es之java索引操作
1.7.1: 创建索引
/**
* 创建索引
* */
@Test
public void createIndex(){
// 创建索引
CreateIndexResponse blog2 = client.admin().indices().prepareCreate("blog2").get();
System.out.println(blog2.toString()); }
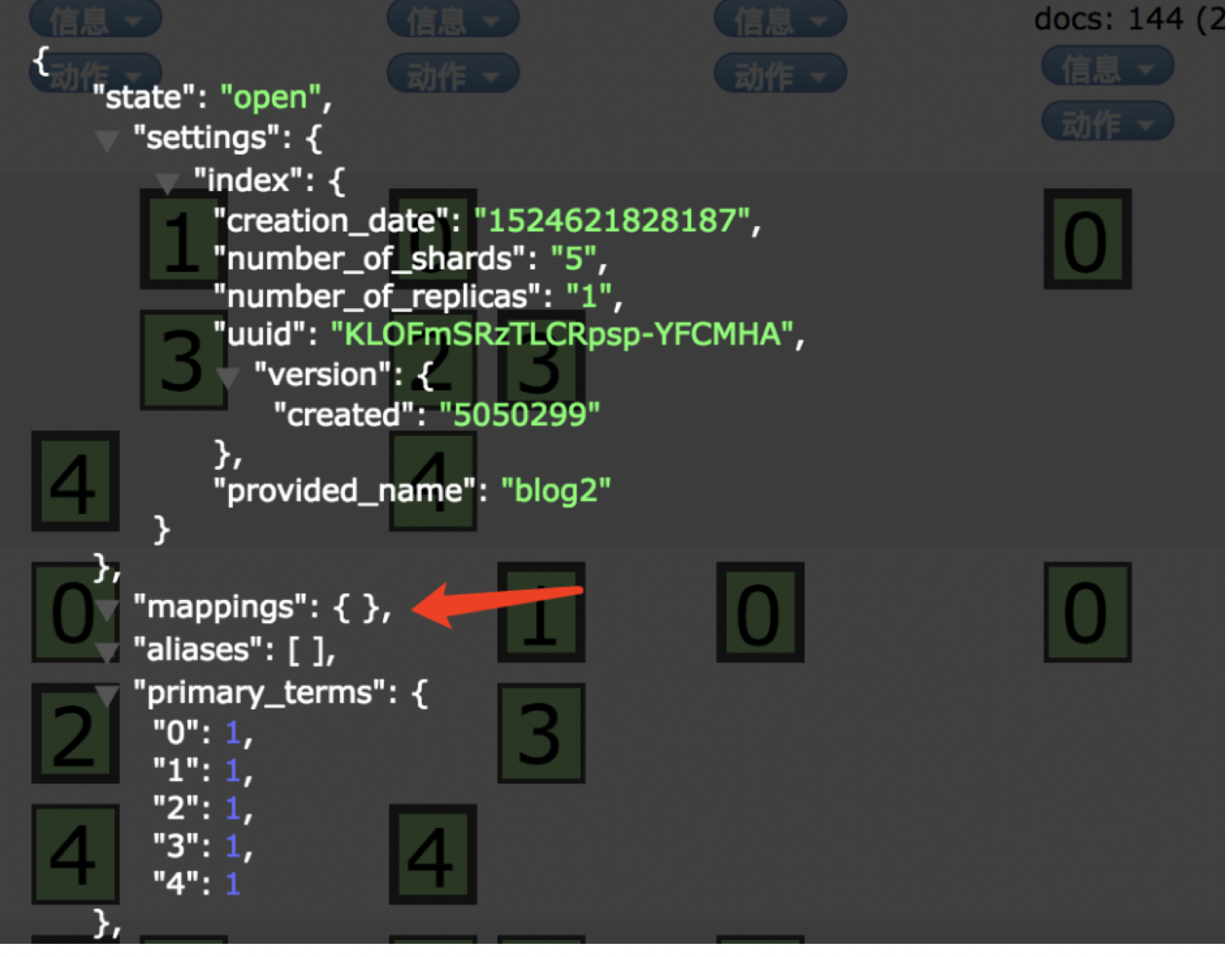
默认创建好索引,mappings为空
1.7.2: 删除索引
/**
* 删除索引
* */
@Test
public void deleteIndex(){
// 删除索引
client.admin().indices().prepareDelete("blog2").get();
}
1.7.3:索引的映射操作
为什么要进行手动的映射?
在实际生产中经常会出现精度损失的现象,往往就是因为没有进行正确的索引映射或者压根就没进行索引映射
Elasticsearch最开始索引文档A,其中的一个字段是一个数字,是整数;通过自动类型猜测,并设置类型为整型(integer)或者长整型;
然后在索引另一个文档B,B文档在同一个字段中存储的是浮点型;那么这个时候elasticsearch就会把B文档中的小数删除,保留整数部分;
这样就会导致数据的不准确!
如果你习惯SQL数据库,或许知道,在存入数据前,需要创建模式来描述数据(schmal);尽管elasticsearch是一个无模式的搜索引擎,可以即时算出数据结构;
但是我们仍然认为由自己控制并定义结构是更好的;而且在实际的生产中,我们也是自己创建映射;
注意:注意创建mapping的时候,索引必须提前存在

{
"settings":{
"nshards":3,
"number_of_repli umber_of_cas":1
},
"mappings":{
"dahan":{
"dynamic":"strict",
"properties":{
"studentNo":{"type": "string", "store": true},
"name":{"type": "string","store": true,"index" : "analyzed","analyzer": "ik_max_word"},
"male":{"type": "string","store": true},
"age":{"type": "integer","store": true},
"birthday":{"type": "string","store": true},
"classNo":{"type": "string","store": true},
"address":{"type": "string","store": true,"index" : "analyzed","analyzer": "ik_max_word"},
"isLeader": {"type": "boolean", "index": "not_analyzed"}
}
}
}
1):创建索引
/**
* 创建索引
* */
@Test
public void createIndex(){
CreateIndexResponse blog2 = client.admin().indices().prepareCreate("sanguo").get();
System.out.println(blog2.toString());
}
2):通过代码创建索引配置信息(有错的情况)
/**
* Created by angel;
*/
public class CreateMappings {
public static void main(String[] args) throws UnknownHostException {
TransportClient client = null;
Map<String, Integer> map = new HashMap<String, Integer>();
map.put("number_of_shards", 3);
map.put("number_of_replicas", 1);
Settings settings = Settings.builder()
.put("cluster.name", "cluster")
.build();
client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("hadoop01"), 9300));
System.out.println("========连接成功=============");
XContentBuilder builder = null;
try {
builder = jsonBuilder()
.startObject()
.startObject("dahan").field("dynamic", "true")
.startObject("properties")
.startObject("studentNo").field("type", "string").field("store", "yes").endObject()
.startObject("name").field("type", "string").field("store", "yes").field("analyzer", "ik_max_word").endObject()//.field("analyzer", "ik")
.startObject("male").field("type", "string").field("store", "yes").endObject()//.field("analyzer", "ik")
.startObject("age").field("type", "integer").field("store", "yes").endObject()
.startObject("birthday").field("type", "string").field("store", "yes").endObject()
.startObject("classNo").field("type", "string").field("store", "yes").endObject()
.startObject("address").field("type", "string").field("store", "yes").field("analyzer", "ik_max_word").endObject()
.startObject("isLeader").field("type", "boolean").field("store", "yes").field("index", "not_analyzed").endObject()
.endObject()
.endObject()
.endObject();
PutMappingRequest mapping = Requests.putMappingRequest("sanguo")
.type("dahan")
.source(builder);
UpdateSettingsRequest updateSettingsRequest = new UpdateSettingsRequest();
updateSettingsRequest.settings(map);
client.admin().indices().updateSettings(updateSettingsRequest).actionGet();
client.admin().indices().putMapping(mapping).get();
} catch (Exception e) {
e.printStackTrace();
}
}
}
如果有同学学习的比较扎实,那么会记住以下内容:
当索引不存在的时候,可以指定副本数和分片数
当索引存在的时候,只能指定副本数
所以,我们在构建索引的时候就要指定确定的分片和副本:
1):创建索引的时候直接指定索引的shard数和副本数
/**
* 创建索引
* */
@Test
public void createIndex(){
// 创建索引
Map<String, Integer> map = new HashMap<String, Integer>();
map.put("number_of_shards", 3);
map.put("number_of_replicas", 1);
CreateIndexResponse blog2 = client.admin().indices().prepareCreate("sanguo").setSettings(map).get();
System.out.println(blog2.toString());
}
2):然后在创建映射信息的时候,就可以忽略掉分片数和副本数了。直接进行索引的映射:
/**
* Created by angel;
*/
public class CreateMappings {
public static void main(String[] args) throws UnknownHostException {
TransportClient client = null;
Settings settings = Settings.builder()
.put("cluster.name", "cluster")
.build();
client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("hadoop01"), 9300));
System.out.println("========连接成功=============");
XContentBuilder builder = null;
try {
builder = jsonBuilder()
.startObject()
.startObject("dahan").field("dynamic", "true")
.startObject("properties")
.startObject("studentNo").field("type", "string").field("store", "yes").endObject()
.startObject("name").field("type", "string").field("store", "yes").field("analyzer", "ik_max_word").endObject()//.field("analyzer", "ik")
.startObject("male").field("type", "string").field("store", "yes").endObject()//.field("analyzer", "ik")
.startObject("age").field("type", "integer").field("store", "yes").endObject()
.startObject("birthday").field("type", "string").field("store", "yes").endObject()
.startObject("classNo").field("type", "string").field("store", "yes").endObject()
.startObject("address").field("type", "string").field("store", "yes").field("analyzer", "ik_max_word").endObject()
.startObject("isLeader").field("type", "boolean").field("store", "yes").field("index", "not_analyzed").endObject()
.endObject()
.endObject()
.endObject();
PutMappingRequest mapping = Requests.putMappingRequest("sanguo")
.type("dahan")
.source(builder);
client.admin().indices().putMapping(mapping).get();
} catch (Exception e) {
e.printStackTrace();
}
}
}
es之java索引操作的更多相关文章
- ES入门三部曲:索引操作,映射操作,文档操作
ES入门三部曲:索引操作,映射操作,文档操作 一.索引操作 1.创建索引库 #语法 PUT /索引名称 { "settings": { "属性名": " ...
- 008-elasticsearch5.4.3【二】ES使用、ES客户端、索引操作【增加、删除】、文档操作【crud】
一.ES使用,以及客户端 1.pom引用 <dependency> <groupId>org.elasticsearch.client</groupId> < ...
- es之java分页操作
按照一般的查询流程来说,如果我想查询前10条数据: · 1 客户端请求发给某个节点 · 2 节点转发给个个分片,查询每个分片上的前10条 · 3 结果返回给节点,整合数据,提取前10条 · 4 返回给 ...
- elasticsearch java 索引操作
1.添加maven依赖 <dependency> <groupId>org.elasticsearch</groupId> <artifactId>el ...
- ElasticSearch 获取es信息以及索引操作
检查集群的健康情况 GET /_cat/health?v green:每个索引的primary shard和replica shard都是active状态的yellow:每个索引的primary sh ...
- Elasticsearch必知必会的干货知识二:ES索引操作技巧
该系列上一篇文章<Elasticsearch必知必会的干货知识一:ES索引文档的CRUD> 讲了如何进行index的增删改查,本篇则侧重讲解说明如何对index进行创建.更改.迁移.查询配 ...
- ElasticSearch+Kibana 索引操作
ElasticSearch+Kibana 索引操作 一 前言 ElasticiSearch 简介 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引 ...
- ES系列十五、ES常用Java Client API
一.简介 1.先看ES的架构图 二.ES支持的客户端连接方式 1.REST API http请求,例如,浏览器请求get方法:利用Postman等工具发起REST请求:java 发起httpClien ...
- 【ELK】4.spring boot 2.X集成ES spring-data-ES 进行CRUD操作 完整版+kibana管理ES的index操作
spring boot 2.X集成ES 进行CRUD操作 完整版 内容包括: ============================================================ ...
随机推荐
- JDK8中接口的新特性
在JDK8环境中,接口中的方法不再是只能有抽象方法,还可以有静态方法和default方法.实现类只需要实现它的抽象方法即可,JDK8中的接口有愈发向抽象类靠拢的感觉. 关于静态方法和默认方法作如下简述 ...
- 如何查看SQL Server某个存储过程的执行历史【转】
db_name(d.database_id) as DBName, s.name as 存储名称, s.type_desc as 存储类型, d.cached_time as SP添加到缓存的时间, ...
- 安装配置php及fastadmin
FastAdmin教程之准备运行环境 一.Node.js http://nodejs.cn/download/ https://npm.taobao.org/mirrors/node/v8.4.0 ...
- [BZOJ 4332] [JSOI2012]分零食(DP+FFT)
[BZOJ 4332] [JSOI2012]分零食(DP+FFT) 题面 同学们依次排成了一列,其中有A位小朋友,有三个共同的欢乐系数O,S和U.如果有一位小朋友得到了x个糖果,那么她的欢乐程度就是\ ...
- C++关于erase的复杂度(转载)
被这个问题困扰了很多次,有必要整理一下. 当然最好的参考资料就是http://www.cplusplus.com/reference/set/set/erase/ 里的Complexcity部分了,但 ...
- 剑指offer-从尾到头打印链表-链表-python
题目描述 输入一个链表,按链表从尾到头的顺序返回一个ArrayList. 把链表依次放入list里面,反向打印 # -*- coding:utf-8 -*- # class ListNode: # d ...
- Django文档——Model中的ForeignKey,ManyToManyField与OneToOneField 关联关系字段 (Relationship fields)
ForeignKey,ManyToManyField与OneToOneField分别在Model中定义多对一,多对多,一对一关系. 例如,一本书由一家出版社出版,一家出版社可以出版很多书.一本书由多个 ...
- 看CLRS 对B树的浅显理解
定义及特点: 每个结点有n个关键字和n+1个指向子结点的指针,即有n+1个孩子结点. n个关键字按非递减的顺序存储. 最小度数t>=2,除了根结点的所有内部结点(非叶结点)的孩子数>=t且 ...
- 用户在浏览器输入URL或者跳转到一个URL后发生了什么
一.从URL到页面渲染的整个过程1)处理用户输入2)开始导航3)读取响应4)查找渲染进程5)确认导航6)渲染页面 二.每一步做了哪些事情 1)处理用户的输入 浏览器的UI 线程处理用户的输入,判断是跳 ...
- Linux之目录配置
Linux目录配置标准:FHS 主要目的,希望让用户可以了解到已安装软件通常放置于哪个目录下. FHS定义了三层主目录:/./usr./var 1. /(root,根目录) (1)根目录与开机.还原. ...