python结巴分词及词频统计
1 def get_words(txt):
2 seg_list = jieba.cut(txt)
3 c = Counter()
4 for x in seg_list:
5 if len(x) > 1 and x != '\r\n':
6 c[x] += 1
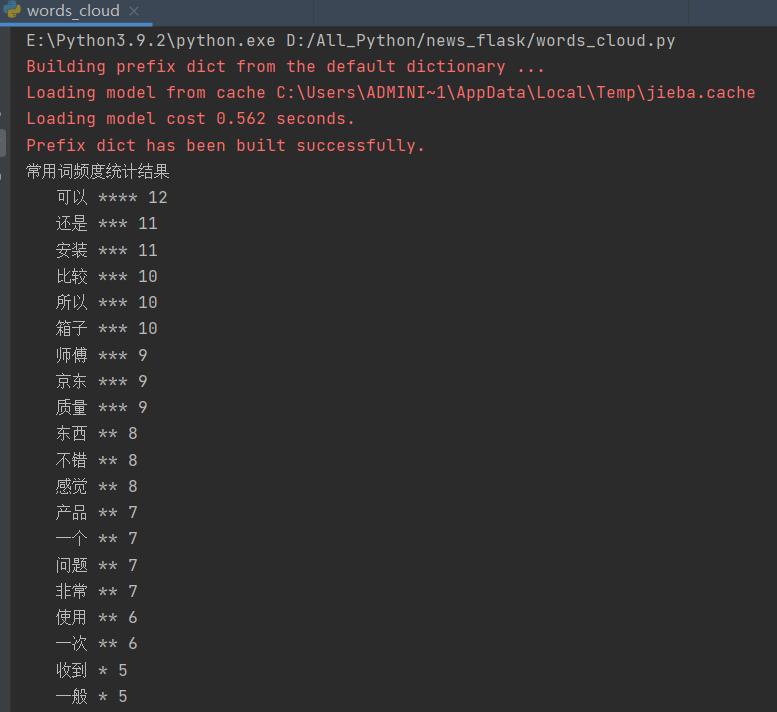
7 print('常用词频度统计结果')
8 for (k, v) in c.most_common(30):
9 print('%s%s %s %d' % (' ' * (5 - len(k)), k, '*' * int(v / 3), v))
10
11 if __name__ == '__main__':
12 with codecs.open('comments.txt', 'r', 'gbk') as f:
13 txt = f.read()
14 get_words(txt)
15 # get_text()
def get_words(txt):
seg_list = jieba.cut(txt)
c = Counter()
for x in seg_list:
if len(x) > 1 and x != '\r\n':
c[x] += 1
print('常用词频度统计结果')
for (k, v) in c.most_common(30):
print('%s%s %s %d' % (' ' * (5 - len(k)), k, '*' * int(v / 3), v))
if __name__ == '__main__':
with codecs.open('comments.txt', 'r', 'gbk') as f:
txt = f.read()
get_words(txt)
# get_text()
python结巴分词及词频统计的更多相关文章
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
- Python大数据:jieba 中文分词,词频统计
# -*- coding: UTF-8 -*- import sys import numpy as np import pandas as pd import jieba import jieba. ...
- 【python】利用jieba中文分词进行词频统计
以下代码对鲁迅的<祝福>进行了词频统计: import io import jieba txt = io.open("zhufu.txt", "r" ...
- Python 结巴分词(1)分词
利用结巴分词来进行词频的统计,并输出到文件中. 结巴分词github地址:结巴分词 结巴分词的特点: 支持三种分词模式: 精确模式,试图将句子最精确地切开,适合文本分析: 全模式,把句子中所有的可以成 ...
- Python 结巴分词
今天的任务是对txt文本进行分词,有幸了解到"结巴"中文分词,其愿景是做最好的Python中文分词组件.有兴趣的朋友请点这里. jieba支持三种分词模式: *精确模式,试图将句子 ...
- Python 结巴分词模块
原文链接:http://www.gowhich.com/blog/147?utm_source=tuicool&utm_medium=referral PS:结巴分词支持Python3 源码下 ...
- python 结巴分词学习
结巴分词(自然语言处理之中文分词器) jieba分词算法使用了基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图(DAG), 再采用了动态规划查找最大概率路径,找出基于 ...
- python 结巴分词(jieba)详解
文章转载:http://blog.csdn.net/xiaoxiangzi222/article/details/53483931 jieba “结巴”中文分词:做最好的 Python 中文分词组件 ...
- python结巴分词SEO的应用详解
结巴分词在SEO中可以应用于分析/提取文章关键词.关键词归类.标题重写.文章伪原创等等方面,用处非常多. 具体结巴分词项目:https://github.com/fxsjy/jieba ...
- python 结巴分词简介以及操作
中文分词库:结巴分词 文档地址:https://github.com/fxsjy/jieba 代码对 Python 2/3 均兼容 全自动安装:easy_install jieba 或者 pip in ...
随机推荐
- Oracle 中UNDO与REDO的区别详解
一 为了更清楚的看出2者区别,请看下表: UNDO REDO Rec ...
- Java并发编程实例--6.线程的join方法
有时我们需要等到某个线程执行完毕.例如,我可能有一个线程来初始化资源完毕然后其他线程才能开始执行. 谓词,我们可以使用Thread类的join()方法. 本例中,我们将学习使用这个方法. DataSo ...
- cf思维题
1.B. Paranoid String 题意:操作一:01可以变成1,操作二:10可以变成0.给定一个串,判断字串经过若干次操作,能否长度变成1,统计数量. 思路:对01来说,1可以吃掉0,然后前边 ...
- 字符串,format格式化及列表的相关进阶操作---day07
1.字符串相关操作 (1)字符串的拼接 (2)字符串的重复 (3)字符串跨行拼接 (4)字符串的索引 (5)字符串的切片:[开始索引:结束索引:步长] 2.字符串的格式化format (1)顺序传参 ...
- 无法加载 DLL“librdkafka”: 找不到指定的模块。 (异常来自 HRESULT:0x8007007E)
我这个错误是在引用了封装kafka项目的情况下提示的. 解决方案:在本项目里面安装 RdKafka ,再次运行就好了.
- Oracle触发器联合唯一约束
Oracle支持可为空字端的唯一约束呢?下面就是用触发器作出的限制语句,仅供参考: CREATE OR REPLACE TRIGGER Tg_Completion_Test BEFORE INSERT ...
- SpringMvc-<context:component-scan>使用说明
在xml配置了这个标签后,spring可以自动去扫描base-package下面或者子包下面的java文件,如果扫描到有@Component @Controller@Service等这些注解的类,则把 ...
- 「实操」结合图数据库、图算法、机器学习、GNN 实现一个推荐系统
本文是一个基于 NebulaGraph 上图算法.图数据库.机器学习.GNN 的推荐系统方法综述,大部分介绍的方法提供了 Playground 供大家学习. 基本概念 推荐系统诞生的初衷是解决互联网时 ...
- RocketMQ(8) 消费幂等
1 什么是消费幂等 当出现消费者对某条消息重复消费的情况时,重复消费的结果与消费一次的结果是相同的,并且多次消 费并未对业务系统产生任何负面影响,那么这个消费过程就是消费幂等的. 幂等:若某操作执行多 ...
- 搭建一个Java项目可直接拿去使用的通用工具类
1.通用枚举类 import lombok.Getter; /** * @Description 状态码定义约束,共6位数,前三位代表服务,后3位代表接口 * 比如 商品服务210,购物车是220.用 ...