手绘流程图讲解spark是如何实现集群的高可用
摘要:本文讲述spark是怎么针对master、worker、executor的异常情况做处理的。
本文分享自华为云社区《图解spark是如何实现集群的高可用》,作者:breakDawn。
我们看下spark是怎么针对master、worker、executor的异常情况做处理的。
容错机制-exeuctor退出
首先可以假设worker中的executor执行任务时,发送了莫名其妙的异常或者错误,然后对应线程消失了。
我们看这个时候会做什么事情
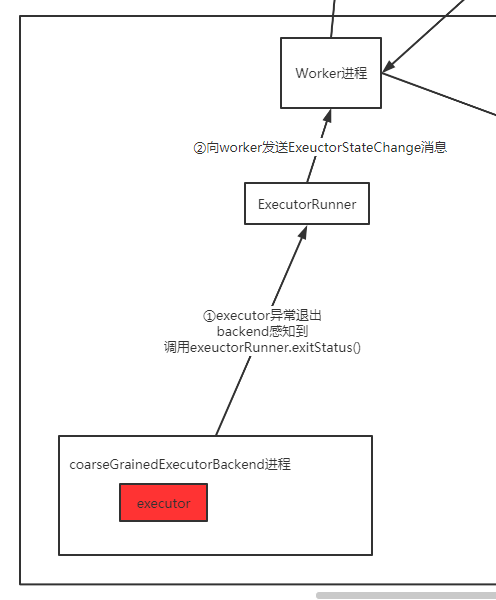
上图总结下来就是:
executor由backend进程包着,如果抛异常,他会感知到,并调用executorRunner.exitStatus(), 通知worker
看下通知worker之后发生了什么:
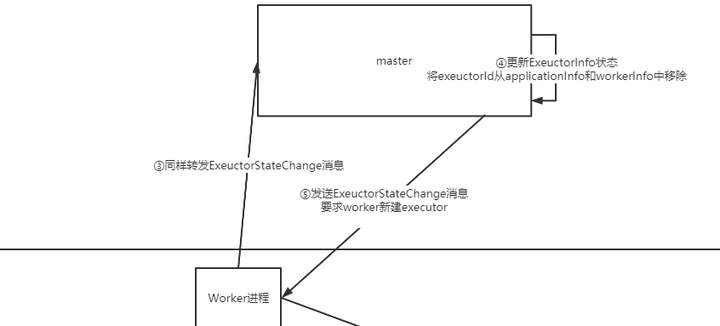
- worker会通知master,master会将exectorInfo清除,然后调度worker让他重新创建
- 这里可以看到worker创建executor的指令仍然是让master来调度和管理的,不是自己想创建就创建。
接下来就是重建executor,然后重新开始执行这个地方的任务了(因此数据也会重新拉,之前发送端缓存的数据就能够派上用场了)
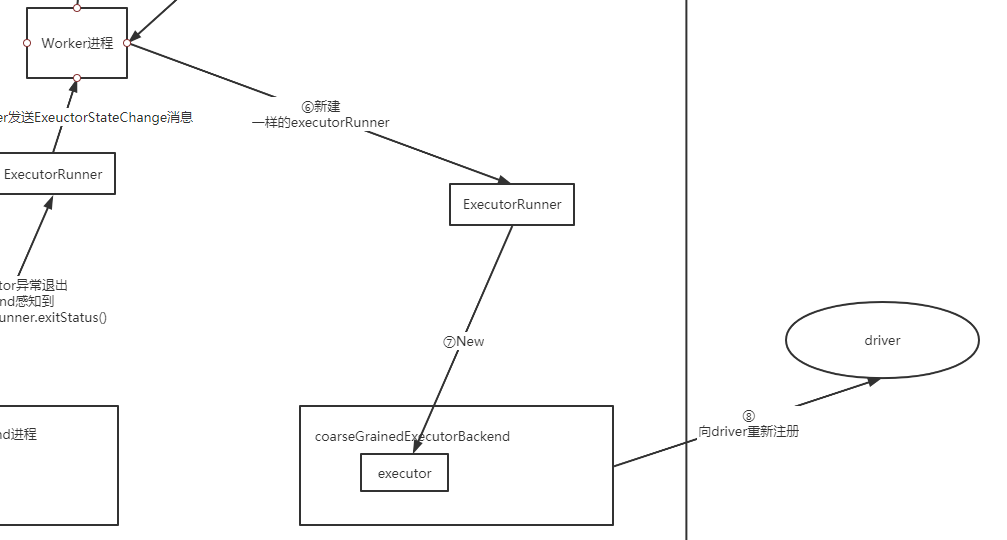
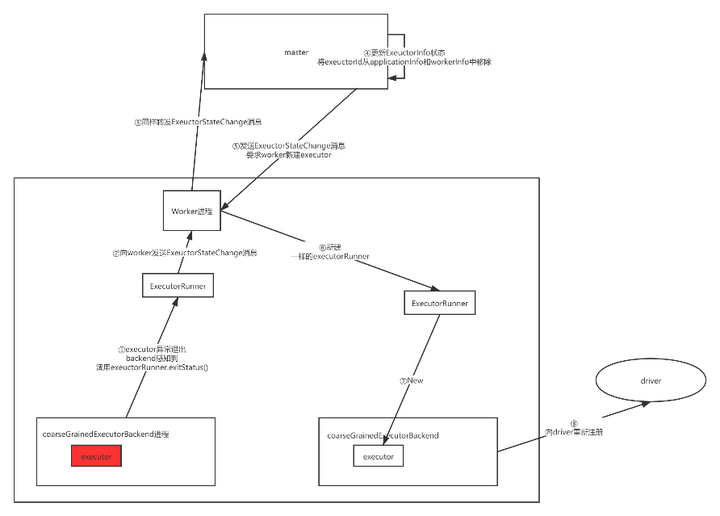
完整流程图如下:
worker异常退出
假设此时是worker挂掉了, 那么正在执行任务的exeuctor和master会怎么做呢?如下:
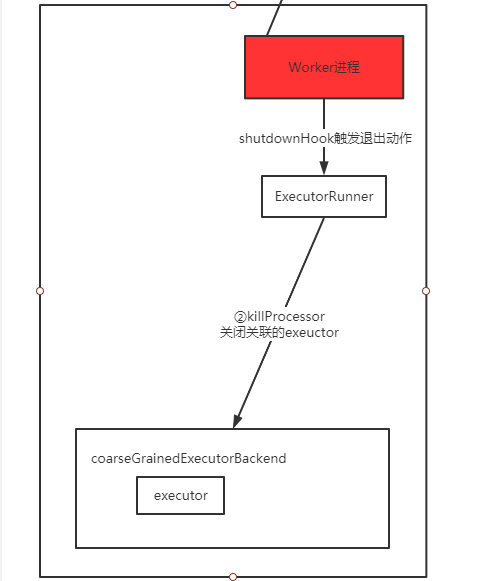
可以看到worker有一个shutdownHook,会帮忙关闭正在执行的executor。
但是此时worker挂了,因此没法往master发送消息了,怎么办?
上一节有讲到master和worker之间存在心跳,因此就会有如下处理:
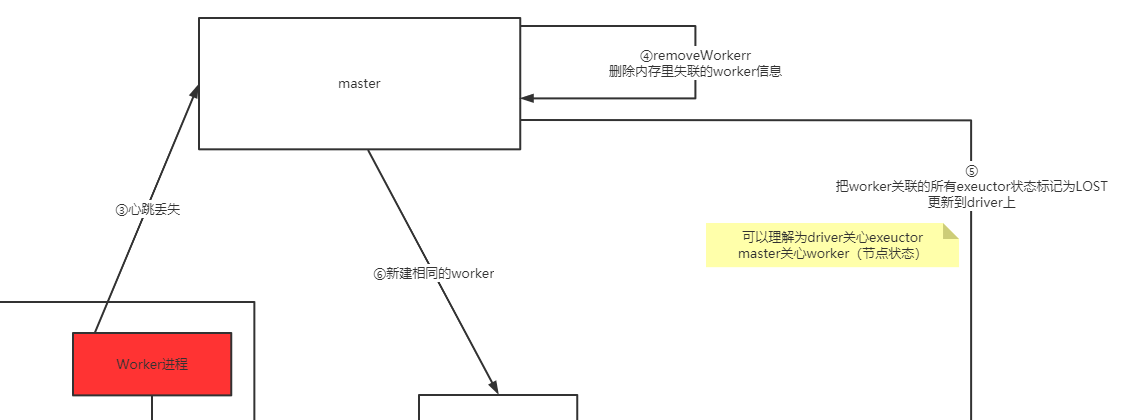
可以看到当master发现worker的心跳丢失时,会进行:
- 删除执行列表里的worker信息
- 重新下发创建worker的操作给对应spark节点
- 通知driver这个worker里面的exector都已经lost了
看下此时worker重建和driver分别做了什么:
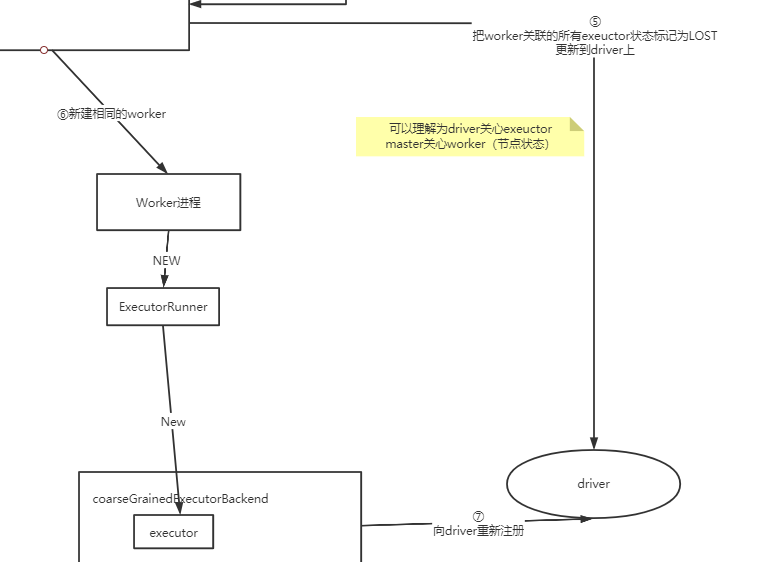
这里还可以看到1个很重要的概念:
- master关心worker状态
- driver会关心executor进展
- exeuctor重建后需要注册到driver上
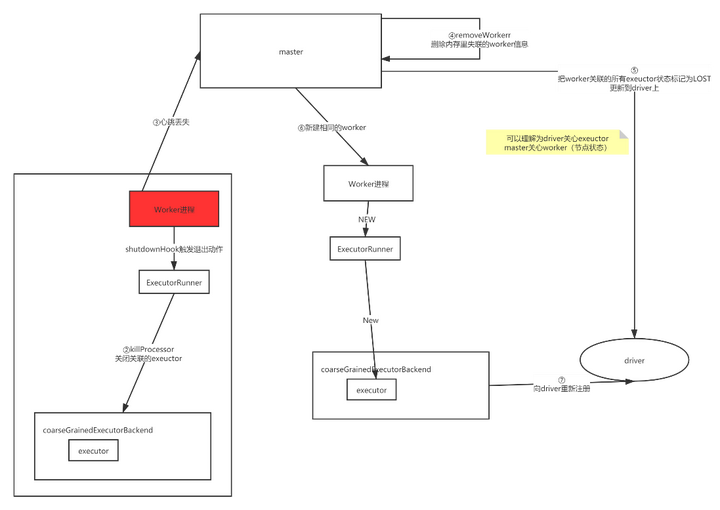
完整流程图如下:
master异常
由于master不参与任务的计算,只是对worker做管理,因此对于master的异常,分两种情况:
1、任务正常运行时master异常退出
则流程如下:
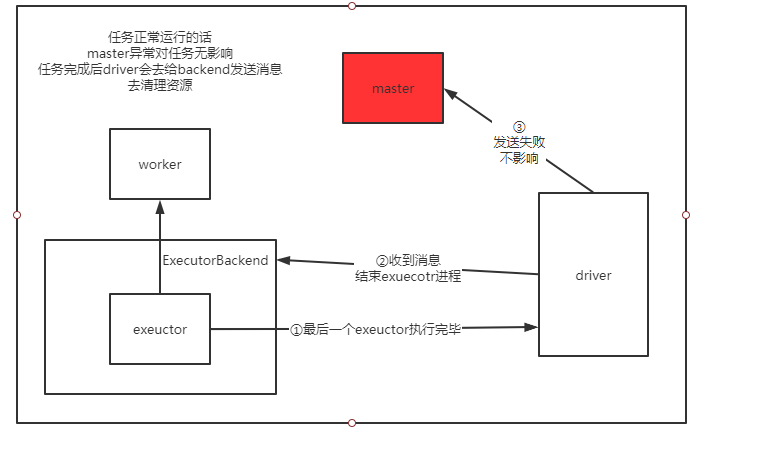
从这里可以看到当任务正常运行时,只会在结束时,由driver去触发master的清理资源操作,但是master进程已经挂掉了,所以也没关系。
2、当任务执行过程中,master挂掉后,worker和executor也异常了
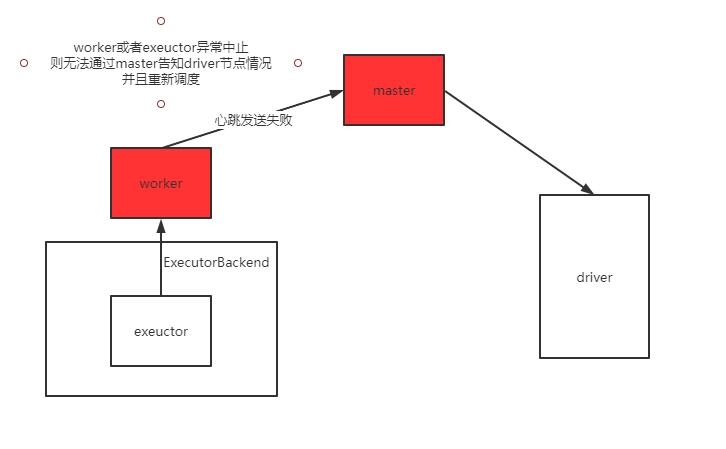
可以看到这时候时没办法重启exeuctor的
此时driver那边就会看起来任务一直没进展了。
为了避免这种情况,master可以做成无状态化,然后做主备容灾。当然master节点做的时候比较少,一般不容易崩溃,除非认为kill或者部署节点故障。
手绘流程图讲解spark是如何实现集群的高可用的更多相关文章
- Spark Streaming揭秘 Day31 集群模式下SparkStreaming日志分析(续)
Spark Streaming揭秘 Day31 集群模式下SparkStreaming日志分析(续) 今天延续昨天的内容,主要对为什么一个处理会分解成多个Job执行进行解析. 让我们跟踪下Job调用过 ...
- Spark Streaming揭秘 Day30 集群模式下SparkStreaming日志分析
Spark Streaming揭秘 Day30 集群模式下SparkStreaming日志分析 今天通过集群运行模式观察.研究和透彻的刨析SparkStreaming的日志和web监控台. Day28 ...
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- Spark学习之在集群上运行Spark(6)
Spark学习之在集群上运行Spark(6) 1. Spark的一个优点在于可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力. 2. Spark既能适用于专用集群,也可以适用于共享的云计算 ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- Idea里面远程提交spark任务到yarn集群
Idea里面远程提交spark任务到yarn集群 1.本地idea远程提交到yarn集群 2.运行过程中可能会遇到的问题 2.1首先需要把yarn-site.xml,core-site.xml,hdf ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html 目录 引言 目录 一环境选择 1集群机器安装图 2配置说明 3下载地址 二集群的相关 ...
- hadoop+tachyon+spark的zybo cluster集群综合配置
1.zybo cluster 架构简述: 1.1 zybo cluster 包含5块zybo 开发板组成一个集群,zybo的boot文件为digilent zybo reference design提 ...
随机推荐
- POSIX 真的不适合对象存储吗?
最近,留意到 MinIO 官方博客的一篇题为"在对象存储上实现 POSIX 访问接口是坏主意"的文章,作者以 S3FS-FUSE 为例分享了通过 POSIX 方式访问 MinIO ...
- 实时计算Flink+实时数仓Hologres
阿里云培训:https://developer.aliyun.com/learning/course/807/detail/13885?accounttraceid=d2070f0a9edb471c9 ...
- 巅峰对决:英伟达 V100、A100/800、H100/800 GPU 对比
近期,不论是国外的 ChatGPT,还是国内诸多的大模型,让 AIGC 的市场一片爆火.而在 AIGC 的种种智能表现背后,均来自于堪称天文数字的算力支持.以 ChatGPT 为例,据微软高管透露,为 ...
- elrond32
前置知识 int __cdecl main(int argc, char **argv) * argc: 整数, 为传给main()的命令行参数个数.* argv: 字符串数组.argv[0] 为程序 ...
- Kafka 集群如何实现数据同步?
哈喽大家好,我是咸鱼 最近这段时间比较忙,将近一周没更新文章,再不更新我那为数不多的粉丝量就要库库往下掉了 T﹏T 刚好最近在学 Kafka,于是决定写篇跟 Kafka 相关的文章(文中有不对的地方欢 ...
- JAVA中的函数接口,你都用过吗
公众号「架构成长指南」,专注于生产实践.云原生.分布式系统.大数据技术分享. 在这篇文章中,我们将通过示例来学习 Java 函数式接口. 函数式接口的特点 只包含一个抽象方法的接口称为函数式接口. 它 ...
- java中ArrayList和LinkedList的区别
Java中ArrayList和LinkedList都是List集合的实现类,它们都可以用来存储一组有序的元素,但是它们的内部实现方式不同,在使用时也有不同的适用场景. ArrayList是一个基于动态 ...
- 一篇文章带你掌握Web自动化测试工具——Selenium
一篇文章带你掌握Web自动化测试工具--Selenium 在这篇文章中我们将会介绍Web自动化测试工具Selenium 如果我们需要学习相关内容,我们需要掌握Python,PyTest以及部分前端知识 ...
- 数据集成平台关于【源平台调度&任务生命周期】
任务调度者 调度事件 生产任务 调度任务池-异步 AsynDispatcher --source 实例化适配器执行 消费任务 实例化集成应用 DataHub Instance handleSource ...
- 【Javaweb】六-servlet层
AdminServlet.jap @WebServlet("/AdminServlet") public class AdminServlet extends HttpServle ...