【matplotlib 实战】--平行坐标系
平行坐标系是一种统计图表,它包含多个垂直平行的坐标轴,每个轴表示一个字段,并用刻度标明范围。通过在每个轴上找到数据点的落点,并将它们连接起来形成折线,可以很容易地展示多维数据。
随着数据增多,折线会堆叠,分析者可以从中发现数据的特性和规律,比如发现数据之间的聚类关系。
尽管平行坐标系与折线图表面上看起来相似,但它并不表示趋势,各个坐标轴之间也没有因果关系。
因此,在使用平行坐标系时,轴的顺序是可以人为决定的,这会影响阅读的感知和判断。较近的两根坐标轴会使对比感知更强烈。
因此,为了得出最合适和美观的排序方式,通常需要进行多次试验和比较。
同时,尝试不同的排序方式也可能有助于得出更多的结论。
此外,平行坐标系的每个坐标轴很可能具有不同的数据范围,这容易导致读者的误解。
因此,在绘制图表时,最好明确标明每个轴上的最小值和最大值。
1. 主要元素
平行坐标系是一种常用的数据可视化方法,用于展示多个维度的数据,并通过连接这些维度的线段来揭示它们之间的关系。
它的主要元素包括:
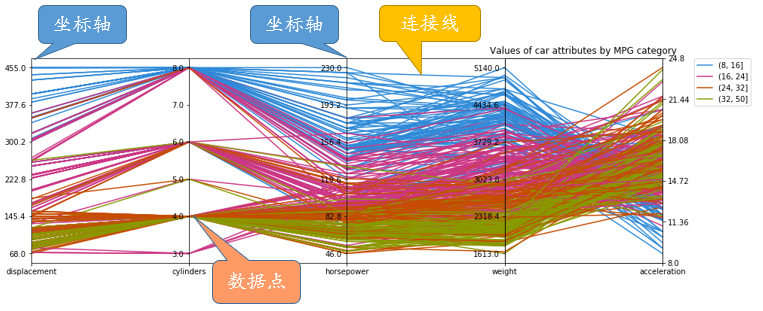
- 坐标轴:平行坐标系通常由垂直于数据维度的坐标轴组成,每个坐标轴代表一个数据维度。
- 数据点:每个数据点在平行坐标系中由一条连接各个坐标轴的线段表示,线段的位置和形状反映了数据点在各个维度上的取值。
- 连接线:连接线用于将同一数据点在不同维度上的线段连接起来,形成数据点的轮廓,帮助观察者理解数据点在各个维度上的变化趋势。
2. 适用的场景
平行坐标系适用的场景有:
- 多维数据分析:平行坐标系适用于展示多个维度的数据,帮助观察者发现不同维度之间的关系和趋势,例如在探索数据集中的模式、异常值或相关性时。
- 数据分类和聚类:通过观察数据点的轮廓和分布,可以帮助观察者识别不同的数据类别或聚类。
- 数据交互与过滤:平行坐标系可以支持交互式数据探索和过滤,通过选择或操作特定的坐标轴或线段,可以对数据进行筛选和聚焦。
3. 不适用的场景
平行坐标系不适用的场景有:
- 数据维度过多:当数据维度过多时,平行坐标系的可读性和解释性可能会下降,因为线段之间的交叉和重叠会导致视觉混乱。
- 数据维度之间差异较大:如果数据在不同维度上的取值范围差异较大,那么线段之间的比较和分析可能会受到影响,因为较小的取值范围可能会被较大的取值范围所掩盖。
- 数据具有时间序列:平行坐标系并不适用于展示时间序列数据,因为它无法准确地表示数据的时间顺序。在这种情况下,其他的数据可视化方法,如折线图或时间轴图,可能更适合。
4. 分析实战
平行坐标系适用于展示具有相同属性的一系列数据,每个坐标系代表一种属性。
这次选用了国家统计局公开的教育类数据:https://databook.top/nation/A0M
选取其中几类具有相同属性的数据:
- A0M06:各级各类学校专任教师数
- A0M07:各级各类学校招生数
- A0M08:各级各类学校在校学生数
- A0M09:各级各类学校毕业生数
4.1. 数据来源
四个原始数据集是按照年份统计的:
fp = "d:/share/A0M06.csv"
df = pd.read_csv(fp)
df
这是教师相关统计数据,其他3个数据集的结构也类似。
4.2. 数据清理
平行坐标系比较的是属性,不需要每年的数据。
所以,对于上面4个数据集,分别提取2022年的小学,初中,高中,特殊教育相关4个属性的数据。
import os
files = {
"教师数": "A0M06.csv",
"招生数": "A0M07.csv",
"在校学生数": "A0M08.csv",
"毕业学生数": "A0M09.csv",
}
data_dir = "d:/share"
data = pd.DataFrame()
for key in files:
fp = os.path.join(data_dir, files[key])
df = pd.read_csv(fp)
df_filter = pd.DataFrame(
[[
key,
df.loc[225, "value"],
df.loc[135, "value"],
df.loc[90, "value"],
df.loc[270, "value"],
]],
columns=["name", "小学", "初中", "高中", "特殊教育"],
)
data = pd.concat([data, df_filter])
data
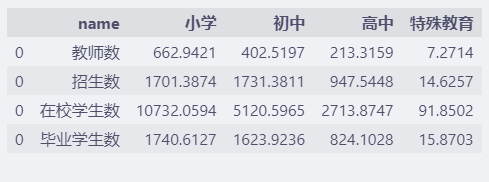
4.3. 分析结果可视化
平行坐标系在 matplotlib 中没有直接提供,实现起来也不难:
import matplotlib.pyplot as plt
from matplotlib.path import Path
import matplotlib.patches as patches
import numpy as np
xnames = data.loc[:, "name"]
ynames = ["小学", "初中", "高中", "特殊教育"]
ys = np.array(data.iloc[:, 1:].values.tolist())
ymins = ys.min(axis=0)
ymaxs = ys.max(axis=0)
dys = ymaxs - ymins
ymins -= dys * 0.05 # Y轴的上下限增加 5% 的冗余
ymaxs += dys * 0.05
#每个坐标系的上下限不一样,调整显示方式
zs = np.zeros_like(ys)
zs[:, 0] = ys[:, 0]
zs[:, 1:] = (ys[:, 1:] - ymins[1:]) / dys[1:] * dys[0] + ymins[0]
fig, host = plt.subplots(figsize=(10, 4))
axes = [host] + [host.twinx() for i in range(ys.shape[1] - 1)]
for i, ax in enumerate(axes):
ax.set_ylim(ymins[i], ymaxs[i])
ax.spines["top"].set_visible(False)
ax.spines["bottom"].set_visible(False)
if ax != host:
ax.spines["left"].set_visible(False)
ax.yaxis.set_ticks_position("right")
ax.spines["right"].set_position(("axes", i / (ys.shape[1] - 1)))
host.set_xlim(0, ys.shape[1] - 1)
host.set_xticks(range(ys.shape[1]))
host.set_xticklabels(ynames, fontsize=14)
host.tick_params(axis="x", which="major", pad=7)
host.spines["right"].set_visible(False)
host.xaxis.tick_top()
host.set_title("各类学校的师生数目比较", fontsize=18, pad=12)
colors = plt.cm.Set1.colors
legend_handles = [None for _ in xnames]
for j in range(ys.shape[0]):
verts = list(
zip(
[x for x in np.linspace(0, len(ys) - 1, len(ys) * 3 - 2, endpoint=True)],
np.repeat(zs[j, :], 3)[1:-1],
)
)
codes = [Path.MOVETO] + [Path.CURVE4 for _ in range(len(verts) - 1)]
path = Path(verts, codes)
patch = patches.PathPatch(
path, facecolor="none", lw=2, alpha=0.7, edgecolor=colors[j]
)
legend_handles[j] = patch
host.add_patch(patch)
host.legend(
xnames,
loc="lower center",
bbox_to_anchor=(0.5, -0.18),
ncol=len(xnames),
fancybox=True,
shadow=True,
)
plt.tight_layout()
plt.show()
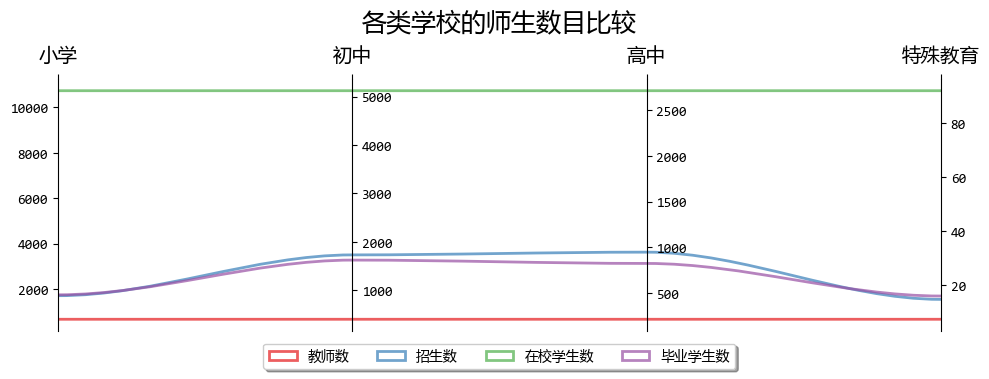
从图表中,可以看出一下几点,和我们对实际情况的印象是差不多的:
- 教师数量远小于学生数量
- 从小学到初中,高中,学生数量不断减少
- 招生数量和毕业生数量差不多
平行坐标系用于比较不同数据集的相同属性。
【matplotlib 实战】--平行坐标系的更多相关文章
- Echarts数据可视化parallel平行坐标系,开发全解+完美注释
全栈工程师开发手册 (作者:栾鹏) Echarts数据可视化开发代码注释全解 Echarts数据可视化开发参数配置全解 6大公共组件详解(点击进入): title详解. tooltip详解.toolb ...
- (转)matplotlib实战
原文:https://www.cnblogs.com/ws0751/p/8361330.html https://www.cnblogs.com/ws0751/p/8313017.html---mat ...
- matplotlib实战
plt.imshow(face_image.mean(axis=2),cmap='gray') 图片灰度处理¶ size = (m,n,3) 图片的一般形式就是这样的 rgb 0-255 jpg图 ...
- python学习之matplotlib实战2
import numpy as np import matplotlib.pyplot as plt def main(): #scatter fig = plt.figure() ax = fig. ...
- python学习之matplotlib实战
import numpy as np def main(): # print("hello") # line import matplotlib.pyplot as plt x = ...
- Echarts数据可视化radar雷达坐标系,开发全解+完美注释
全栈工程师开发手册 (作者:栾鹏) Echarts数据可视化开发代码注释全解 Echarts数据可视化开发参数配置全解 6大公共组件详解(点击进入): title详解. tooltip详解.toolb ...
- 推荐一款Python数据可视化神器
1. 前言 在日常工作中,为了更直观的发现数据中隐藏的规律,察觉到变量之间的互动关系,人们常常借助可视化帮助我们更好的给他人解释现象,做到一图胜千文的说明效果. 在Python中,常见的数据可视化库有 ...
- 数据挖掘(二)用python实现数据探索:汇总统计和可视化
今天我们来讲一讲有关数据探索的问题.其实这个概念还蛮容易理解的,就是我们刚拿到数据之后对数据进行的一个探索的过程,旨在了解数据的属性与分布,发现数据一些明显的规律,这样的话一方面有助于我们进行数据预处 ...
- Python数据可视化系列-02-pyecharts可视化非常cool
pyecharts介绍 pyecharts网站 Pyecharts生成的图像,动态效果非常cool.在HTML上展示很是perfect.matplotlib用于科研,但是pyecharts用于展示和讲 ...
- 5:Echarts数据可视化-多条曲线、多个子图、TreeMap类似盒图、树形图、热力图、词云
〇.目标 本次实验主要基于Echarts的Python库实现高维数据.网络和层次化数据.时空数据和文本数据的可视化,掌握可视化的操作流程和相关库的使用. 一.绘制平行坐标系 平行坐标是信息可视化的一种 ...
随机推荐
- 前端树形结构图组件 tree组件,可拖拽移动,点击展开收缩,无限添加子集
快速实现树形结构图组件 tree组件,可拖拽移动,点击展开收缩,无限添加子集; 下载完整代码请访问uni-app插件市场地址:https://ext.dcloud.net.cn/plugin?id=1 ...
- GPT3的局限性:语言多样性、语言理解能力、数据量
目录 GPT-3 的局限性:语言多样性.语言理解能力.数据量 随着人工智能技术的不断发展,越来越多的语言模型被开发出来,其中最具代表性的就是 GPT-3.然而,尽管 GPT-3 已经在自然语言处理领域 ...
- Linux系统运维之zabbix配置tomcat监控
一.介绍 半年前安装的zabbix监控,当时配合异地的测试人员给A项目做压力测试,主要监控项目部署的几台服务器的内存.CPU信息,以及后来网络I/O等,也没考虑JVM:最近闲下来,想完善下监控,故留此 ...
- Hexo博客使用valine评论系统无效果及终极解决方案
注意事项 有一些博主valine评论系统无效果,有一些原因: 1.很大程度是因为next的版本升级导致某些参数设置不同 2.valine评论是基于LeanCloud,还有一个文章阅读次数功能也是用Le ...
- pytesseract and ddddocr
一.pytesseract 1.简介 Pytesseract是一个Python库,用于将图像中的文本转换为可编辑的字符串.它是基于Google的Tesseract OCR引擎开发的 .Tesserac ...
- 【题解】Educational Codeforces Round 150(CF1841)
赛时过了 A-E,然后就开摆了,为什么感觉 C 那么无厘头[发怒][发怒] 排名:25th A.Game with Board 题目描述: Alice 和 Bob 玩游戏,他们有一块黑板.最初,有 \ ...
- UE构建基础和实践:五、CI/CD平台自动化打包
序言 使用CI/CD平台构建(这里使用蓝盾平台)主要是通过平台脚本运行上一章的py脚本并传递参数(即把py中的参数开放给配置平台脚本配置). Build.py 重构 我们需要在py脚本里面解析和设置参 ...
- CSSRelated
CSS 几种常用的清除浮动方法 ️️️ 父级 div 定义伪类:after 和 zoom; /* 这个class名指的是需要清除浮动的父级 */ .clearfloat:after { display ...
- [golang]简单的文件上传下载
前言 某次在客户内网传输数据的时候,防火墙拦截了SSH的数据包,导致没法使用scp命令传输文件,tcp协议和http协议也只放开了指定端口,因此想了个用http传输的"曲线救国"方 ...
- 从redis未授权访问到获取服务器权限
从redis未授权访问到获取服务器权限 好久没写博客了,博客园快荒芜了.赶紧再写一篇,算是一个关于自己学习的简要的记录把. 这里是关于redis未授权访问漏洞的一篇漏洞利用: 首先是redis,靶场搭 ...