Linux 搭建Hadoop集群 成功
内容基于(自己的真是操作步骤编写)
一:下载安装 Hadoop
1.1:下载指定的Hadoop
hadoop-2.8.0.tar.gz

1.2:通过XFTP把文件上传到master电脑bigData目录下
1.3:解压hadoop压缩文件
tar -xvf hadoop-2.8.0.tar.gz
1.4:进入压缩文件之后 复制路径
/bigData/hadoop-2.8.0
1.5:配置Hadoop的环境变量
vim /etc/profile

添加如下配置:

export HADOOP_HOME=/usr/bigdata/hadoop/hadoop-2.8.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
让文件生效:
wq!保存并退出
source /etc/profile让文件生效

二:Hadoop集群的配置
2.1:进入hadoop的配置文件位置
进入hadoop配置文件目录
cd hadoop2.8.0/etc/hadoop/

2.2:配置hadoop-env.sh文件
vim hadoop-env.sh
加入如下配置:
export JAVA_HOME=/usr/bigdata/java/jdk1.8.0_121
2.3:配置yarn-env.sh文件
vim yarn-env.sh
加入如下配置:
export JAVA_HOME=/usr/bigdata/java/jdk1.8.0_121
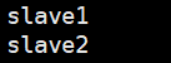
2.4:配置slaves文件,增加slave主机名或者IP地址
01.vim slaves
删除原有localhost,加入子机器名称或者ip地址
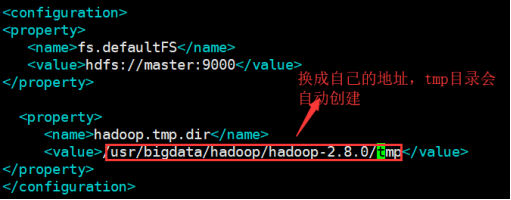
2.5:配置core-site.xml文件
01.vim core-site.xml
02.在configuration节点下加入如下配置:
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/bigdata/hadoop/hadoop-2.8.0/tmp</value>
</property>
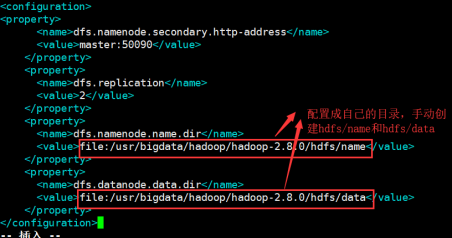
2.6:配置hdfs-site.xml文件
vim hdfs-site.xml
在configuration节点下加入如下配置:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/bigdata/hadoop/hadoop-2.8.0/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/bigdata/hadoop/hadoop-2.8.0/hdfs/data</value>
</property>
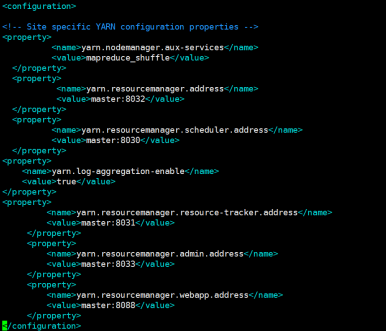
2.7:配置yarn-site.xml文件
在configuration节点下加入如下配置:
vim yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
2.8:配置mapred-site.xml文件
mapred-site.xml.template存在
mapred-site.xml不存在
先要copy一份
cp mapred-site.xml.template mapred-site.xml
然后编辑
vim mapred-site.xml
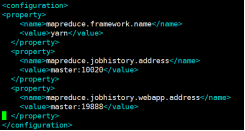
在configuration节点下加入如下配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
2.9:把配置好的hadoop文件复制到其他的子机器中
scp -r /usr/bigdata/hadoop/hadoop-2.8.0 root@slave1:/usr/bigdata/hadoop
scp -r /usr/bigdata/hadoop/hadoop-2.8.0 root@slave2:/usr/bigdata/hadoop
3.0把配置好的/etc/profile复制到其他两个子机器中
scp /etc/profile root@slave1:/etc/profile
scp /etc/profile root@slave2:/etc/profile
分别在两个子机器中应用/etc/profile
source /etc/profile
3.1:在master 主机器中运行
hdfs namenode -format
3.2:在master 主机器中启动hadoop环境
进入/usr/bigdata/hadoop/hadoop-2.8.0/sbin
./start-all.sh 启动hadoop集群
./stop-all.sh 关闭hadoop集群
3.3:jps
vim jps

3.4:启动JobHistoryServer
./mr-jobhistory-daemon.sh start historyserver

访问页面:
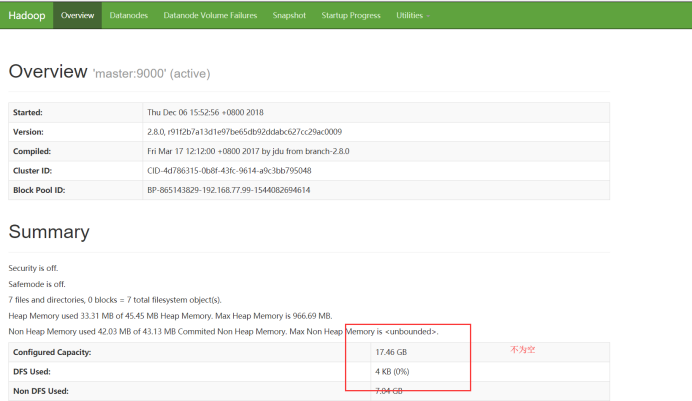


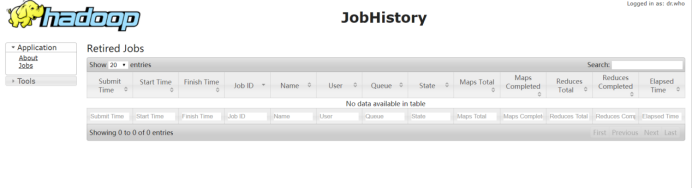
Hadoop集群搭建成功
3.5关闭:
第一步:
关闭JobHistoryServer
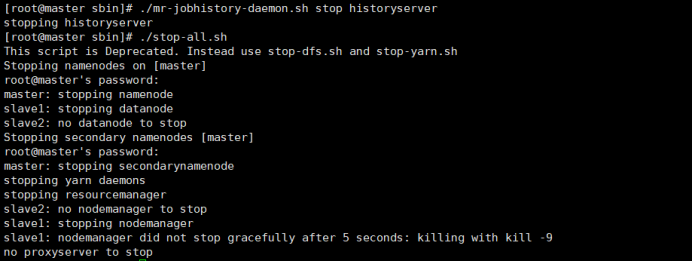
./mr-jobhistory-daemon.sh stop historyserver
第二步:
关闭hadoop集群
./stop-all.sh
Linux 搭建Hadoop集群 成功的更多相关文章
- Linux 搭建Hadoop集群错误锦集
一.Hadoop集群配置好后,执行start-dfs.sh后报错,一堆permission denied zf sbin $ ./start-dfs.sh Starting namenodes on ...
- Linux 搭建Hadoop集群 ----workcount案例
在 Linux搭建集群---JDK配置 Linux搭建集群---SSH免密登陆 Linux搭建集群---集群搭建成功 的基础上实现workcount案例 注意 虚拟机三台启动集群(自己亲自搭建) 1. ...
- Linux搭建Hadoop集群---Jdk配置
三台虚拟机:master slave1 slave2 192.168.77.99 master 192.168.77.88 slave1 192.168.77.77 slave2 1.修改主机名: ...
- 使用Docker搭建Hadoop集群(伪分布式与完全分布式)
之前用虚拟机搭建Hadoop集群(包括伪分布式和完全分布式:Hadoop之伪分布式安装),但是这样太消耗资源了,自学了Docker也来操练一把,用Docker来构建Hadoop集群,这里搭建的Hado ...
- Linux下搭建Hadoop集群
本文地址: 1.前言 本文描述的是如何使用3台Hadoop节点搭建一个集群.本文中,使用的是三个Ubuntu虚拟机,并没有使用三台物理机.在使用物理机搭建Hadoop集群的时候,也可以参考本文.首先这 ...
- 使用Windows Azure的VM安装和配置CDH搭建Hadoop集群
本文主要内容是使用Windows Azure的VIRTUAL MACHINES和NETWORKS服务安装CDH (Cloudera Distribution Including Apache Hado ...
- 搭建Hadoop集群 (一)
上面讲了如何搭建Hadoop的Standalone和Pseudo-Distributed Mode(搭建单节点Hadoop应用环境), 现在我们来搭建一个Fully-Distributed Mode的 ...
- virtualbox 虚拟3台虚拟机搭建hadoop集群
用了这么久的hadoop,只会使用streaming接口跑任务,各种调优还不熟练,自定义inputformat , outputformat, partitioner 还不会写,于是干脆从头开始,自己 ...
- 搭建Hadoop集群 (三)
通过 搭建Hadoop集群 (二), 我们已经可以顺利运行自带的wordcount程序. 下面学习如何创建自己的Java应用, 放到Hadoop集群上运行, 并且可以通过debug来调试. 有多少种D ...
随机推荐
- angularjs 的ng-disabled属性操作
ng-readonly:不可用,但是可以提交数据 ng-disabled: 属性是控制标签是否可用(不可用且无法传值) 表达式控制: <input class="col-md-2 fo ...
- 133. Clone Graph(图的复制)
Given the head of a graph, return a deep copy (clone) of the graph. Each node in the graph contains ...
- PHP 批量操作删除,支持单个删除
PHP 执行部分: <?php include('checkadmin.php'); header('Content-Type: text/html; charset=utf-8'); if( ...
- python selenium基于显示等待封装的一些常用方法
import os import time from PIL import Image from selenium import webdriver from appium import webdri ...
- 主线程——main线程
定义一个普通的类: 引用这个类,执行main方法,main方法就是一个主线程: 线程:进程的执行单元,可以理解为栈内存中的所执行的方法(除了main方法之外都是线程中的run方法)地址开辟通往cpu的 ...
- 石家庄铁道大学课程信息管理系统(javaWeb+servlet+Mysql)
实现网页版的课程管理系统,具有增删改查的功能. 1.首先连接数据库,具体数据库的使用及如何连接eclipse,参考 https://blog.csdn.net/lrici/article/de ...
- ASP.NET MVC:缓存功能的设计及问题
这是非常详尽的asp.net mvc中的outputcache 的使用文章. [原文:陈希章 http://www.cnblogs.com/chenxizhang/archive/2011/12/14 ...
- 【题解】Luogu SP1435 PT07X - Vertex Cover
原题传送门 求树的最小点覆盖,就是一个树形dp 类似于没有上司的舞会 dp的状态为\(f[i][0/1]\),表示i节点是否选择 边界是\(f[x][0]=0\),\(f[x][1]=1\) 转移方程 ...
- 对比Python中_,__,xx__xx
对比Python中_,__,xx__xx _ 的含义 不应该在类的外面访问,也不会被from M import * 导入. Python中不存在真正的私有方法.为了实现类似于c++中私有方法,可以 ...
- FFT 快速傅里叶变换 学习笔记
FFT 快速傅里叶变换 前言 lmc,ikka,attack等众多大佬都没教会的我终于要自己填坑了. 又是机房里最后一个学fft的人 早背过圆周率50位填坑了 用处 多项式乘法 卷积 \(g(x)=a ...