python结巴分词及词频统计
1 def get_words(txt):
2 seg_list = jieba.cut(txt)
3 c = Counter()
4 for x in seg_list:
5 if len(x) > 1 and x != '\r\n':
6 c[x] += 1
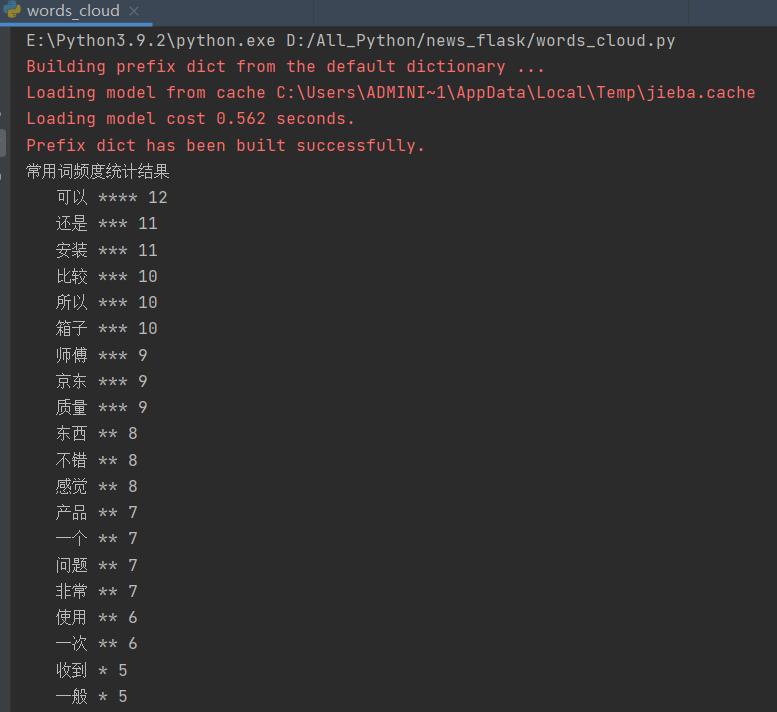
7 print('常用词频度统计结果')
8 for (k, v) in c.most_common(30):
9 print('%s%s %s %d' % (' ' * (5 - len(k)), k, '*' * int(v / 3), v))
10
11 if __name__ == '__main__':
12 with codecs.open('comments.txt', 'r', 'gbk') as f:
13 txt = f.read()
14 get_words(txt)
15 # get_text()
def get_words(txt):
seg_list = jieba.cut(txt)
c = Counter()
for x in seg_list:
if len(x) > 1 and x != '\r\n':
c[x] += 1
print('常用词频度统计结果')
for (k, v) in c.most_common(30):
print('%s%s %s %d' % (' ' * (5 - len(k)), k, '*' * int(v / 3), v))
if __name__ == '__main__':
with codecs.open('comments.txt', 'r', 'gbk') as f:
txt = f.read()
get_words(txt)
# get_text()
python结巴分词及词频统计的更多相关文章
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
- Python大数据:jieba 中文分词,词频统计
# -*- coding: UTF-8 -*- import sys import numpy as np import pandas as pd import jieba import jieba. ...
- 【python】利用jieba中文分词进行词频统计
以下代码对鲁迅的<祝福>进行了词频统计: import io import jieba txt = io.open("zhufu.txt", "r" ...
- Python 结巴分词(1)分词
利用结巴分词来进行词频的统计,并输出到文件中. 结巴分词github地址:结巴分词 结巴分词的特点: 支持三种分词模式: 精确模式,试图将句子最精确地切开,适合文本分析: 全模式,把句子中所有的可以成 ...
- Python 结巴分词
今天的任务是对txt文本进行分词,有幸了解到"结巴"中文分词,其愿景是做最好的Python中文分词组件.有兴趣的朋友请点这里. jieba支持三种分词模式: *精确模式,试图将句子 ...
- Python 结巴分词模块
原文链接:http://www.gowhich.com/blog/147?utm_source=tuicool&utm_medium=referral PS:结巴分词支持Python3 源码下 ...
- python 结巴分词学习
结巴分词(自然语言处理之中文分词器) jieba分词算法使用了基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图(DAG), 再采用了动态规划查找最大概率路径,找出基于 ...
- python 结巴分词(jieba)详解
文章转载:http://blog.csdn.net/xiaoxiangzi222/article/details/53483931 jieba “结巴”中文分词:做最好的 Python 中文分词组件 ...
- python结巴分词SEO的应用详解
结巴分词在SEO中可以应用于分析/提取文章关键词.关键词归类.标题重写.文章伪原创等等方面,用处非常多. 具体结巴分词项目:https://github.com/fxsjy/jieba ...
- python 结巴分词简介以及操作
中文分词库:结巴分词 文档地址:https://github.com/fxsjy/jieba 代码对 Python 2/3 均兼容 全自动安装:easy_install jieba 或者 pip in ...
随机推荐
- C++中两种获取UUID的方法(编程)
第一种,依托WMI #define _WIN32_DCOM #include <iostream> using namespace std; #include <comdef.h&g ...
- 学习go语言编程之常量
什么在常量 在Golang中,常量是指在编译期就已知且不可改变的值. 字面常量 在程序中硬编码的常量值被称为字面常量,如: -12 // 整数类型常量 3.1415926 // 浮点类型常量 3.2+ ...
- Notepad++设置删除当前行快捷键
Notepad++默认能实现"删除当前行"效果的快捷键是Ctrl + L,实际上这不并是真正意义上的删除当前行,而是剪切当前行. 而Eclipse中实现删除当前行的快捷键是:Ctr ...
- flutter——android报错Manifest merger failed : Attribute application@allowBackup value=(false)
与这个https://www.cnblogs.com/MaiJiangDou/p/13848658.html 报错类似. 报错: Manifest merger failed : Attribute ...
- 案例分享:Qt出版社书籍配套U盘资源播放器软件定制(脚本关联播放器与资源文件,播放器,兼容win7,win10和mac)
红胖子(红模仿)的博文大全:开发技术集合(包含Qt实用技术.树莓派.三维.OpenCV.OpenGL.ffmpeg.OSG.单片机.软硬结合等等)持续更新中-(点击传送门) 合作案例专栏:案例分享(体 ...
- Ubuntu下docker部署
使用docker进行容器化集成部署 远程服务器更新源 更新ubuntu的apt源 sudo apt-get update 安装包允许apt通过HTTPS使用仓库 sudo dpkg --configu ...
- 【Azure 环境】当在Azure 环境中调用外部接口不通时,如何定位SSL Certificate Problem
问题描述 如果在Azure VM中,发现同一个API,一台VM可以访问成功,另外一台访问失败.如何来调试并定位问题呢? 问题分析 第一步,查看访问外部API不通时候出现什么错误.如果没有明确的错误消息 ...
- 【Filament】材质系统
1 前言 本文主要介绍 Filament 的材质系统,官方介绍详见 → Filament Materials Guide.材质系统中会涉及到一些空间和变换的知识点,可以参考:[Unity3D]空间 ...
- SQL之 逻辑库,数据表
SQL语言三大类 创建逻辑库 创建数据表 例子 数据表其他操作 ps:desc仅仅查看表的结构,不能查看内容 添加字段 ps: 修改字段类型和约束 修改字段名称 删除字段
- Docker部署clickhouse
Clickhouse特点 完备的DBMS:不仅是个数据库,也是个数据库系统 列存储和数据压缩:典型的olap数据库特性 向量化并行:利用CPU的SIMD(Single INstruction MUlt ...