ICLR 2017-RL2: Fast Reinforcement Learning via Slow Reinforcement Learning
Key
GRUs+TRPO+GAE
解决的主要问题
- 现有RL方法需要手动设置特定领域的算法
- DRL学习的过程需要大量的试验牺牲了高样本复杂度(每个task需要数万次经验),相比人来说,这是由于缺乏先验知识(agent每次都需要从新建立关于MDP的相关知识信息)
文章内容
Introduction
贝叶斯RL将先验知识纳入学习过程,但是贝叶斯更新的精确计算在所有情况下都是非常困难的。
提出算法的思想:agent本身的学习过程视为一个目标,可以使用标准的强化学习算法进行优化。目标是根据特定的分布对所有可能的mdp进行平均,即提取到代理中的先验信息。将agent结构为一个循环神经网络,它的内部状态在各个episode中都被保留了下来,因此它有能力在自己的隐藏激活中进行学习。因此,学习agent也充当了学习算法,在部署时能够适应手头的任务。
Method
- Formulation
采样MDPs分布,与env交互;agent在每个task中交互n个episode,在训练每个task的时候,每条episode的隐含层信息会保留到下一条,但是两次trail之间(两个不同的MDP)不会保留。[a trail :固定MDP中,agent与env交互n个回合(episode)]
objective:最大化每个trail的预期累积总折扣奖励r,而不是每条episode
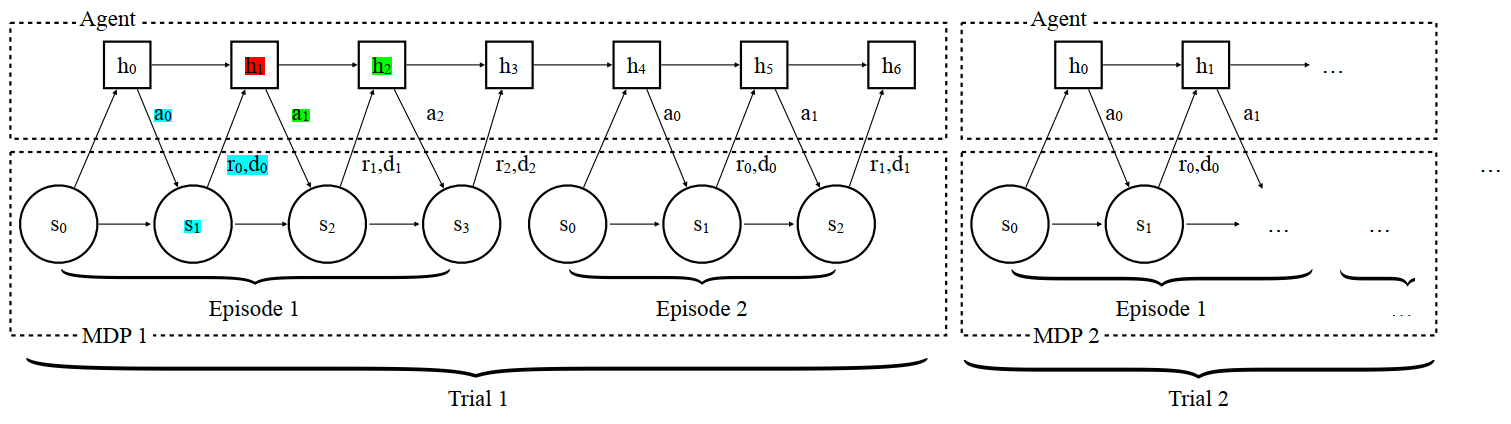
trail 1→policy 1
input:st+1,at,rt,dt
output:at+1,ht+2 (policy根据ht+1的隐藏层信息进行的输出)
底层MDP在不同的试验中变化,只要不同的MDP需要不同的策略,agent必须根据其当前所处的MDP的belief采取不同的行动。因此,agent被迫整合它收到的所有信息,并不断调整其策略。- policy表示:
门控制循环单位(GRUs),为了缓解由于梯度的消失和爆炸而导致的训练rnn的困难 - policy优化:
使用标准的现成RL算法来优化策略(因为任务定义为强化学习问题),使用Trust Region的一阶实现政策优化(TRPO),因为其优秀的经验性能,因为它不需要过多的超参数调优。
添加两个减少随机梯度估计中的方差方法:①使用了一个基线:一个使用gru作为构建块的RNN。②应用广义优势估计(GAE)
- Formulation
Evaluation
1.problem:
- RL2能够学习在具有特殊结构的MDP类上取得良好性能的算法吗
- 是否可以扩展到高维任务
2.文章分别在多臂赌博机、表格MDPs、可视化航行中进行了评估
- 多臂赌博机
在k=50和n=500的时候,RL2表现大不如Gittns,作者认为是轨迹探索的问题,因为它通过用Gittns获得轨迹进行元学习后,发现会达到Gittns一样好的相似结果。所以,该框架还有不足,应该还能改进更好的RL算法 - 表格MDPs
实验结果出现了在n越小的时候(即少量episode),RL2表现的更为优越了。作者认为出现这种情况是因为在n很小的时候,还有没有足够的样本来学习以至于不能形成一个很好的估计,所以小n的优势来自于需要更多积极的exploitation
???【but作者说,通过在这种设置下直接优化RNN,该方法应该能够应对这种样本短缺,相比于参考算法能够更快地决定 exploit。so?n越大效果比之前不好了,这是好还是坏?】 - 可视化航行
在迷宫探索中,agent进行前两个episode之间的轨迹长度都有显著的缩短,即前两个episode就能进行有效的探索以及适应,这说明agent已经学会如何使用过去信息。
but问题是agent偶尔会忘记target在哪,并且在第二个episode中继续探索,导致在第二个episode时候需要花费一些不必要地动作。so说明agent并不能完美地利用先验信息,我们期待agent在一个task中第一次episode的时候能够记住target位置,以便于在第二次episode时候能够完美地利用它。
Discussion
RL2:“快速”RL算法是一种计算,其状态存储在RNN激活中,RNN的权值由通用的“慢”强化学习算法学习
在实验中,改进RL2的不足:外环强化学习算法被证明是一个直接的瓶颈,策略可能也需要更好的架构
虽然本文方法已经为外循环算法和策略使用了泛型方法和体系结构,但这样做也会忽略底层的情景结构,未来希望利用问题结构的算法和策略架构能够显著提高性能
文章方法的优缺点
优点
- RNN的激活存储当前(以前不可见)MDP上的“快速”RL算法的状态
缺点
- 基于上下文的,RL中在处理的时候需要一个完整episode
- 也不能很好地利用先验信息(RNN不能解决长期依赖问题)
Summary
这篇文章是将agent结构为一个循环神经网络,利用了RNN来提取先验信息,以便于优化model。在评估的时候,虽然表现良好,但是也出现了一些问题,比如探索不足够,忘记target位置...很多问题归结为外环强化学习算法不够强大,需要更好地架构或者算法来改善这些问题。
我觉得这篇文章的方法和上一篇论文learning to reinforcement learn中提到的方法并没有差别太多。
论文链接
版权归原作者 Lee_ing 所有
未经原作者允许不得转载本文内容,否则将视为侵权;转载或者引用本文内容请注明来源及原作者
ICLR 2017-RL2: Fast Reinforcement Learning via Slow Reinforcement Learning的更多相关文章
- 从一篇ICLR'2017被拒论文谈起:行走在GAN的Latent Space
同步自我的知乎专栏文章:https://zhuanlan.zhihu.com/p/32135185 从Slerp说起 ICLR'2017的投稿里,有一篇很有意思但被拒掉的投稿<Sampling ...
- [2017.02.21] 《Haskell趣学指南 —— Learning You a Haskell for Great Good!》
{- 2017.02.21 <Haskell趣学指南 -- Learning You a Haskell for Great Good!> [官网](http://learnyouahas ...
- 论文翻译--StarCraft Micromanagement with Reinforcement Learning and Curriculum Transfer Learning
(缺少一些公式的图或者效果图,评论区有惊喜) (个人学习这篇论文时进行的翻译[谷歌翻译,你懂的],如有侵权等,请告知) StarCraft Micromanagement with Reinforce ...
- [2017.02.21-22] 《Haskell趣学指南 —— Learning You a Haskell for Great Good!》
{- 2017.02.21-22 <Haskell趣学指南 -- Learning You a Haskell for Great Good!> 学习了Haskell的基本语法,并实现了一 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- 机器学习(Machine Learning)&深入学习(Deep Learning)资料
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost 到随机森林. ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)---#####注:机器学习资料[篇目一](https://github.co ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料汇总 (上)
转载:http://dataunion.org/8463.html?utm_source=tuicool&utm_medium=referral <Brief History of Ma ...
- 最新小样本学习综述 A Survey on Few-Shot Learning | 四大模型Multitask Learning、Embedding Learning、External Memory…
目录 原文链接: 小样本学习与智能前沿 01 Multitask Learning 01.1 Parameter Sharing 01.2 Parameter Tying. 02 Embedding ...
随机推荐
- 如何利用javaweb实现数据的可视化
描述 之前一直使用html进行网页版的数据库查询啥的,没有图片的参与,也没有将一条条数据变成较为直观的图画形式,这就是来实现以下数据的图画形式 了解及基础说明 通过查阅资料,我首先了解到要是想实现数据 ...
- Java笔记第十二弹
Lambda表达式的标准格式 三要素:形式参数.箭头.代码块 格式:(形式参数)->(代码块) 形式参数:如果有多个参数,参数之间用逗号隔开:如果没有参数,留空即可 ->代表指向动作 La ...
- Quicker快速开发,简单的网页数据爬取(示例,获取天眼查指定公司基础工商数据)
前言 有某个线上项目,没有接入工商接口,每次录入公司的时候,都要去天眼查.企查查或者其他公开数据平台,然后手动录入,一两个还好说,数量多了的重复操作就很烦,而且,部分数据是包含超链接,一不注意就点进去 ...
- offsetX与offsetLeft
offsetX:鼠标指针距离当前绑定元素左侧距离,他并不是相对于带有定位的父盒子的x,y坐标, 记住了,很多博客都解释错了 offsetLeft,offsetTop 相对于最近的祖先定位元素.
- Install Ansible on CentOS 8
环境准备: 1.至少俩台linux主机,一台是控制节点,一台是受控节点 2.控制节点和受控节点都需要安装Python36 3.控制节点需要安装ansible 4.控制节点需要获得受控节点的普通用户或r ...
- AcWing 1353. 滑雪场设计
原题链接 思路 本题如果以贪心的思路来理解,则会遇到如果根据贪心算法变更后的最高峰和最低峰会发生改变,产生后效性,导致贪心算法无效,再考虑到本题目数据量不大,山峰数量在1k以内,山峰高度在100之内, ...
- Excel或数据库快速生成GUID
一般一些开发软件或者网站可以直接生成guid, 比如:https://www.iamwawa.cn/guid.html 但是在某些场景下,经常在一些excel或者数据库操作需要快速生成指定格式的gui ...
- 在NodeJS中安装babel
安装babel 打开终端,输入命令:npm install --save-dev @babel/core @babel/cli @babel/preset-env @babel/node 安装完毕之后 ...
- smtp.office365.com 无法从传输连接中读取数据: net_io_connectionclosed
这几天发送邮件时突然会报一个错 无法从传输连接中读取数据:net_io_connectionclosed. 因使用的是 smtp.office365.com 经过查询,发现了这个 Recently, ...
- phpcm v9 任意调用分页/phpcm v9首页调用分页不起作用或者乱码
默认如下: {pc:content action="lists" catid="1" num="10" order="id DES ...