大数据笔记(一)——Hadoop的起源与背景知识
一.大数据的5个特征(IBM提出):
Volume(大量)
Velocity(高速)
Variety(多样)
Value(价值)
Varacity(真实性)
二.OLTP与OLAP
1.OLTP:联机事务处理过程,也称面向交易的处理过程,是对用户操作快速响应的方式之一。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易:
开启事务——>从转出账号中扣钱——>往转入账号中加钱——>提交事务
2.OLAP:联机分析处理过程,是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。例如商品推荐:
抽取(读取)历史订单——>分析历史订单,找到最受欢迎的商品——>展示结果
3.OLTP和OLAP的区别:
| OLTP | OLAP | |
| 用户 | 操作人员 | 决策人员,高级管理人员 |
| 功能 | 日常操作处理 | 分析决策 |
| DB设计 | 面向应用 | 面向主题 |
| 数据 | 当前的,最新的细节的,二维的分立的 | 历史的,聚集的,多位的,集成的,统一的 |
| 存取 | 读/写数十条记录 | 读上百万条记录 |
| 工作单位 | 简单的事务 | 复杂的事务 |
| DB大小 | 100MB-GB | 100GB-TB |
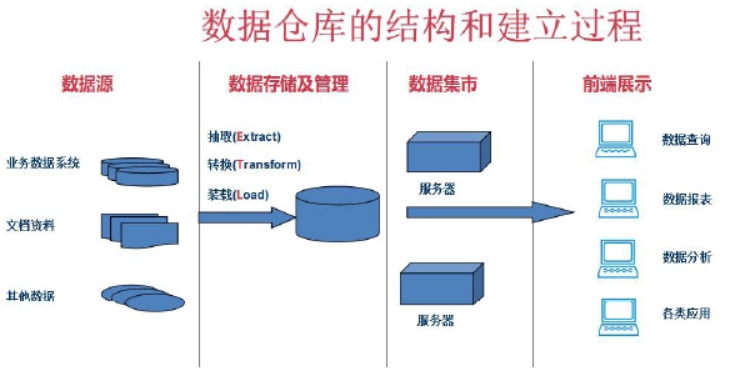
三.数据仓库
为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。
四.Google的基本思想
Hadoop的思想来源:Google
1.Google的低成本之道
- 不使用超级计算机,不使用存储(淘宝的去i,去e,去o之路)
- 大量使用普通的pc服务器,提供有冗余的集群服务
- 全世界多个数据中心
- 运营商向Google倒付费

2.Google的三篇论文(Hadoop的思想来源)
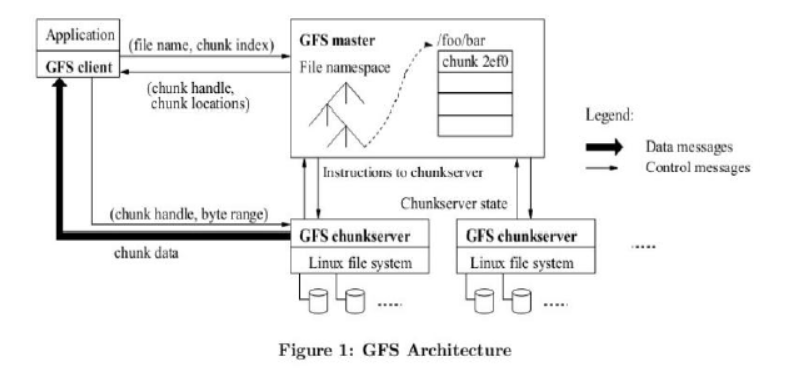
- GFS(Google File System:Google的文件系统)
- 倒排索引
把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。

- Page Rank(排名先后)
- BigTable(大表):Google设计的分布式数据存储系统,用来处理海量数据的一种非关系型数据库。
常见的NoSQL数据库(Key-value值):
- HBase:基于HDFS,面向列的:region
- Redis:基于内存、支持持久化:rdb和aof
- MongoDB:面向文档,Json型
大数据笔记(一)——Hadoop的起源与背景知识的更多相关文章
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装 大数据时代之hadoop(二):hadoop脚本解析 大数据时代之hadoop(三):hadoop数据流(生命周期) 大数据时代之hadoop(四): ...
- 大数据测试之初识Hadoop
大数据测试之初识Hadoop POPTEST老李认为测试开发工程师是面向测试的开发,也就是说,写代码就是为完成测试任务服务的,写自动化测试(性能自动化,功能自动化,安全自动化,接口自动化等等)的cas ...
- 一篇了解大数据架构及Hadoop生态圈
一篇了解大数据架构及Hadoop生态圈 阅读建议,有一定基础的阅读顺序为1,2,3,4节,没有基础的阅读顺序为2,3,4,1节. 第一节 集群规划 大数据集群规划(以CDH集群为例),参考链接: ht ...
- 大数据笔记01:大数据之Hadoop简介
1. 背景 随着大数据时代来临,人们发现数据越来越多.但是如何对大数据进行存储与分析呢? 单机PC存储和分析数据存在很多瓶颈,包括存储容量.读写速率.计算效率等等,这些单机PC无法满足要求. 2. ...
- 从Hadoop Summit 2016看大数据行业与Hadoop的发展
前言: 好吧我承认已经有四年多没有更新博客了.... 在这四年中发生了很多事情,换了工作,换了工作的方向.在工作的第一年的时候接触机器学习,从那之后的一年非常狂热的学习机器学习的相关技术,也写了一些自 ...
- ASP.NET + SqlSever 大数据解决方案 PK HADOOP
半个月前看到博客园有人说.NET不行那篇文章,我只想说你们有时间去抱怨不如多写些实在的东西. 1.SQLSERVER优点和缺点? 优点:支持索引.事务.安全性以及容错性高 缺点:数据量达到100万以 ...
- 大数据 --> Spark与Hadoop对比
Spark与Hadoop对比 什么是Spark Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法 ...
- 白话大数据 | Spark和Hadoop到底谁更厉害?
要想搞清楚spark跟Hadoop到底谁更厉害,首先得明白spark到底是什么鬼. 经过之前的介绍大家应该非常了解什么是Hadoop了(不了解的点击这里:白话大数据 | hadoop究竟是什么鬼),简 ...
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
随机推荐
- jQuery与JavaScript与ajax三者的区别与联系(转)
原文链接: https://blog.csdn.net/qq_43154385/article/details/85003484 通过阅读,对于三者关系有一个比较清晰的认知,对于后期深入学习大有裨益 ...
- 多线程15-ReaderWriterLockSlim
)); } ); rwl.EnterUpgradeableReadLock(); ...
- 用了 10 多年的 Tomcat 居然有bug !
Java技术栈 www.javastack.cn 优秀的Java技术公众号 为了解决分布式链路追踪的问题,我们引入了实现OpenTracing的Jaeger来实现.然后我们为SpringBoot框架写 ...
- 使用Postwoman
postman的脱单产品postwoman 一.安装 1.使用git进行安装: git clone https://github.com/liyasthomas/postwoman cd postwo ...
- 给定一个英文字符串,请编写一个PHP函数找出这个字符串中首先出现三次的那个英文字符(需要区分大小写),并返回
给定一个英文字符串,请编写一个PHP函数找出这个字符串中首先出现三次的那个英文字符(需要区分大小写),并返回 //统计字符串中出现的字符的出现次数 public function strNum(){ ...
- java中的四种引用方式(强引用,软引用,弱引用,虚引用)
java内存管理主要有内存分配和内存回收,都不需要程序员负责,垃圾回收的机制主要是看对象是否有引用指向该对象. java中对象的引用主要有四种:强引用,软引用,弱引用,虚引用. Java中提供这四种引 ...
- IBM公司的面试题,看看你能做出多少。
进入IBM差不多是每一个IT人的梦想.IBM公司向来以高素质人才作为企业持续竞争力的保证,所以经常出一些千奇百怪的面试题,来考验一个人的综合能力,以下是5道IBM曾经出过的面试题,看看你能作出几道: ...
- 您的浏览器没有获得Java Virtual Machine(JVM)支持。可能由于没有安装JVM或者已安装但是没有启用。请安装JVM1.5或者以上版本,如果已安装则启用它。
您的浏览器没有获得Java Virtual Machine(JVM)支持.可能由于没有安装JVM或者已安装但是没有启用.请安装JVM1.5或者以上版本,如果已安装则启用它. https://www.j ...
- 如何设置一个App的缓存机制
在手机应用程序开发中,为了减少与服务端的交互次数,加快用户的响应速度,一般都会在iOS设备中加一个缓存的机制,前面一篇文章介绍了iOS设备的内存缓存,这篇文章将设计一个本地缓存的机制. 功能需求 这个 ...
- Python列表(list)的方法调用
#list# n = [12,34,"yue"]# v = n.append(27) #增加元素,注意是在尾部增加,由于列表是可修改的,所以是在原列表中增加,与字符串存在区别# p ...