ClickHouse入门:表引擎-HDFS
前言
插件及服务器版本
服务器:ubuntu 16.04
Hadoop:2.6
ClickHouse:20.9.3.45
文章目录
- 简介
- 引擎配置
- HDFS表引擎的两种使用形式
- 引用
简介
ClickHouse的HDFS引擎可以对接hdfs,这里假设HDFS环境已经配置完成,本文测试使用的HDFS版本为2.6
HDFS引擎定义方法如下:
ENGINE = HDFS(hdfs_uri,format)
参数定义:
- hdfs_uri表示HDFS的文件存储路径
- format表示文件格式(指ClickHouse支持的文件格式,常见有CSV、TSV和JSON等)
HDFS表引擎两种使用方式:
- 即负责读文件也负责写文件
- 只负责读文件,文件写入工作则由外部系统完成
引擎配置
由于hdfs配置了HA,如果不做配置,创建一张只负责读文件的表,并查询数据,会报如下错误:
Code: 210. DB::Exception: Received from localhost:9000.
DB::Exception: Unable to connect to HDFS: InvalidParameter: Cannot parse URI:
hdfs://mycluster, missing port or invalid HA configuration
Caused by: HdfsConfigNotFound: Config key: dfs.ha.namenodes.mycluster not found.

需要做如下配置解决问题
1、拷贝hdfs-site.xml文件至/etc/clickhouse-server,并修改文件名为hdfs-client.xml
2、修改ClickHouse Server启动文件,添加环境变量Environment=“LIBHDFS3_CONF=/etc/clickhouse-server/hdfs-client.xml”
备注:
这里测试环境为ubuntu环境,启动服务用systemctl启动,所以修改启动文件的路径为:vi /etc/systemd/system/clickhouse-server.service
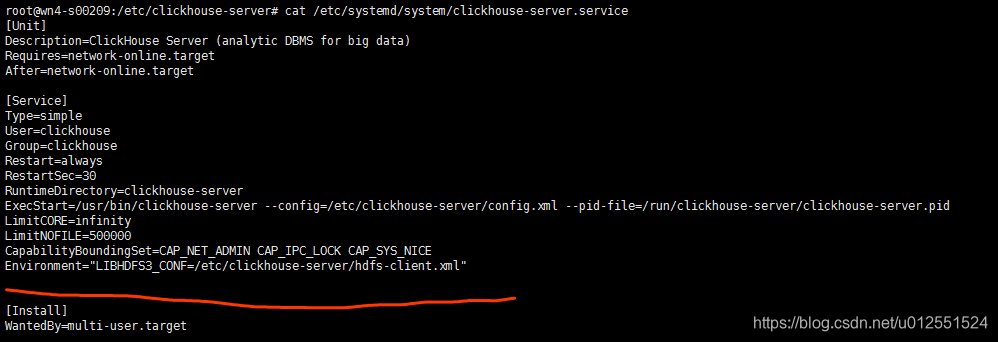
3、加载并重启clickhouse-serversystemctl daemon-reload
systemctl restart clickhouse-server.service
4、测试
新创建一张只读表,对应的hdfs上已经提前放了一个测试文件 1.txt
CREATE TABLE test_hdfs
(
id Int32
)
ENGINE HDFS('hdfs://mycluster/1.txt','CSV');

查询表里的数据
HDFS表引擎的两种使用形式
即负责读文件,也负责写文件
创建一张新表
CREATE TABLE test_hdfs_read
(
id Int32,
name String
)
ENGINE HDFS('hdfs://mycluster/test','CSV');

插入数据
insert into test_hdfs_read values (1,'tracy');

查询表数据并查看hdfs目录情况


这里可以看到hdfs目录下多了一个test文件
只负责读文件,文件写入工作则由外部系统完成
这种形式类似于hive的外挂表,由其它系统直接将文件直接写入HDFS,通过参数hdsfs_ui和format与HDFS的文件路径、文件格式建立映射,其中hdfs_uri支持以下几种常见的配置方法:
1. 绝对路径:会指定路径上的单个文件,例如hdfs://mycluster/1.txt
2. *通配符:匹配所有字符,例如hdfs://mycluster/ * ,会读取hdfs://mycluster/路径下的所有文件
3. ?通配符:匹配单个字符,例如hdfs://mycluster/test_?.txt会匹配所有test_?.txt的文件,?代表任意字符
4. {M…N}数字区间:匹配指定数字的文件,例如路径hdfs://mycluster/test_{1…3}.txt,则会读取hdfs://mycluster/路径下的文件test_1.txt,test_2.txt,test_3.txt在hdfs新建一个目录,并放3个文件

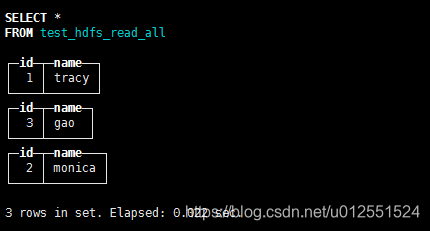
测试*通配符
CREATE TABLE test_hdfs_read_all
(
`id` Int32,
`name` String
)
ENGINE = HDFS('hdfs://mycluster/test_hdfs_read/*', 'CSV')
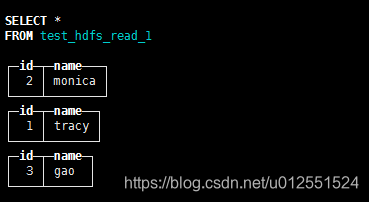
测试?通配符
CREATE TABLE test_hdfs_read_1
(
`id` Int32,
`name` String
)
ENGINE = HDFS('hdfs://mycluster/test_hdfs_read/test_?.csv', 'CSV')
测试数字区间通配符通配符
CREATE TABLE test_hdfs_read_2
(
`id` Int32,
`name` String
)
ENGINE = HDFS('hdfs://mycluster/test_hdfs_read/test_{2..3}.csv', 'CSV')

这里只匹配了test_2和test_3,所以只有两条记录
引用
https://github.com/ClickHouse/ClickHouse/issues/8159
ClickHouse入门:表引擎-HDFS的更多相关文章
- UniqueMergeTree:支持实时更新删除的 ClickHouse 表引擎
UniqueMergeTree 开发的业务背景 首先,我们看一下哪些场景需要用到实时更新. 我们总结了三类场景: 第一类是业务需要对它的交易类数据进行实时分析,需要把数据流同步到 ClickHouse ...
- ClickHouse(10)ClickHouse合并树MergeTree家族表引擎之ReplacingMergeTree详细解析
目录 建表语法 数据处理策略 资料分享 参考文章 MergeTree拥有主键,但是它的主键却没有唯一键的约束.这意味着即便多行数据的主键相同,它们还是能够被正常写入.在某些使用场合,用户并不希望数据表 ...
- clickhouse入门到实战及面试
第一章. clickhouse入门 一.ClickHouse介绍 ClickHouse(开源)是一个面向列的数据库管理系统(DBMS),用于在线分析处理查询(OLAP). 关键词:开源.面向列.联机分 ...
- Clickhouse 入门
clickhouse 简介 ck是一个列式存储的数据库,其针对的场景是OLAP.OLAP的特点是: 数据不经常写,即便写也是批量写.不像OLTP是一条一条写 大多数是读请求 查询并发较少,不适合放置先 ...
- ClickHouse入门笔记
ClickHouse笔记 目录 ClickHouse笔记 第 1 章 ClickHouse 入门 列式储存的好处: 第 2 章 ClickHouse 的安装 第 3 章 数据类型 整型 浮点型 布尔型 ...
- Clickhouse 分布式表&本地表 &ClickHouse实现时序数据管理和挖掘
一.CK 分布式表和本地表 (1)CK是一个纯列式存储的数据库,一个列就是硬盘上的一个或多个文件(多个分区有多个文件),关于列式存储这里就不展开了,总之列存对于分析来讲好处更大,因为每个列单独存储,所 ...
- Clickhouse 分布式表&本地表
CK 分布式表和本地表 ck的表分为两种: 分布式表 一个逻辑上的表, 可以理解为数据库中的视图, 一般查询都查询分布式表. 分布式表引擎会将我们的查询请求路由本地表进行查询, 然后进行汇总最终返回给 ...
- innodb数据库批量转换表引擎为MyISAM
2013.0106 innodb数据库批量转换表引擎为MyISAM 来源:本站原创 PHP, 数据库, 系统技术 超过488名童鞋围观 1条评论 <?php //连接数据库 $host='lo ...
- Mysql MyISAM数据库批量转换表引擎为Innodb
Mysql MyISAM数据库批量转换表引擎为Innodb 最近在做事物处理需要把表结构都改为带有支持事物的Innodb引擎格式, 把里面数据库 用户名.密码 等信息修改为你自己的,放在网站下运行即可 ...
随机推荐
- docker 安装es跟kibana
首先docker 查询es docker search elasticsearch 在docker pull elasticsearch:7.9.3 docker在查询 kibana docker ...
- Spring中BeanFactory与FactoryBean到底有什么区别?
一.BeanFactory BeanFactory是一个接口,它是Spring中工厂的顶层规范,是SpringIoc容器的核心接口,它定义了getBean().containsBean()等管理Bea ...
- python一键搭建ftp服务
from pyftpdlib.authorizers import DummyAuthorizer from pyftpdlib.handlers import FTPHandler from pyf ...
- Git常用命令大全,迅速提升你的Git水平
原博文 https://mp.weixin.qq.com/s/hYjGyIdLK3UCEVF0lRYRCg 示例 初始化本地git仓库(创建新仓库) git init ...
- 将后端返回的数据在jsp中拼接成table列表
//先下载jquery js文件 放入项目中 jsp文件内容 <%@ page language="java" pageEncoding="UTF-8"% ...
- java上下分页窗口流动布局
上下分页要用到 JSplitPane jSplitPane =new JSplitPane();//设定为拆分布局 效果图: show me code: import java.awt.event.C ...
- JAVA并发包——锁
1.java多线程中,可以使用synchronized关键字来实现线程间的同步互斥工作,其实还有个更优秀的机制来完成这个同步互斥的工作--Lock对象,主要有2种锁:重入锁和读写锁,它们比synchr ...
- spring boot 集成 Apache CXF 调用 .NET 服务端 WebService
1. pom.xml加入 cxf 的依赖 <dependency> <groupId>org.apache.cxf</groupId> <artifactId ...
- haproxy 支持 websocket
haproxy支持websocket feat 通过嗅探http请求中的Connection: Upgrade Upgrade: websocket头部,来自动识别是否是websocket连接,识别成 ...
- SpringCloud 源码系列(6)—— 声明式服务调用 Feign
SpringCloud 源码系列(1)-- 注册中心 Eureka(上) SpringCloud 源码系列(2)-- 注册中心 Eureka(中) SpringCloud 源码系列(3)-- 注册中心 ...