶步步高(五)-搭建Hadoop集群
五.搭建Hadoop集群 上面的步骤,确认了单机能够运行Hadoop的伪分布运行,真正的分布式运行无非也就是多几台slave机器而已,配置方面的有一点点差别,配置起来就很easy了. 1.准备三台se ...
- Linux 搭建Hadoop集群 成功
内容基于(自己的真是操作步骤编写) Linux 搭建Hadoop集群---Jdk配置 Linux 搭建Hadoop集群 ---SSH免密登陆 一:下载安装 Hadoop 1.1:下载指定的Hadoop ...
- 阿里云搭建hadoop集群服务器,内网、外网访问问题(详解。。。)
这个问题花费了我将近两天的时间,经过多次试错和尝试,现在想分享给大家来解决此问题避免大家入坑,以前都是在局域网上搭建的hadoop集群,并且是局域网访问的,没遇见此问题. 因为阿里云上搭建的hadoo ...
随机推荐
- js调用ios和安卓方法
安卓: window.AndroidWebView.方法名(参数); window.AndroidWebView.productDetail(1989); ios: function isbrowse ...
- 《ArcGIS Runtime SDK for .NET开发笔记》--在线编辑
介绍 ArcGIS可以发布具有编辑功能的Feature Service.利用Feature Service我们可以实现对数据的在线编辑. 数据制作参考: https://server.arcgis.c ...
- thinkphp 连接postgresql
PHP连接: php.ini中将extension=php_pgsql.dll前面的分号去掉extension=php_pdo_pgsql.dll前面的分号去掉,然后设置extension_dir指向 ...
- HTML5: HTML5 应用程序缓存
ylbtech-HTML5: HTML5 应用程序缓存 1.返回顶部 1. HTML5 应用程序缓存 使用 HTML5,通过创建 cache manifest 文件,可以轻松地创建 web 应用的离线 ...
- Java学习之抽象类
抽象类特点: 1.抽象方法必须定义在抽象类中2.abstract关键字修饰:只能修饰类和方法3.抽象类不能实例化4.抽象类中的方法要被使用,必须由子类重写所有的抽象方法,实例化其子类 如果子类只重写部 ...
- ng -v 不是内部或外部命令
输入 npm install -g @angular/cli ng new my-app 提示ng -v 不是内部或外部命令 解决方法 1.安装过程中是否出错 原因可能是npm install -g ...
- Money
/** * www.yiji.com Inc. * Copyright (c) 2012 All Rights Reserved. */package com.yjf.common.lang.util ...
- InnoDB与Myisam比较
InnoDB与Myisam比较 ...
- yum update过程中失败后再次执行出现“xxxx is a duplicate with xxxx”问题
问题现象: 解决办法: 利用yum-uitls中的工具package-cleanup指令,使用方法见下图,具体可通过man package-cleanup查询 列出重复的rpm包 pac ...
- 使用python解析C代码
我有一个巨大的C文件(~100k行),我需要能够解析.主要是我需要能够从其定义中获取有关每个结构的各个字段的详细信息(如结构中每个字段的字段名称和类型).是否有一个好的(开源,我可以在我的代码中使用) ...