滚动更新和回滚部署在 Kubernetes 中的工作原理
公众号「架构成长指南」,专注于生产实践、云原生、分布式系统、大数据技术分享。
在过去的几年中,Kubernetes 在生产环境中被广泛使用,它通过其声明式 API 提供了大量解决方案,用于编排容器。
Kubernetes 的一个显著特性是其具有弹性的能力,能够执行滚动更新和回滚部署,而能够完成这些滚动更新和回滚,主要是由Deployment来实现的,下面就讲解下Deployment的相关知识
Deployment
Deployment是 Kubernetes 中处理工作负载(应用程序)的机制之一。它由 Kubernetes的Deployment Controller管理.。
在 Kubernetes 中,控制器是一个控制环,它负责观察集群的状态,然后根据需要做出或请求做出更改。每个控制器都试图让当前集群状态更接近所需的状态。
在这里的部署中,我们希望实现的状态其实是 pod 的状态,在 K8s 中一切都是声明式的,因此所需的状态会作为规范写入部署清单文件中。
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
如果pod实例出现故障或更新(状态改变),Kubernetes会对yaml中声明状态和实际状态之间的差异做出响应,进行修正,即与定义的部署状态相匹配。
Deployment的内部工作原理
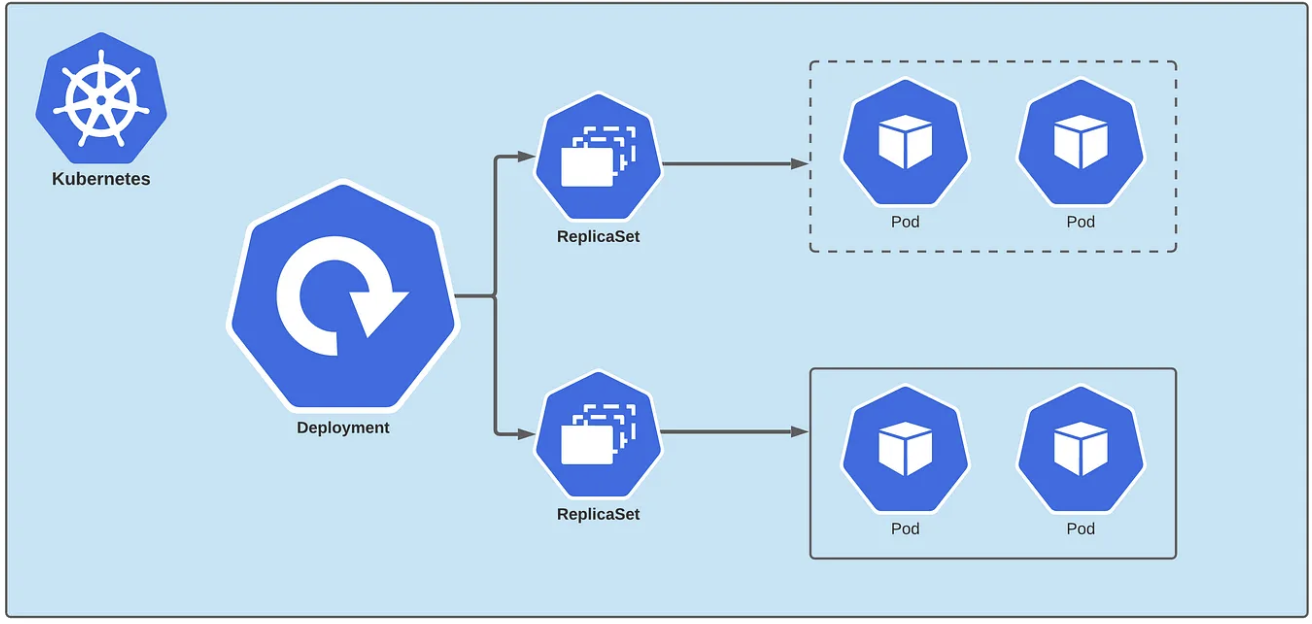
Deployment是对 ReplicaSet 的抽象。在内部,部署创建了一个ReplicaSet,而 ReplicaSet 则在集群上创建了一组 Pod。因此,ReplicaSet 其实实在管理我们的 Pod 的副本。
总之,控制器会读取Deployment配置声明,将 pod 配置转发给 ReplicaSet,然后用适当的副本创建Pod。
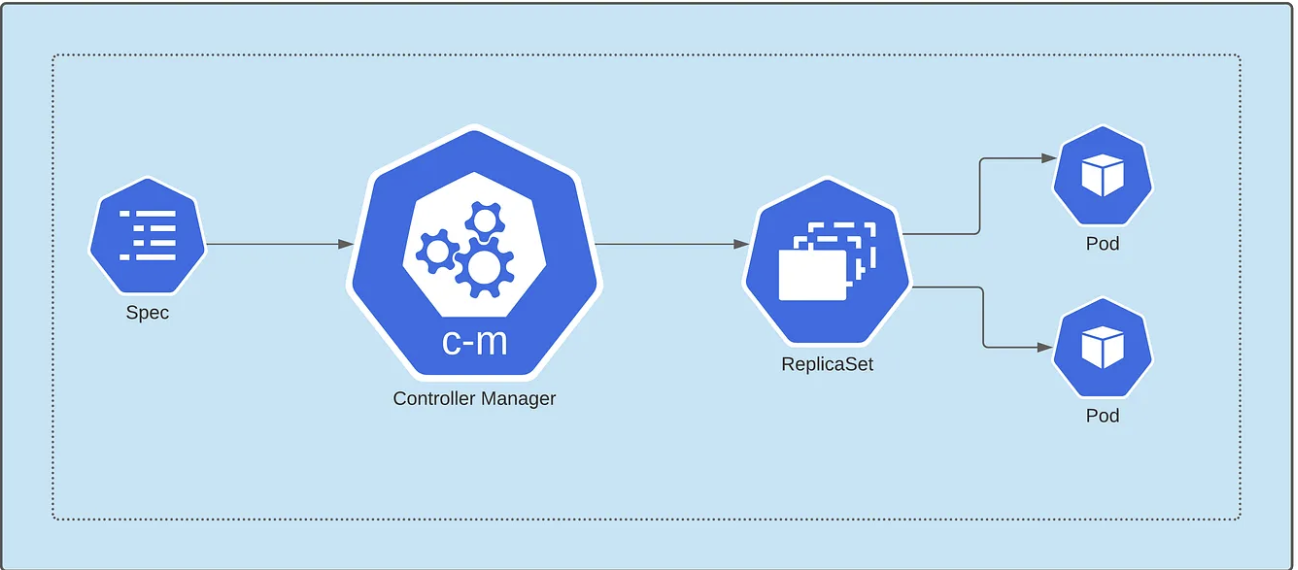
Deployment > ReplicaSet > Pods
滚动部署
Kubernetes 承诺零停机时间,其背后的原理之一就是滚动部署。通过滚动部署,Kubernetes可以保证在部署更新 pod 时不会中断 pod 的流量
示例
下面让我们亲自操作一下Kubernetes,来看看这些部署策略。
Create Deployment
在前面的章节中,写过一个Kubernetes的部署手册,如果没有Kubernetes集群的同学,请进行参考
最佳实践-使用RKE快速部署K8S集群
$ kubectl create deployment test-nginx --image=nginx:1.18-alpine
如前所述,部署会创建一个ReplicaSet,然后是Pod。您可以使用
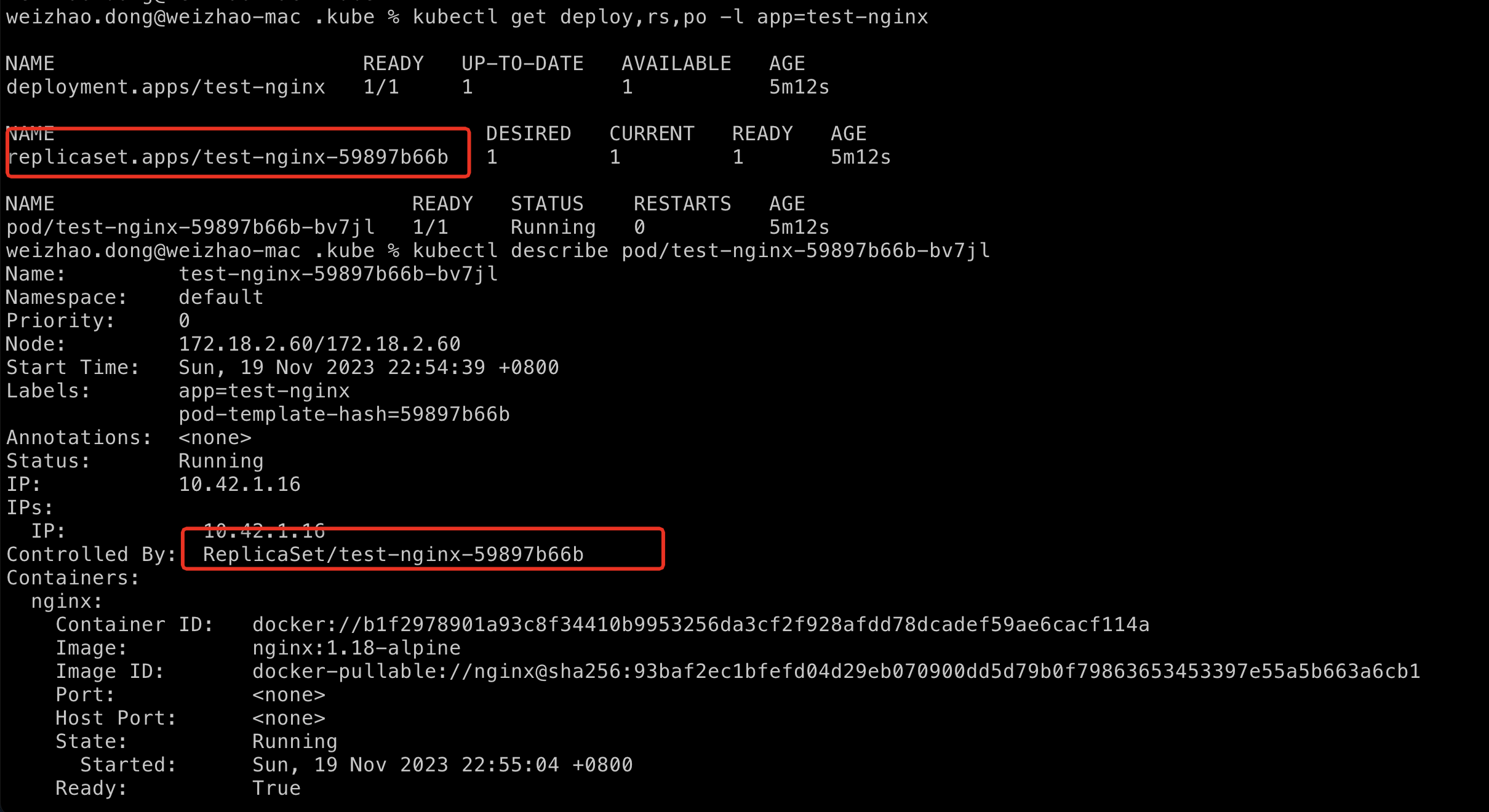
$ kubectl get deploy,rs,po -l app=test-nginx
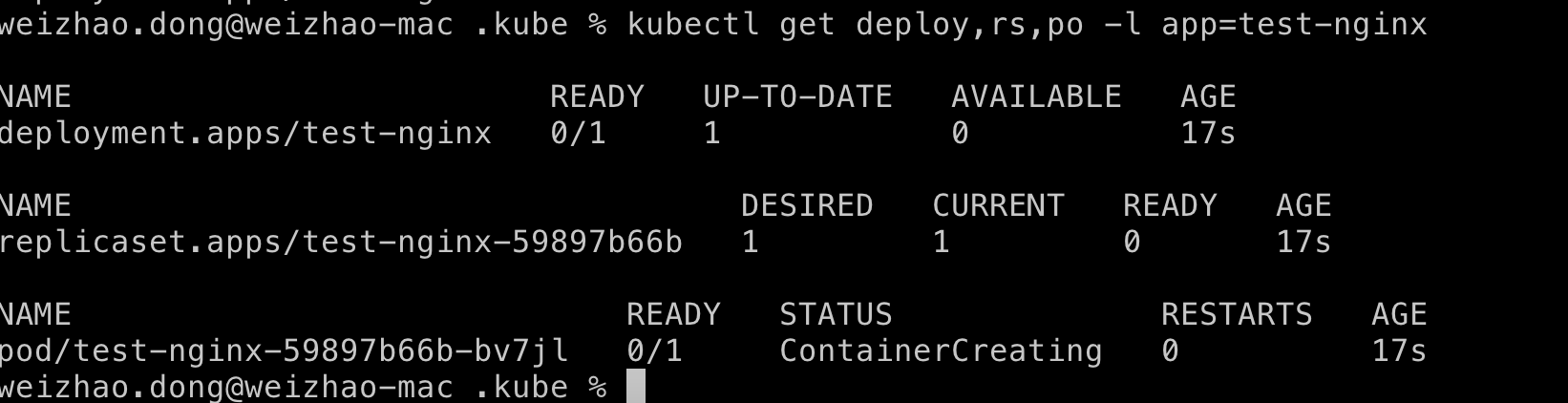
可以检查Deployment是否创建了ReplicaSet。
$ kubectl describe <replica-set-name>
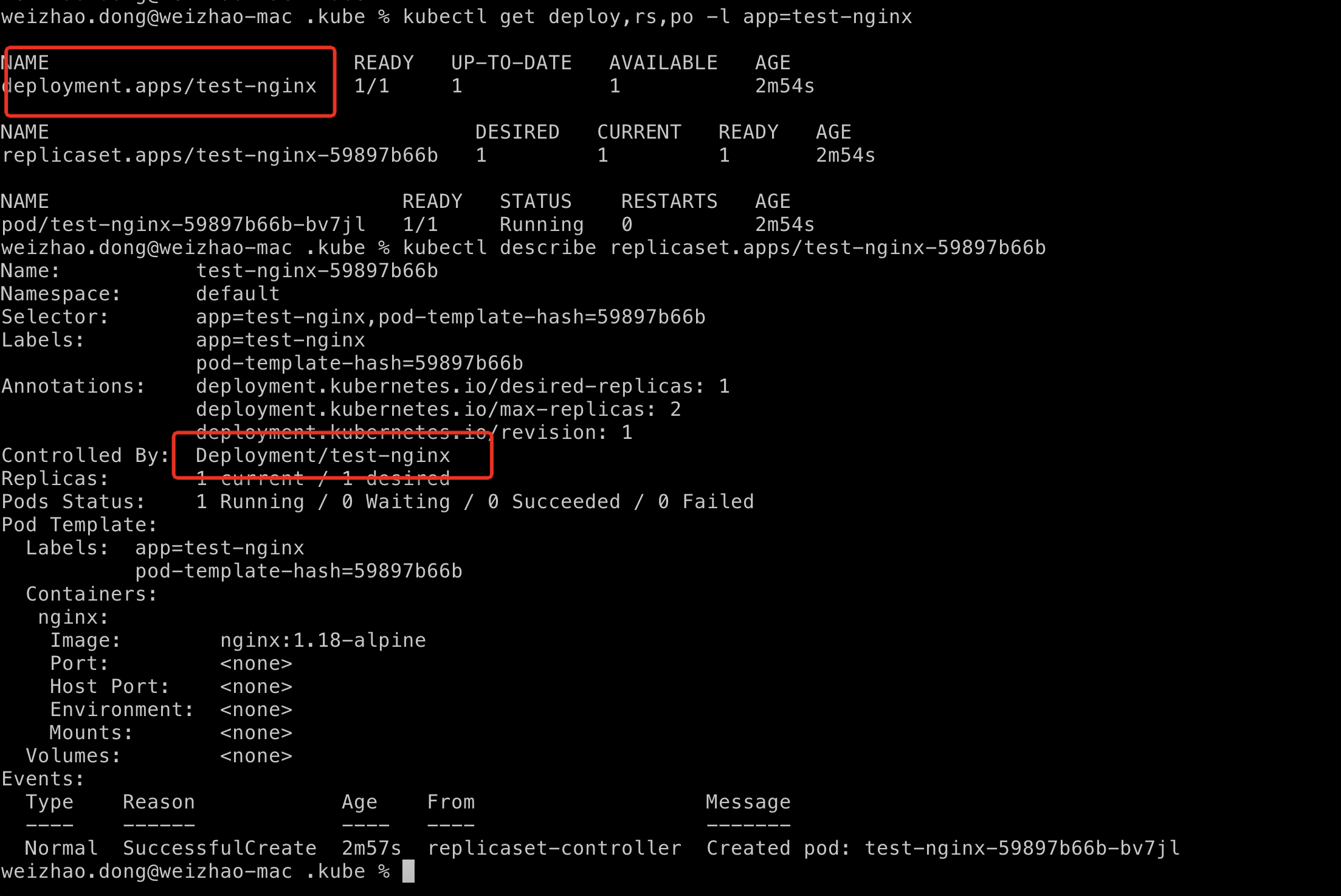
同时我们还可以看一下是否是ReplicaSet创建了pod
$ kubectl describe <pod-name>
扩容 Deployment
让我们将部署扩展到 3 个 nginx pod 实例。
$ kubectl scale deploy test-nginx --replicas=3
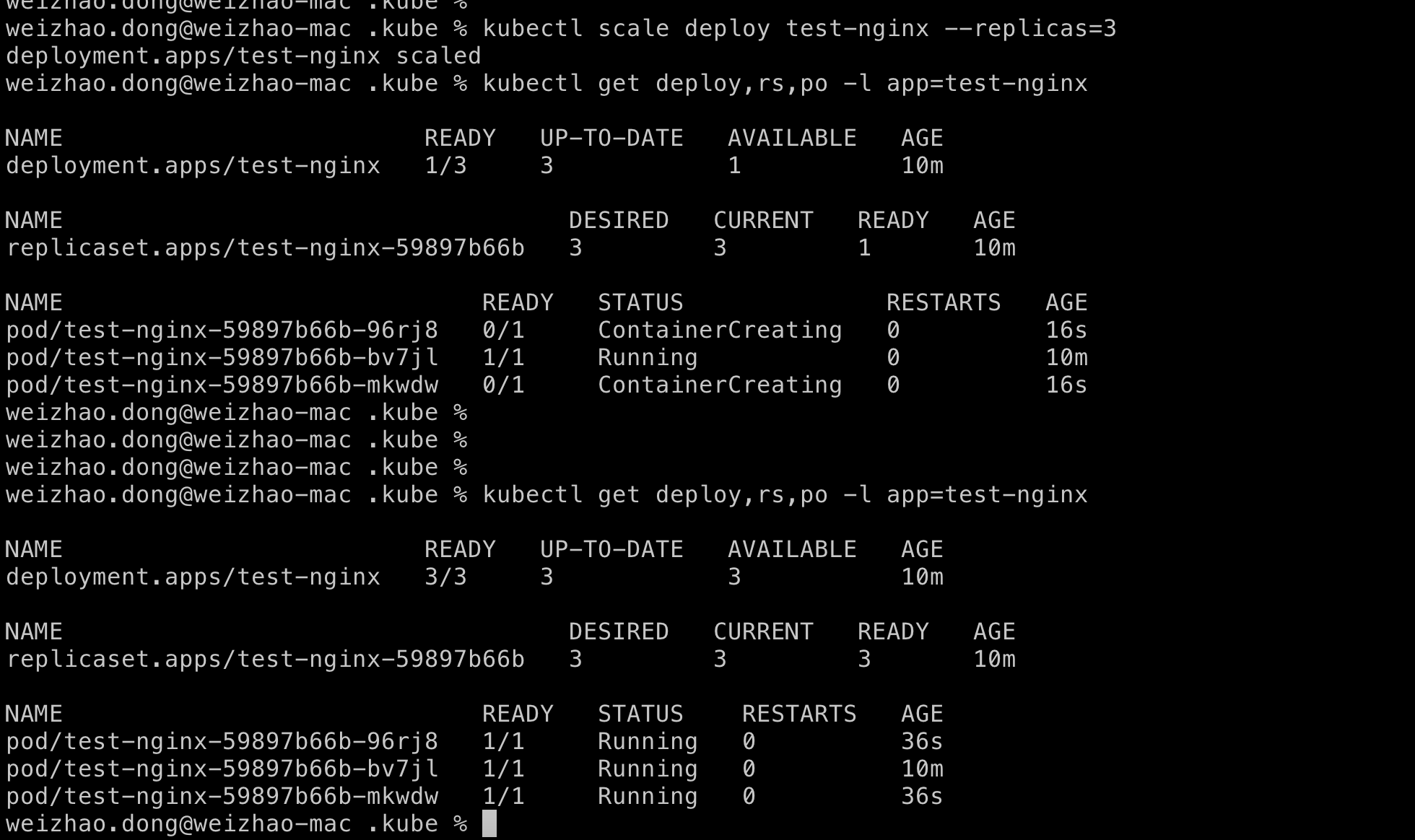
现在,我们的集群上已经有了多个pod实例了,下面让我们试试部署策略。
滚动更新部署
假设我们在使用nginx的1.18-alpine版本遇到了一些问题,而1.19-alpine版本解决了这些问题,因此我们需要让pod更新为新版本镜像。
通过更新当前 pod 的镜像(状态变更),Kubernetes 将进行新的部署。
$ kubectl set image deploy test-nginx nginx=nginx:1.19-alpine
设置新镜像后,我们可以看到旧的 pod 被终止,新的 pod 被创建。
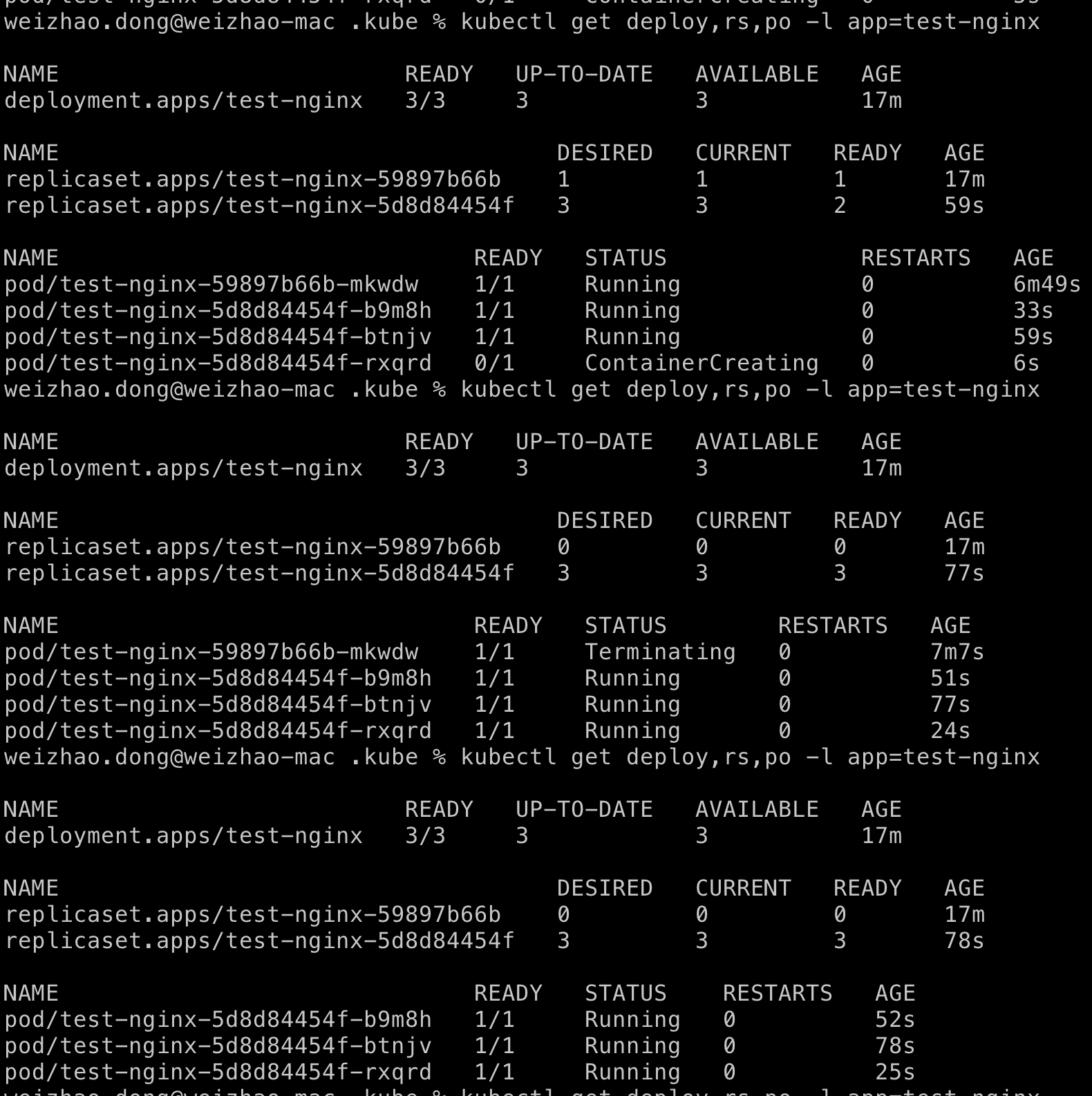
我们可以看到Kubernetes在更新过程中,在为新 pod 创建完整的副本之前,最后一个旧 pod 不会被终止。旧 pod 也会有一个宽限期,确保其服务的流量在一定时间内不会断开,直到请求可以安全地路由到新创建的 pod。
虽然这么说但是有时候
Kubernetes认为的pod启动就绪,并不是我们期望的启动并就绪,这个地方需要结合自身系统进行判断,后面的文章会进行讲解
可以看到nginx的版本已经更新完成
回滚部署版本
假设新的nginx更新后比上一个版本问题更多,而我们现在意识到旧版本的还是更靠谱,这时候需要回滚到之前的nginx版本
但该怎么做?你可能已经注意到,现在有两个ReplicaSets。这与我们前面的说明部署模式是一样的,我们更新部署,它就会创建一个新的ReplicaSet,从而创建新的Pod。
Kubernetes 默认最多保留 10 个 ReplicaSet 的历史记录,我们可以在部署规范中使用revisionHistoryLimit 来更新这一数字。
这些历史记录将作为滚动跟踪,最新版本的才是目前使用的。
到目前为止,我们已经对部署 test-nginx 做了两次更改,因此部署历史记录应该是两次。
$ kubectl get rs|grep test-nginx
$ kubectl rollout history deploy test-nginx
$ kubectl rollout history deploy test-nginx --revision=1
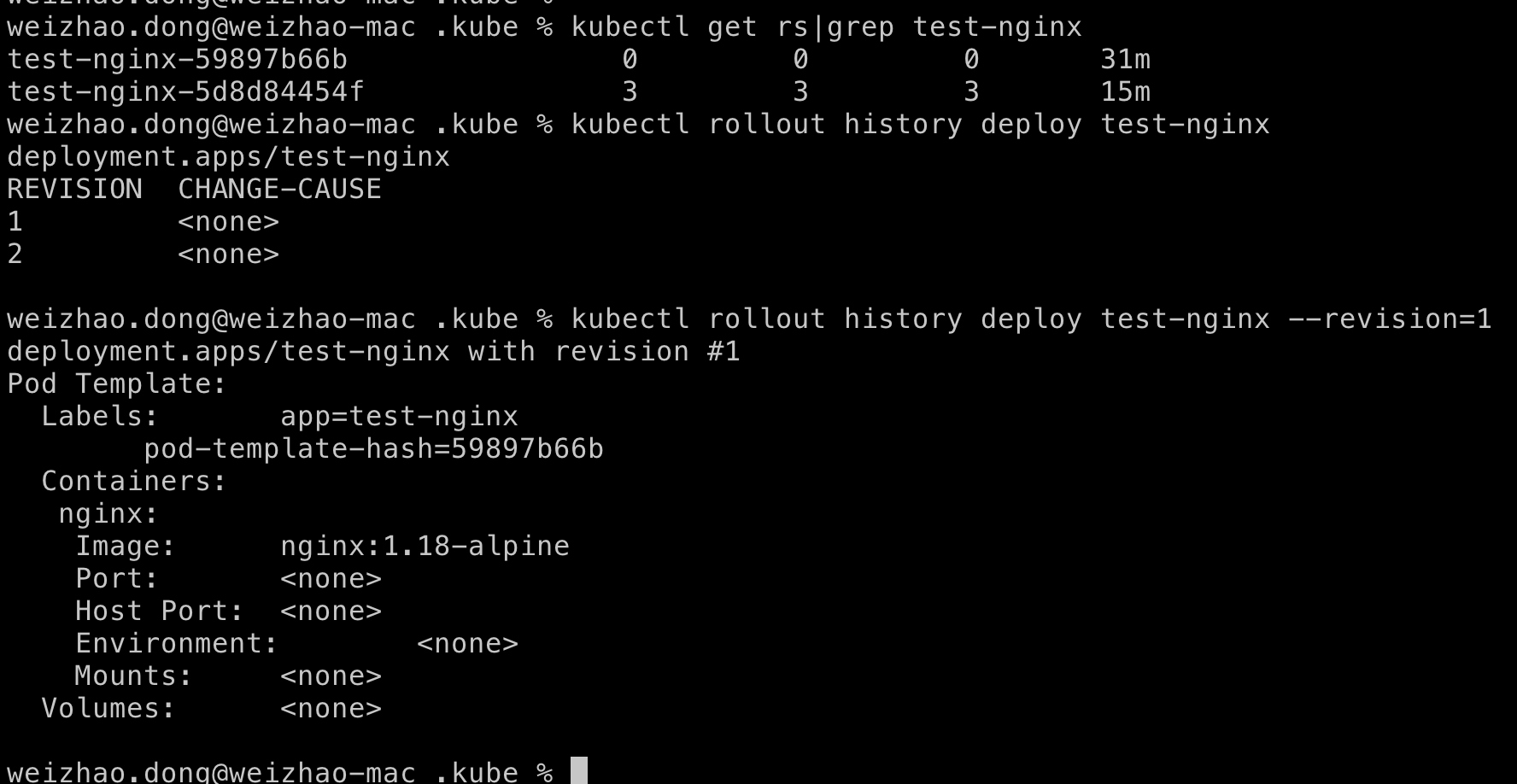
可以看到revision=1对应的是1.18-alpine,下面让我们回滚到上一个版本即1.18-alpine
$ kubectl rollout undo deploy test-nginx --to-revision=1
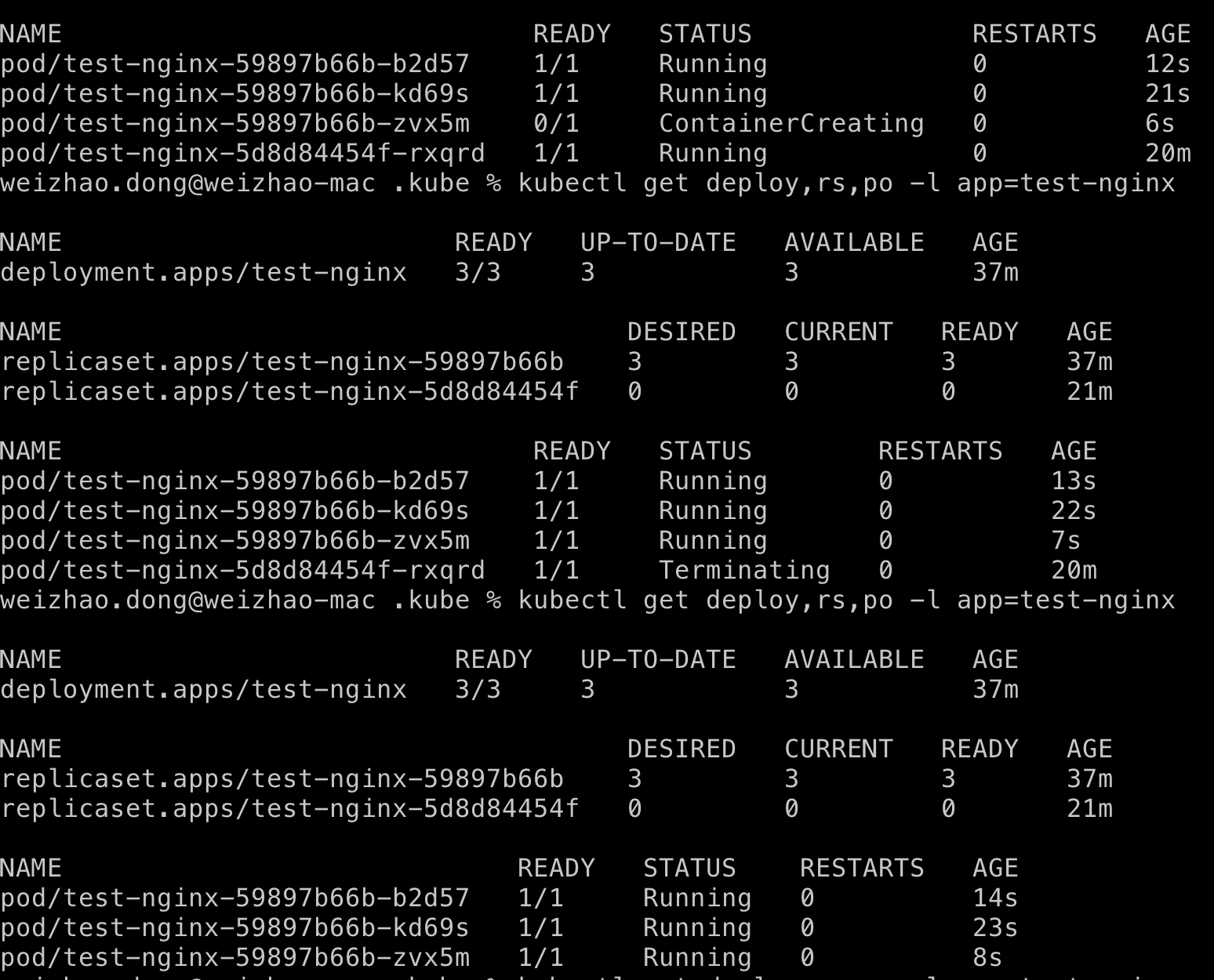
与 滚动更新部署一样,回滚部署也会终止当前 pod,并用包含来自 Revision 1 的 Pod 替换它们。
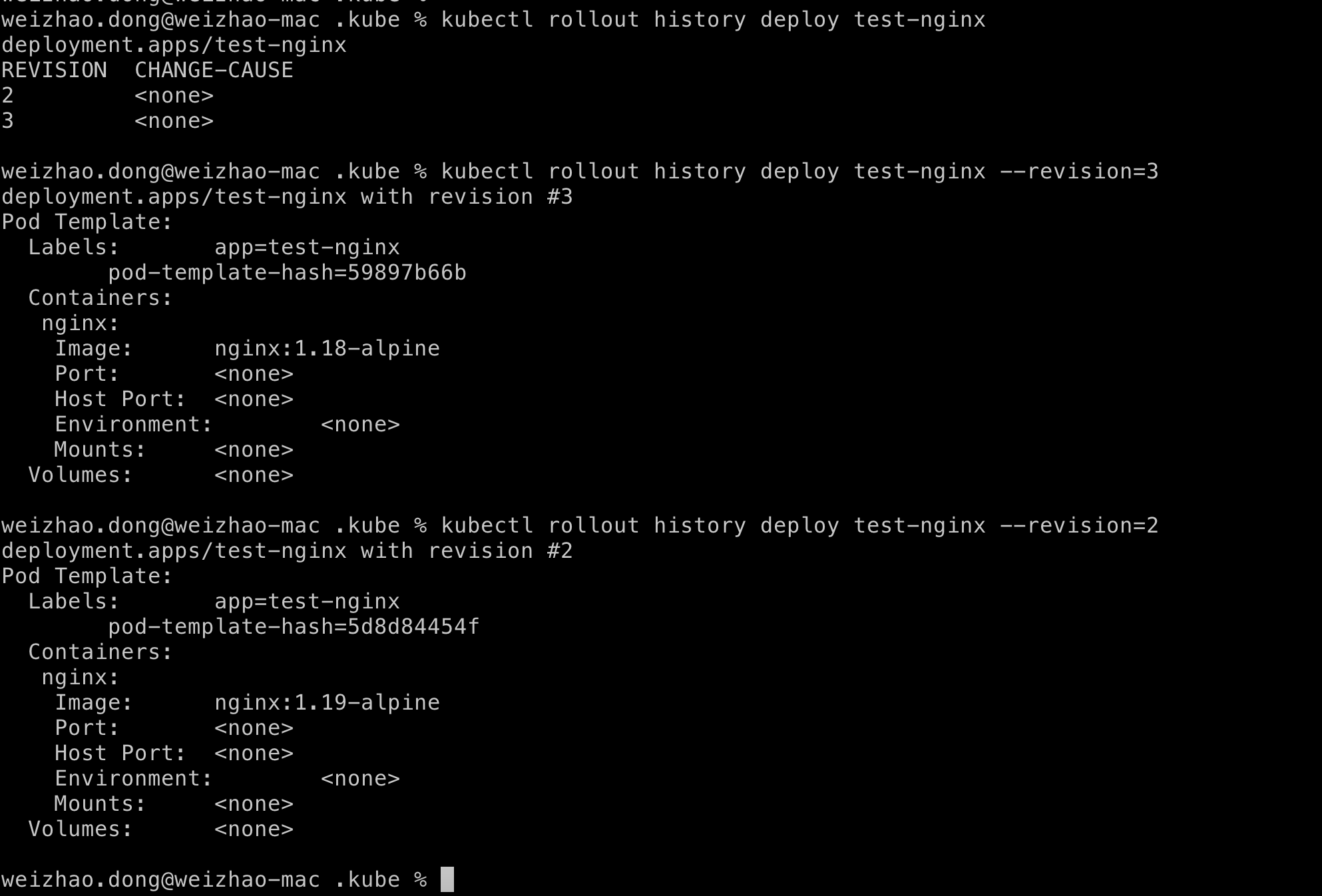
如果再次查看部署历史,就会发现修订版 1 已被用于创建最新的 pod,并标记为修订版 3。
在多个修订版中重复维护同一规范是没有意义的,所以Kubernetes 删除了修订版 1,因为我们已经有了同一规范的最新修订版 3。
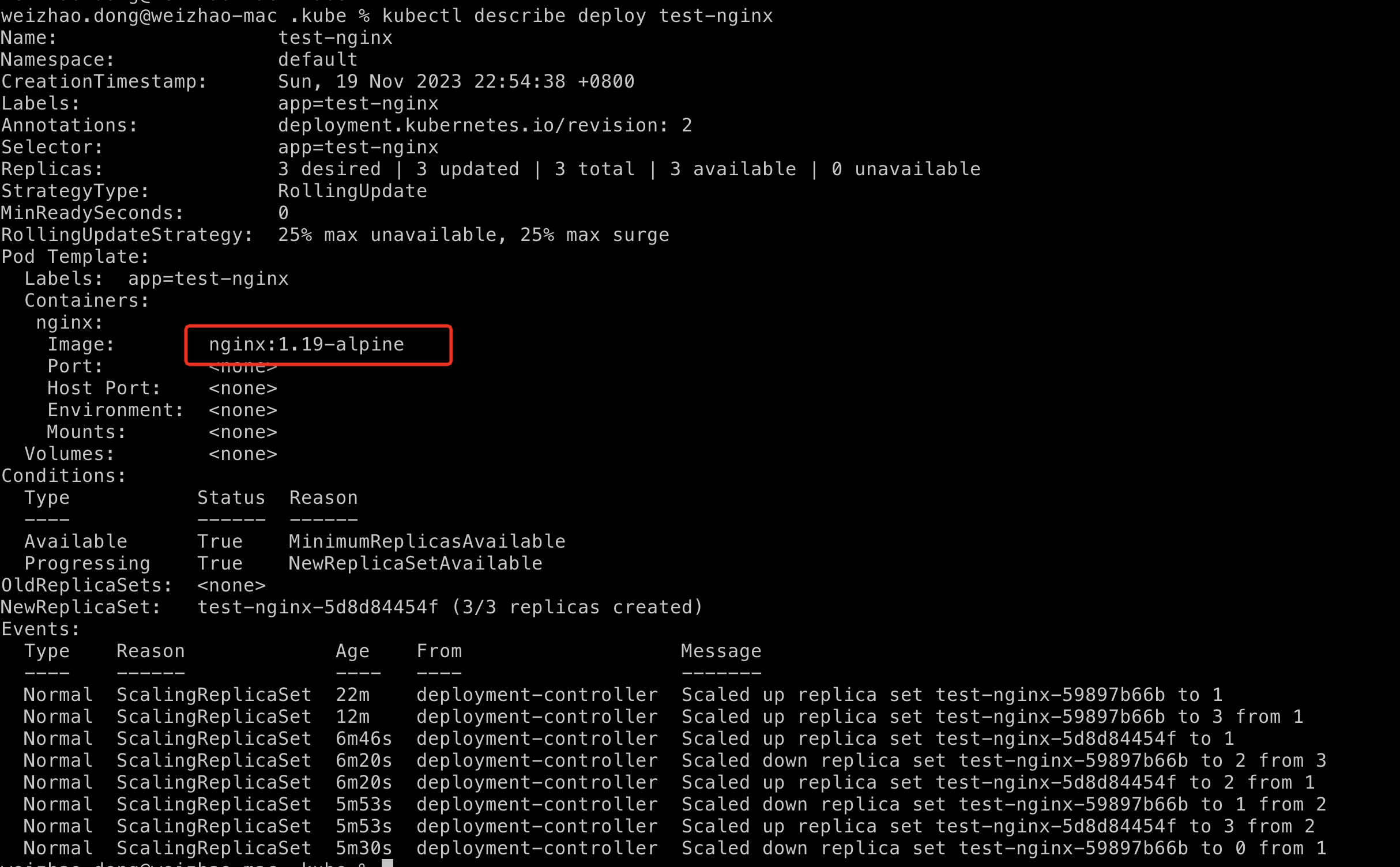
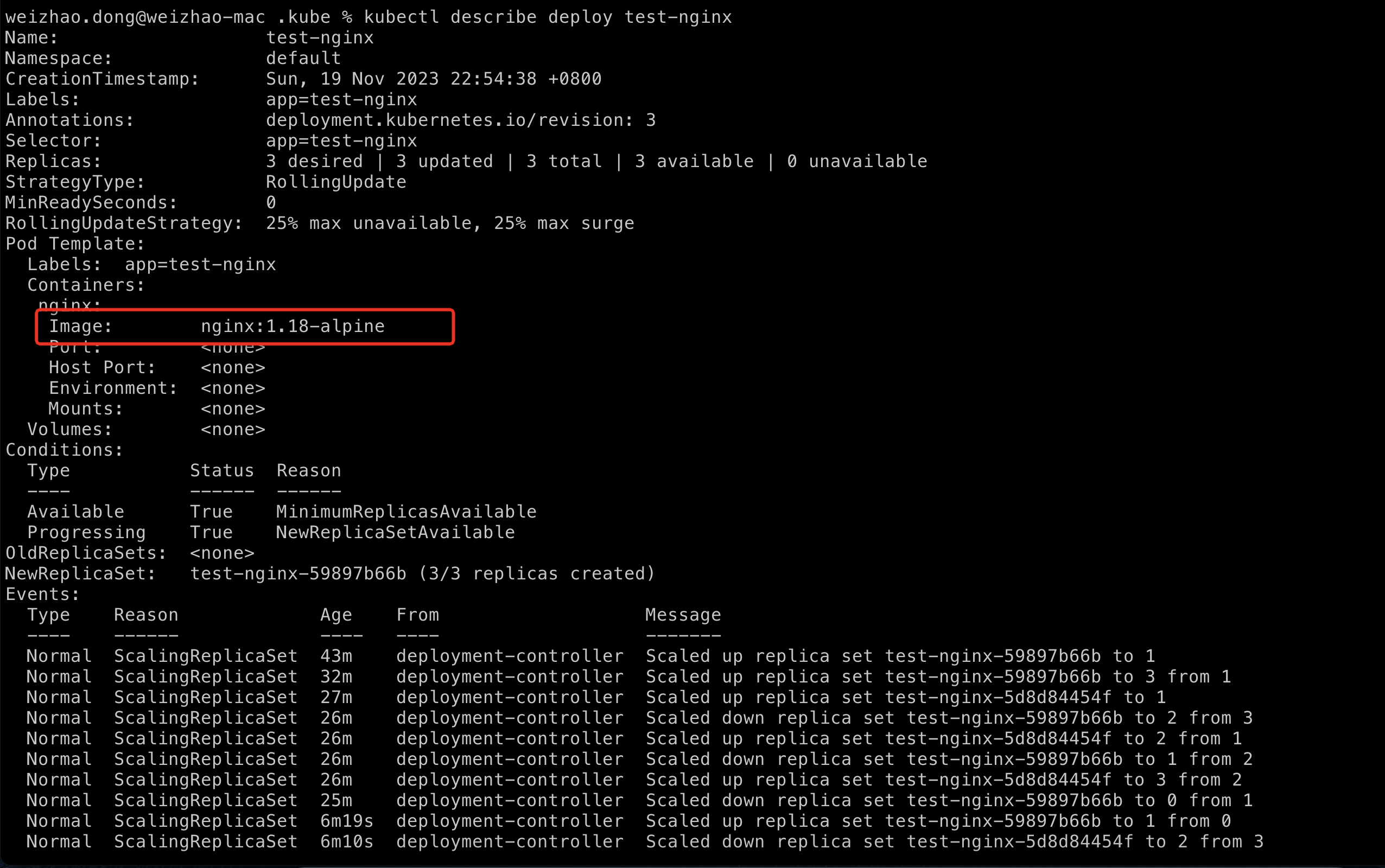
现在我们已经回滚到了1.18-alpine版本,通过describe部署可以进行验证。
$ kubectl describe deploy test-nginx
总结
通过 Kubernetes,我们可以利用这些策略轻松控制应用程序的部署。以上只是对滚动和回滚更新部署工作原理的简单介绍。在实际工作中,我们很少手动完成所有这些步骤,我们一般会交给 CI/CD平台去做这些事情。
滚动更新和回滚部署在 Kubernetes 中的工作原理的更多相关文章
- Docker Swarm(八)滚动更新、回滚服务
滚动更新.回滚服务 默认情况下, swarm一次只更新一个副本,并且两个副本之间没有等待时间,我们可以通过: # 定义并行更新的副本数量--update-parallelism# 定义滚动更新的时间间 ...
- deployment控制pod进行滚动更新以及回滚
更新pod镜像两种方式: 方式一:kubectl set image deployment/${deployment name} ${container name}=${image} 例: kubec ...
- linux运维、架构之路-K8s滚动更新及回滚
一.滚动更新 应用程序一次只更新一小部分副本,更新成功后,再更新更多的副本,最终完成所有副本的更新. 滚动更新的优点:零停机,整个更新过程始终有副本在运行,从而保证了业务的连续性. 1. ...
- Kubernetes:更新与回滚
Blog:博客园 个人 除了创建,Deployment 提供的另一个重要的功能就是更新应用,这是一个比创建复杂很多的过程.想象一下在日常交付中,在线升级是一个很常见的需求,同时应该尽量保证不能因为升级 ...
- Docker Kubernetes 容器更新与回滚
Docker Kubernetes 容器更新与回滚 环境: 系统:Centos 7.4 x64 Docker版本:18.09.0 Kubernetes版本:v1.8 管理节点:192.168.1.79 ...
- JDBC03 利用JDBC实现事务提交与回滚【调用Connection中的方法实现事务管理】
目录 1 Connection中的重用方法 2 JDBC事务管理经典案例 1 Connection类中常用的方法回顾 1.1 Statement createStatement() throws SQ ...
- kubernetes大概的工作原理
先放一张Kubernetes的架构图: 整体来看,是一个老大,多个干活的这种结构,基本上所有的分布式系统都是这样,但是里面的组件名称就纷繁复杂,下面将一一解析. 1.元数据存储与集群维护 作为一个集群 ...
- Docker Kubernetes 介绍 or 工作原理
Kubernetes 介绍 Kubernetes是Google在2014年6月开源的一个容器集群管理系统,使用Go语言开发,Kubernetes也叫K8S. K8S是Google内部一个叫Borg的容 ...
- Kubernetes API server工作原理
作为Kubernetes的使用者,每天用得最多的命令就是kubectl XXX了. kubectl其实就是一个控制台,主要提供的功能: 1. 提供Kubernetes集群管理的REST API接口,包 ...
- 【IntelliJ IDEA】idea部署服务到Tomcat的工作原理
参考地址: https://blog.csdn.net/qq_41116058/article/details/81435084 为什么idea部署服务到tomcat时候,一定要修改Applicati ...
随机推荐
- 【教程】青少年CTF机器人使用教程
前言 本期教程适用于版本号为2.0.1-Beta的青少年CTF机器人,其他版本可能与当前版本不同. 由于之前版本的机器人重构,所以我们细化了本次的机器人逻辑,并且对机器人的功能进行了一些升级. 机器人 ...
- javascript事件循环机制及面试题详解
javascript是单线程执行的程序,也就是它只有一条主线,所有的程序都是逐行"排队"执行,在这种情况下可能存在一些问题,比如说setTimeout.ajax等待执行的时间较长, ...
- 一文理解GIT的代码冲突
对于GIT,不知道有没有人和我一样,很长时间都是小心翼翼.紧张兮兮,生怕一不小心,自己辛苦写的代码没了. 特别是代码冲突,更是难到我无法理解,每次都要求助于百度,跟着人家的教程一步步解决,下一次还是这 ...
- SpringBoot3集成Kafka
目录 一.简介 二.环境搭建 1.Kafka部署 2.Kafka测试 3.可视化工具 三.工程搭建 1.工程结构 2.依赖管理 3.配置文件 四.基础用法 1.消息生产 2.消息消费 五.参考源码 标 ...
- 完全卸载MySQL服务的方法
1. 重新运行安装文件,单击remove移除mysql.此时安装目录中的文件没有完全移除,需要手动删除安装目录的Mysql文件夹. 2. 如果MySQL服务没有移除的话,以管理员方式运行cmd命令:s ...
- 使用 Python ssh 远程登陆服务器的最佳方案
在使用 Python 写一些脚本的时候,在某些情况下,我们需要频繁登陆远程服务去执行一次命令,并返回一些结果. 在 shell 环境中,我们是这样子做的. sshpass -p ${passwd} s ...
- FastGPT 接入飞书(不用写一行代码)
FastGPT V4 版本已经发布,可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景,例如联网谷歌搜索,操作数据库等等,功能非常强大,还没用过的同学赶紧去试试吧. 飞书相比同类产品算是 ...
- windows系统上的大文件拆分合并
上周碰到一个并不算很大的问题,但是也有记录的价值. 从公司带出来的离线补丁包需要传到客户服务器上,但是被告知并不能在现场机器上插U盘,会触发告警.上传只能把U盘上的内容通过私人笔记本刻录到光盘上,插光 ...
- mpi转以太网连接300PLC实现以太网通信配置方法
西门子S7300PLC连接MPI-ETH-XD1.0实现以太网通信配置方法 产品简介 兴达易控MPI-ETH-XD1.0用于西门子S7-200/SMART S7-200/S7-300/S7-400/西 ...
- Github 组合搜索开源项目 (超详细)
例如搜索 Spring Boot 相关项目 spring boot (最简单最常用) in:name spring boot (匹配项目名字) in:name spring boot stars: ...