【ClickHouse】0:clickhouse学习1之数据引擎(数据库引擎,表引擎)
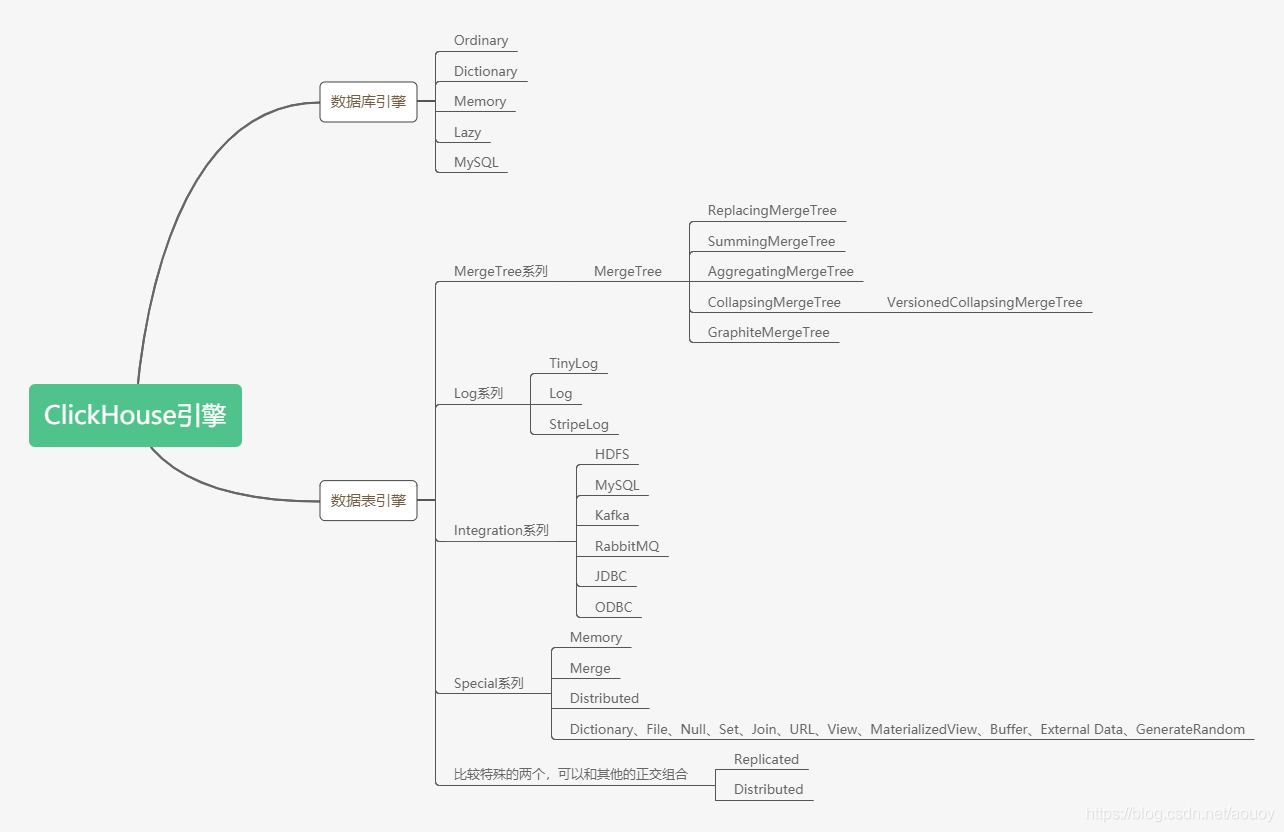
ClickHouse提供了大量的数据引擎,分为数据库引擎、表引擎,根据数据特点及使用场景选择合适的引擎至关重要,这里根据资料做一些总结。
数据库引擎官方文档: https://clickhouse.tech/docs/en/engines/database-engines
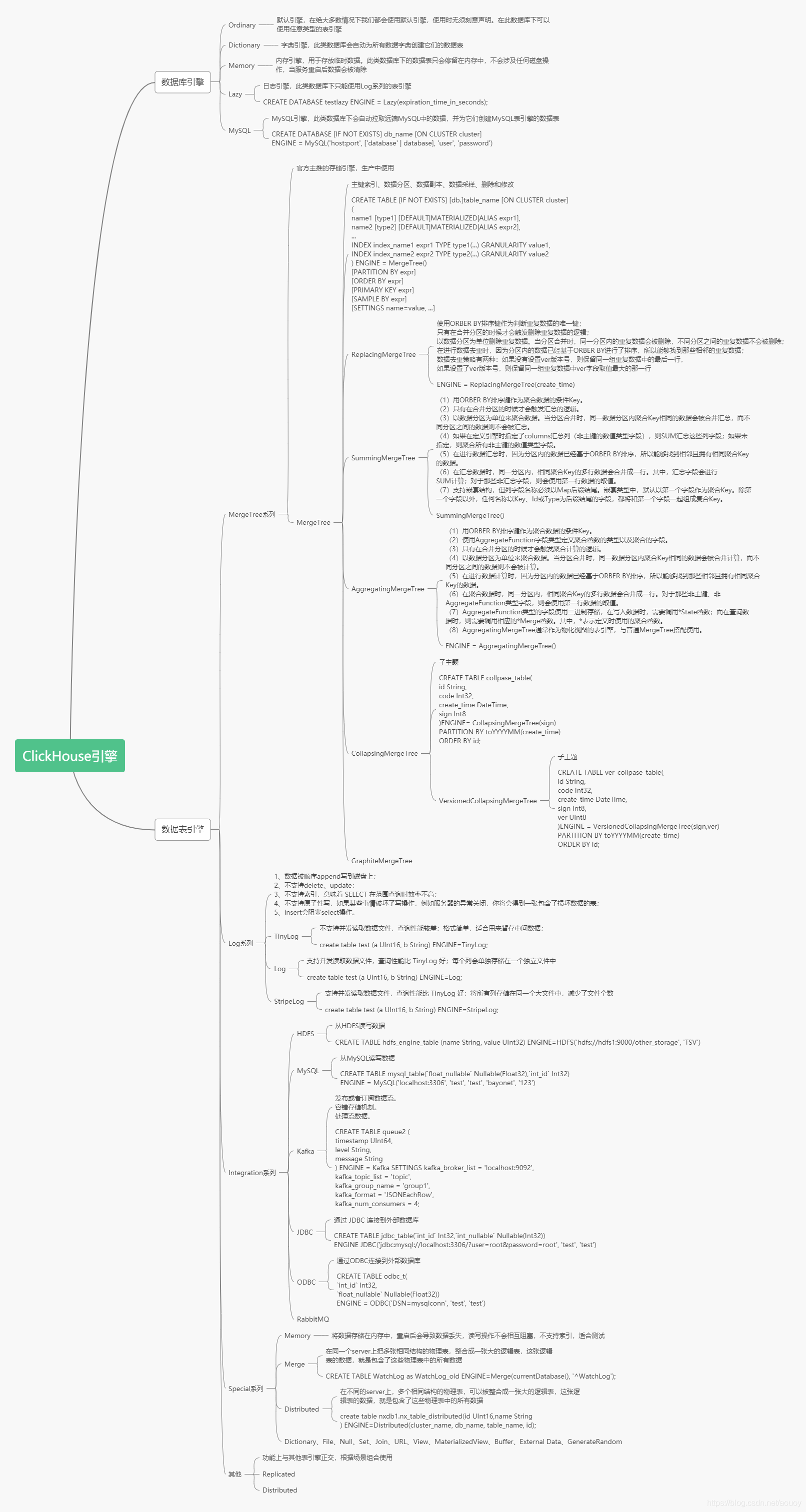
数据库引擎默认是Ordinary,在这种数据库下面的表可以是任意类型引擎。
生产环境中常用的表引擎是MergeTree系列,也是官方主推的引擎。
MergeTree是基础引擎,有主键索引、数据分区、数据副本、数据采样、删除和修改等功能,
ReplacingMergeTree有了去重功能,
SummingMergeTree有了汇总求和功能,
AggregatingMergeTree有聚合功能,
CollapsingMergeTree有折叠删除功能,
VersionedCollapsingMergeTree有版本折叠功能,
GraphiteMergeTree有压缩汇总功能。
在这些的基础上还可以叠加Replicated和Distributed。
Integration系列用于集成外部的数据源,常用的有HADOOP,MySQL。
引言
表引擎在ClickHouse中的作用十分关键,直接决定了数据如何存储和读取、是否支持并发读写、是否支持index、支持的query种类、是否支持主备复制等。
ClickHouse提供了大约28种表引擎,各有各的用途,比如有Lo系列用来做小表数据分析,MergeTree系列用来做大数据量分析,而Integration系列则多用于外表数据集成。再考虑复制表Replicated系列,分布式表Distributed等,纷繁复杂,新用户上手选择时常常感到迷惑。
本文尝试对ClickHouse的表引擎进行梳理,帮忙大家快速入门ClickHouse。
ClickHouse表引擎概览

一共分为四个系列,分别是Log、MergeTree、Integration、Special。其中包含了两种特殊的表引擎Replicated、Distributed,功能上与其他表引擎正交,我们后续会单独写一篇文章来介绍。
Log系列
Log系列表引擎功能相对简单,主要用于快速写入小表(1百万行左右的表),然后全部读出的场景。
几种Log表引擎的共性是:
- 数据被顺序append写到磁盘上;
- 不支持delete、update;
- 不支持index;
- 不支持原子性写;
- insert会阻塞select操作。
它们彼此之间的区别是:
TinyLog:不支持并发读取数据文件,查询性能较差;格式简单,适合用来暂存中间数据;
StripLog:支持并发读取数据文件,查询性能比TinyLog好;将所有列存储在同一个大文件中,减少了文件个数;
Log:支持并发读取数据文件,查询性能比TinyLog好;每个列会单独存储在一个独立文件中。
Integration系列
该系统表引擎主要用于将外部数据导入到ClickHouse中,或者在ClickHouse中直接操作外部数据源。
Kafka:将Kafka Topic中的数据直接导入到ClickHouse;
MySQL:将Mysql作为存储引擎,直接在ClickHouse中对MySQL表进行select等操作;
JDBC/ODBC:通过指定jdbc、odbc连接串读取数据源;
HDFS:直接读取HDFS上的特定格式的数据文件;
Special系列
Special系列的表引擎,大多是为了特定场景而定制的。这里也挑选几个简单介绍,不做详述。
Memory:将数据存储在内存中,重启后会导致数据丢失。查询性能极好,适合于对于数据持久性没有要求的1亿一下的小表。在ClickHouse中,通常用来做临时表。
Buffer:为目标表设置一个内存buffer,当buffer达到了一定条件之后会flush到磁盘。
File:直接将本地文件作为数据存储;
Null:写入数据被丢弃、读取数据为空;
MergeTree系列
Log、Special、Integration主要用于特殊用途,场景相对有限。MergeTree系列才是官方主推的存储引擎,支持几乎所有ClickHouse核心功能。
以下重点介绍MergeTree、ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree、SummingMergeTree、AggregatingMergeTree引擎。
参考文章:https://clickhouse.tech/docs/en/engines
参考文章:https://blog.csdn.net/A1373712651/article/details/103608340
参考文章:https://blog.csdn.net/qq_41106844/article/details/107067525
【ClickHouse】0:clickhouse学习1之数据引擎(数据库引擎,表引擎)的更多相关文章
- mybatis基础学习4-插件生成器(根据数据库的表生成文件)
1:安装(根据数据库的表生成文件) 2:在所建项目单击右键输入mybatis如下图 *建项目文件时不用建包和类,插件可以根据数据表自动生成,在配置文件(generatorConfig.xml)里写即可 ...
- Android(java)学习笔记192:SQLite数据库(表)的创建 以及 SQLite数据库的升级
一.数据库的创建 1.文件的创建 //引用,如果文件不存在是不会创建的 File file = new File("haha.txt"): //输出流写数据 ...
- MySQL学习总结(二)数据库以及表的基本操作
上一节中详细的介绍了关于MySQL数据库的安装过程,接下来我们就该对数据库以及表进行一些基本的操作了. 1.数据类型 MySQL数据库中提供了整数类型.浮点数类型.定点数类型.日期和时间类型.字符串类 ...
- Android(java)学习笔记135:SQLite数据库(表)的创建 以及 SQLite数据库的升级
一.数据库的创建 1.文件的创建 //引用,如果文件不存在是不会创建的 File file = new File("haha.txt"): //输出流写数据 ...
- USB2.0协议学习笔记---USB数据包结构
USB包类型和传输过程 USB是一种串行总线,因此数据都是一位一位传输的,如同串口那样,但是USB在真实物理电路上却不是TTL电平,而是一种差分信号采用NRZI编码,就是用变化表示0,不变表示1,同 ...
- 【数据库】9.0 MySQL入门学习(九)——获得数据库和表的信息、日期计算、查询、选择特殊列
1.0 SELECT语句用来从数据表中检索信息. SELECT what_to_select FROM which_table WHERE conditions_to_satisfy; what_to ...
- ClickHouse(02)ClickHouse架构设计介绍概述与ClickHouse数据分片设计
ClickHouse核心架构设计是怎么样的?ClickHouse核心架构模块分为两个部分:ClickHouse执行过程架构和ClickHouse数据存储架构,下面分别详细介绍. ClickHouse执 ...
- ClickHouse入门:表引擎-HDFS
前言插件及服务器版本服务器:ubuntu 16.04Hadoop:2.6ClickHouse:20.9.3.45 文章目录 简介 引擎配置 HDFS表引擎的两种使用形式 引用 简介 ClickHous ...
- #学习笔记#JSP数据交互
#学习笔记#JSP数据交互 数据库的使用方式: 当用户在第一个页面的查询框输入查询语句点提交的时候我们是用什么样的方式完成这个查询的? 答:我们通过在第一个页面提交表单的形式,真正的数据库查询时在 ...
- 【实时数仓】Day05-ClickHouse:入门、安装、数据类型、表引擎、SQL操作、副本、分片集群
一.ClickHouse入门 1.介绍 是一个开源的列式存储数据库(DBMS) 使用C++编写 用于在线分析查询(OLAP) 能够使用SQL查询实时生成分析数据报告 2.特点 (1)列式存储 比较: ...
随机推荐
- idea在商店无法搜索到插件
背景:我使用的版本是IDEA ultimate 2019.2 版本印象中,最初安装的时候,商店还是可以用的,突然有一天,就无法使用了.下边直入正题: 解决办法:1.首先浏览器登陆下:https://p ...
- MacOS安装gprMax教程
原文发布于:https://blog.zhaoxuan.site/archives/19.html: 第一时间获取最新文章请关注博客个人站:https://blog.zhaoxuan.site. 1. ...
- Spring如何控制Bean的加载顺序
前言 正常情况下,Spring 容器加载 Bean 的顺序是不确定的,那么我们如果需要按顺序加载 Bean 时应如何操作?本文将详细讲述我们如何才能控制 Bean 的加载顺序. 场景 我创建了 4 个 ...
- Mybatis-plus把List数据分页
一.编写工具类: /** * @project * @Description 多表联查-分页 * @Author songwp * @Date 2022/8/8 10:31 * @Version 1. ...
- Java简单实现MQ架构和思路01
实现一个 MQ(消息队列)架构可以涉及到很多方面,包括消息的生产和消费.消息的存储和传输.消息的格式和协议等等.下面是一个简单的 MQ 架构的实现示例,仅供参考: 定义消息格式和协议:我们可以定义一个 ...
- vue3编译优化之“静态提升”
前言 在上一篇 vue3早已具备抛弃虚拟DOM的能力了文章中讲了对于动态节点,vue做的优化是将这些动态节点收集起来,然后当响应式变量修改后进行靶向更新.那么vue对静态节点有没有做什么优化呢?答案是 ...
- MindSponge分子动力学模拟——体系控制(2024.05)
技术背景 在传统的分子动力学模拟软件中,对于分子体系的控制,例如控制体系的相对位置亦或是绝对位置,通常都是通过施加一些约束算法来实现的.例如用于限制化学键的LINCS算法,又比如水分子体系非常常用的S ...
- 用tkinter编写一个简单的登录注册界面
代码: from tkinter import * window = Tk() window.geometry('400x300+500+150') window.title('xxx系统') Can ...
- C# wpf 实现截屏框实时截屏功能
wpf截屏系列第一章 使用GDI+实现截屏第二章 使用DockPanel制作截屏框第三章 实现截屏框实时截屏(本章)第四章 使用ffmpeg命令行实现录屏 文章目录wpf截屏系列前言一.实现步骤1.获 ...
- .Net Core 静态类获取注入服务
由于静态类中无法使用有参构造函数,从而不能使用常规的方式(构造函数获取) 获取服务,我们可以采取通过IApplicationBuilder 获取 1.首先创建一个静态类 using Microsoft ...