2D KD-Tree实现
KD-tree
1.使用背景
在项目中遇到一个问题: 如何算一个点到一段折线的最近距离~折线的折点可能有上千个, 而需要检索的点可能出现上万的数据量, 的确是个值得思考的问题~
2.暴力解法
有个比较直观的方法: 计算点到折线的每段的距离, 然后暴力找出最短的那段~得到解..不过这种O(n)的复杂度方法显然遇到大数据量的时候会严重拖累服务器的性能.
3.K临近算法-数据结构
knn给了一个非常巧妙的启示用于求近似解, 可以通过2D-tree(k=2)得到.
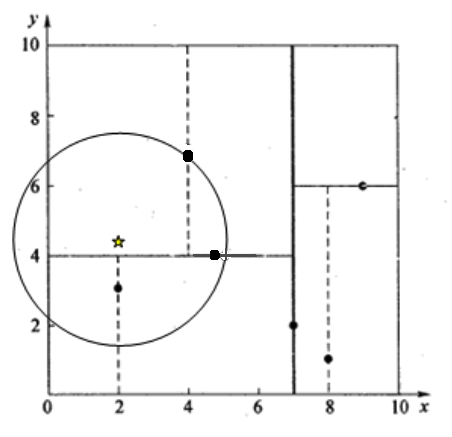
举一个稍微复杂的例子,我们来查找点(2,4.5),在(7,2)处测试到达(5,4),在(5,4)处测试到达(4,7),然后search_path中的结点为<(7,2), (5,4), (4,7)>,从search_path中取出(4,7)作为当前最佳结点nearest, dist为3.202;
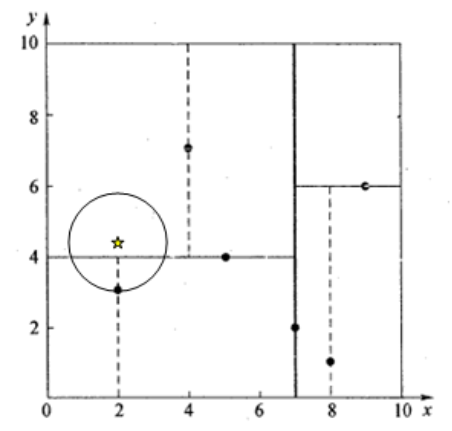
然后回溯至(5,4),以(2,4.5)为圆心,以dist=3.202为半径画一个圆与超平面y=4相交,如下图,所以需要跳到(5,4)的左子空间去搜索。所以要将(2,3)加入到search_path中,现在search_path中的结点为<(7,2), (2, 3)>;另外,(5,4)与(2,4.5)的距离为3.04 < dist = 3.202,所以将(5,4)赋给nearest,并且dist=3.04。
回溯至(2,3),(2,3)是叶子节点,直接平判断(2,3)是否离(2,4.5)更近,计算得到距离为1.5,所以nearest更新为(2,3),dist更新为(1.5)
回溯至(7,2),同理,以(2,4.5)为圆心,以dist=1.5为半径画一个圆并不和超平面x=7相交, 所以不用跳到结点(7,2)的右子空间去搜索。
至此,search_path为空,结束整个搜索,返回nearest(2,3)作为(2,4.5)的最近邻点,最近距离为1.5。
4.代码实现
KDTree.h
#define lson (rt << 1)//左节点
#define rson (rt << 1 | 1)//右节点 #include <vector>
#include <algorithm>
#include <cmath> const int N = 50005;
const int k = 2; //2D-tree struct Node {
float feature[2];//feature[0] = x, feature[1] = y
static int idx;
Node(float x0, float y0) {
feature[0] = x0;
feature[1] = y0;
}
bool operator < (const Node &u) const {
return feature[idx] < u.feature[idx];
}
//TOOD =hao
Node() {
feature[0] = 0;
feature[0] = 0;
}
}; class KDTree {
public:
KDTree();
~KDTree();
void clean();
int read_in(float* ary_x, float* ary_y, int len);
void build(int l, int r, int rt, int dept);
int find_nearest_point(float x, float y, Node& result, float& dist);
float distance(const Node& x, const Node& y);
private:
void query(const Node& p, Node& res, float& dist, int rt, int dept);
std::vector<Node> _data;//用vector模拟数组
std::vector<int> _flag;//判断是否存在
int _idx;
std::vector<Node> _find_nth;
};
KD-tree.cpp
#include "KDTree.h"
int Node::idx = 0;
KDTree::KDTree() {
_data.reserve(N * 4);
_flag.reserve(N * 4);//TODO init
} KDTree::~KDTree() {} int KDTree::read_in(float* ary_x, float* ary_y, int len) {
_find_nth.reserve(N * 4);
for (int i = 0; i < len; ++i) {
Node tmp(ary_x[i], ary_y[i]);
_find_nth.push_back(Node(ary_x[i], ary_y[i]));
}
for (int i = 0; i < N * 4; ++i) {
Node tmp;
_data.push_back(tmp);
_flag.push_back(0);
}
build(0, len - 1, 1, 0);
return 0;
} void KDTree::clean() {
_find_nth.clear();
_data.clear();
_flag.clear();
} //建立kd-tree
void KDTree::build(int l, int r, int rt, int dept) {
if (l > r) return;
_flag[rt] = 1; //表示标号为rt的节点存在
_flag[lson] = _flag[rson] = -1; //当前节点的孩子暂时标记不存在
int mid = (l + r + 1) >> 1;
Node::idx = dept % k; //按照编号为idx的属性进行划分
std::nth_element(_find_nth.begin() + l, _find_nth.begin() + mid, _find_nth.begin() + r + 1);
_data[rt] = _find_nth[mid];
build(l, mid - 1, lson, dept + 1); //递归左子树
build(mid + 1, r, rson, dept + 1);
} int KDTree::find_nearest_point(float x, float y, Node &res, float& dist) {
Node p(x, y);
query(p, res, dist, 1, 0);
return 0;
} //查找kd-tree距离p最近的点
void KDTree::query(const Node& p, Node& res, float& dist, int rt, int dept) {
if (_flag[rt] == -1) {
return;
}//不存在的节点不遍历
float tmp_dist = distance(_data[rt], p);
bool fg = false; //用于标记是否需要遍历右子树
int dim = dept % k; //和建树一样, 保证相同节点的dim值不变
int x = lson;
int y = rson;
if (p.feature[dim] >= _data[rt].feature[dim]) {
std::swap(x, y); //数据p的第dim个特征值大于等于当前的数据,则需要进入右子树
}
if (~_flag[x]) {
query(p, res, dist, x, dept + 1); //节点x存在, 则进入子树继续遍历
} if (tmp_dist < dist) { //如果找到更小的距离, 则替换目前的结果dist
res = _data[rt];
dist = tmp_dist;
}
tmp_dist = (p.feature[dim] - _data[rt].feature[dim]) * (p.feature[dim] - _data[rt].feature[dim]);
if (tmp_dist < dist) { //还需要继续回溯
fg = true;
}
if (~_flag[y] && fg) {
query(p, res, dist, y, dept + 1);
}
} //计算两点间的距离的平方
float KDTree::distance(const Node& x, const Node& y) {
float res = 0;
for (int i = 0; i < k; i++) {
res += (x.feature[i] - y.feature[i]) * (x.feature[i] - y.feature[i]);
}
return res;
}
自测暂无发现bug~
参考文章:
(http://blog.csdn.net/acdreamers/article/details/44664645/ “KD-tree实现”)
(http://blog.csdn.net/silangquan/article/details/41483689/ “详解KD-tree”)
感谢巨巨们的分享
2D KD-Tree实现的更多相关文章
- k-d tree算法
k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据结构.主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索). 应用背景 SIFT算法中做特征点匹配的时候就会利用到k ...
- [转载]kd tree
[本文转自]http://www.cnblogs.com/eyeszjwang/articles/2429382.html k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据 ...
- 初涉k-d tree
听说k-d tree是一个骗分的好东西?(但是复杂度差评??? 还听说绍一的kdt常数特别小? KDT是什么 KDT的全称是k-degree tree,顾名思义,这是一种处理多维空间的数据结构. 例如 ...
- 【数据结构与算法】k-d tree算法
k-d tree算法 k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据结构.主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索). 应用背景 SIFT算法中做特征点 ...
- 【学习笔记】K-D tree 区域查询时间复杂度简易证明
查询算法的流程 如果查询与当前结点的区域无交集,直接跳出. 如果查询将当前结点的区域包含,直接跳出并上传答案. 有交集但不包含,继续递归求解. K-D Tree 如何划分区域 可以借助下文图片理解. ...
- P4169-CDQ分治/K-D tree(三维偏序)-天使玩偶
P4169-CDQ分治/K-D tree(三维偏序)-天使玩偶 这是一篇两种做法都有的题解 题外话 我写吐了-- 本着不看题解的原则,没写(不会)K-D tree,就写了个cdq分治的做法.下面是我的 ...
- 【数据结构】K-D Tree
K-D Tree 这东西是我入坑 ICPC 不久就听说过的数据结构,但是一直没去学 QAQ,终于在昨天去学了它.还是挺好理解的,而且也有用武之地. 目录 简介 建树过程 性质 操作 例题 简介 K-D ...
- AOJ DSL_2_C Range Search (kD Tree)
Range Search (kD Tree) The range search problem consists of a set of attributed records S to determi ...
- k-d tree 学习笔记
以下是一些奇怪的链接有兴趣的可以看看: https://blog.sengxian.com/algorithms/k-dimensional-tree http://zgjkt.blog.uoj.ac ...
- 【BZOJ-2648&2716】SJY摆棋子&天使玩偶 KD Tree
2648: SJY摆棋子 Time Limit: 20 Sec Memory Limit: 128 MBSubmit: 2459 Solved: 834[Submit][Status][Discu ...
随机推荐
- flutter填坑之旅(环境搭建篇--mac系统)
上次配置过Mac到flutter环境,但是由于最近系统更新了,什么都没了又得从新配置,发现自己竟然好多都忘记了,看来还是得把它记下来才行 在Mac上安装并运行Flutter 最低要求: 操作系统:ma ...
- < Python全景系列-9 > Python 装饰器:优雅地增强你的函数和类
欢迎来到我们的系列博客<Python全景系列>第九篇!在这个系列中,我们将带领你从Python的基础知识开始,一步步深入到高级话题,帮助你掌握这门强大而灵活的编程语法.无论你是编程新手,还 ...
- 开源超全Lotus Domino Xpages 开发资料,Domino最新资料,lotus资料,xpages资料,Domino开源信息下载
十年Domino资料,不断累积,精彩展示,从维护到开发,从CS到BS再变xpage,都是一步步过来,让Domino后台数据在在多个平台绽放 把这些开发技术文档分享出来,希望通过这个资料,为大家学习开发 ...
- 解码器 | 基于 Transformers 的编码器-解码器模型
基于 transformer 的编码器-解码器模型是 表征学习 和 模型架构 这两个领域多年研究成果的结晶.本文简要介绍了神经编码器-解码器模型的历史,更多背景知识,建议读者阅读由 Sebastion ...
- Excel DDE Commands
! https://zhuanlan.zhihu.com/p/635569763 Excel DDE Commands 连接参数 Application: Excel Topic: System: 整 ...
- AB实验:科学归因与增长的利器
第一章 AB实验的基本原理和应用 AB实验的相关概念: 3个基本参数:实验参与单元.实验控制参数.实验指标 2个核心价值:验证因果关系.量化策略效果 2个关键特性:先验性.并行性 基本流程:分流 -& ...
- 【论文阅读】CYCADA CYCLE-CONSISTENT ADVERSARIAL DOMAIN ADAPTATION
github code CyCADA论文中,定义了一种问题--无监督适配,即仅提供源数据 \(X_S\) 和源标签 \(Y_S\),以及源域目标数据\(X_T\),没有目标标签或者不利用它.问题的目的 ...
- 好的,以下是我为您拟定的自然语言处理(NLP)领域的100篇热门博客文章标题,以逻辑清晰、结构紧凑、简单易懂的
目录 1. 引言 2. 技术原理及概念 3. 实现步骤与流程 4. 应用示例与代码实现讲解 1. 机器翻译 2. 文本分类 3. 情感分析 5. 优化与改进 6. 结论与展望 好的,以下是我为您拟定的 ...
- 使用Kettle定时从数据库A刷新数据到数据库B
一.需求背景 由于项目场景原因,需要将A库(MySQL)中的表a.表b.表c中的数据定时T+1 增量的同步到B库(MySQL).这里说明一下,不是数据库的主从备份,就是普通的数据同步.经过技术调研,发 ...
- java BigDecimal解决浮点数的精度丢失和大数计算问题
java BigDecimal解决浮点数的精度丢失和大数计算问题 抛出浮点数问题: 先考个题,输入什么? System.out.println(0.1 + 0.2); 答案:0.30000000000 ...