Chat2table,简易表格分析助手
一 写在前面
之前用智谱AI的Chatglm3-6b模型写过一个简单的论文阅读助手,可用来辅助论文阅读等。而像表格,如Excel、CSV文件等内容的分析,也是不可忽略的需要,因此本文同样使用Chatglm3-6b来搭建一个表格分析助手,用于快速分析表格的内容,提取有效的信息。
Chatglm3采用了全新的对话格式,除最基本的对话外,还支持工具调用和代码执行。简单来说,代码执行属于工具调用的子类,只是提示词不一样,而这两种功能是通过修改微调阶段的提示词来实现的。本文展示的模型作用类似代码执行,但是提示词略不一样,并且只用了最常见的对话提示词模板来完成该功能。
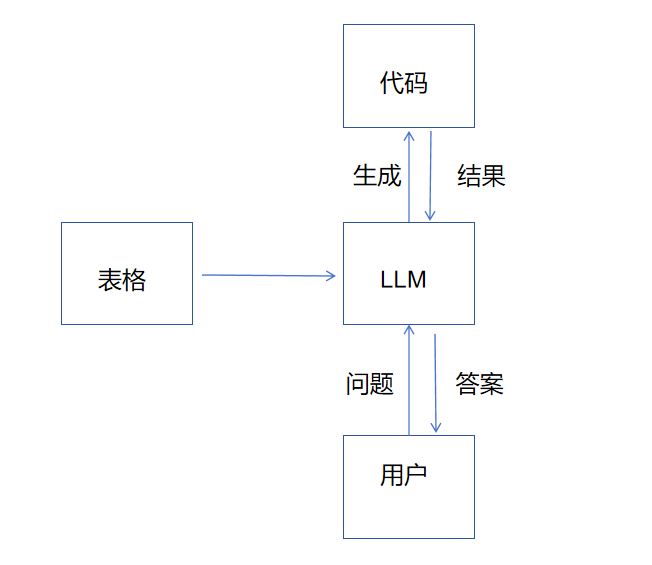
二 表格理解
读取表格非常简单,使用pandas库中的read_csv或者read_excel即可。
1 直接读取完整的表格内容
利用to_json方法将df转化为一个json字符串
def read_from_csv(filename):
df = pd.read_csv(filename)
return df.to_json(force_ascii=False)
s = read_from_csv('/test_short.csv')
print(s)
'{"id":{"0":22501,"1":22502,"2":22503,"3":22504,"4":22505,"5":22506,"6":22507,"7":22508},"age":{"0":35,"1":26,"2":44,"3":36,"4":41,"5":24,"6":25,"7":33},"nr_employed":{"0":5205,"1":4925,"2":4947,"3":5203,"4":4992,"5":4993,"6":5155,"7":5034}}'
接着把上述表格内容的字符串放进提示词中
prompt = f"已知信息:{s}\n\n请回答问题:age大于35的数量有多少?\n\n"
用了上述的提示词生成的python代码如下:
data = {
"id": {"0": 22501, "1": 22502, "2": 22503, "3": 22504, "4": 22505, "5": 22506, "6": 22507, "7": 22508},
"age": {"0": 35, "1": 26, "2": 44, "3": 36, "4": 41, "5": 24, "6": 25, "7": 33},
"nr_employed": {"0": 5205, "1": 4925, "2": 4947, "3": 5203, "4": 4992, "5": 4993, "6": 5155, "7": 5034}
}
# Calculate the number of individuals with age greater than 35
age_greater_than_35 = sum(1 for age in data["age"].values() if age > 35)
age_greater_than_35
可以看出,生成的python代码含有原表格的所有内容
2 只读取表格路径和基础信息:
import pandas as pd
csv_filename = '/test_short.csv'
query= 'age最大值是多少?'
prompt = f"已知csv文件:{csv_filename}\n\n文件Schema:{pd.read_csv(csv_filename).columns}\n\n问题:{query}\n\n请生成Python代码解决这个问题,将结果赋值给变量result\n\ndPython代码:\n\n"
生成的代码:
import pandas as pd
# 读取csv文件
data = pd.read_csv('/test_short.csv')
# 找到age列的最大值
result = data['age'].max()
print(result)
可以看出,生成的python代码只有当真正执行的时候才会从文件路径中读取表格内容
这两种方法的优缺点总结如下:
1.读取完整的表格内容:简单,但是受模型长度限制不能读取太大的表格
2.只读取表格路径和基础信息:需要一个目录用于保存文件,需要给出列的信息,模型根据这些信息生成代码,可以支持非常大的表格
三 运行代码字符串
在python脚本中动态执行python代码,可以用eval或者exec函数。一般来说,eval函数只能计算一个表达式的值,而exec可以执行复杂的代码,一般是多行的python字符串。
exec函数定义如下:
exec(object[, globals[, locals]])
参数说明:
object:必选参数,表示需要被指定的Python代码
globals:可选参数,全局变量,同eval函数
locals:可选参数,局部变量,一般指的是代码中用到的变量,同eval函数
返回值:
exec函数的返回值永远为None.
除了exec和eval,还可以利用ipython进行代码执行,即用jupyter-notebook的内核来执行代码,这里不赘述。
四 核心模块
如前所述,利用文件路径和信息构建合适的提示词:
import pandas as pd
csv_filename = '/test_short.csv'
query= 'age最大值是多少?'
prompt = f"已知csv文件:{csv_filename}\n\n文件Schema:{pd.read_csv(csv_filename).columns}\n\n问题:{query}\n\n请生成Python代码解决这个问题,将结果赋值给变量result\n\ndPython代码:\n\n"
response, history = model.chat(tokenizer, prompt, history=[])
print(response)
模型的回答如下:
首先,我们需要导入pandas库,然后读取csv文件。接下来,我们可以使用pandas的`max()`函数来找到age列的最大值,并将结果赋值给变量result。以下是完整的代码:
import pandas as pd
# 读取csv文件
data = pd.read_csv('/test_short.csv')
# 找到age列的最大值
result = data['age'].max()
print(result)
这段代码将输出age列的最大值。
接下来用正则提取出模型回答中的python代码部分:
import re
pat = re.compile(r'```python\n([\s\S]+)\n```')
code_string = pat.findall(response)[0]
print(code_string)
提取出来的python代码字符串如下:
"import pandas as pd\n\n# 读取csv文件\ndata = pd.read_csv('/test_short.csv')\n\n# 找到age列的最大值\nresult = data['age'].max()\n\nprint(result)"
利用exec执行代码,并且把结果赋给大模型。注意这时候需要设置参数role='observation':
loc = {}
exec(code_string, None, loc)
response, history = model.chat(tokenizer, f"result:{loc['result']}", history=history, role='observation')
print(response)
根据提供的CSV文件,age列的最大值是44。
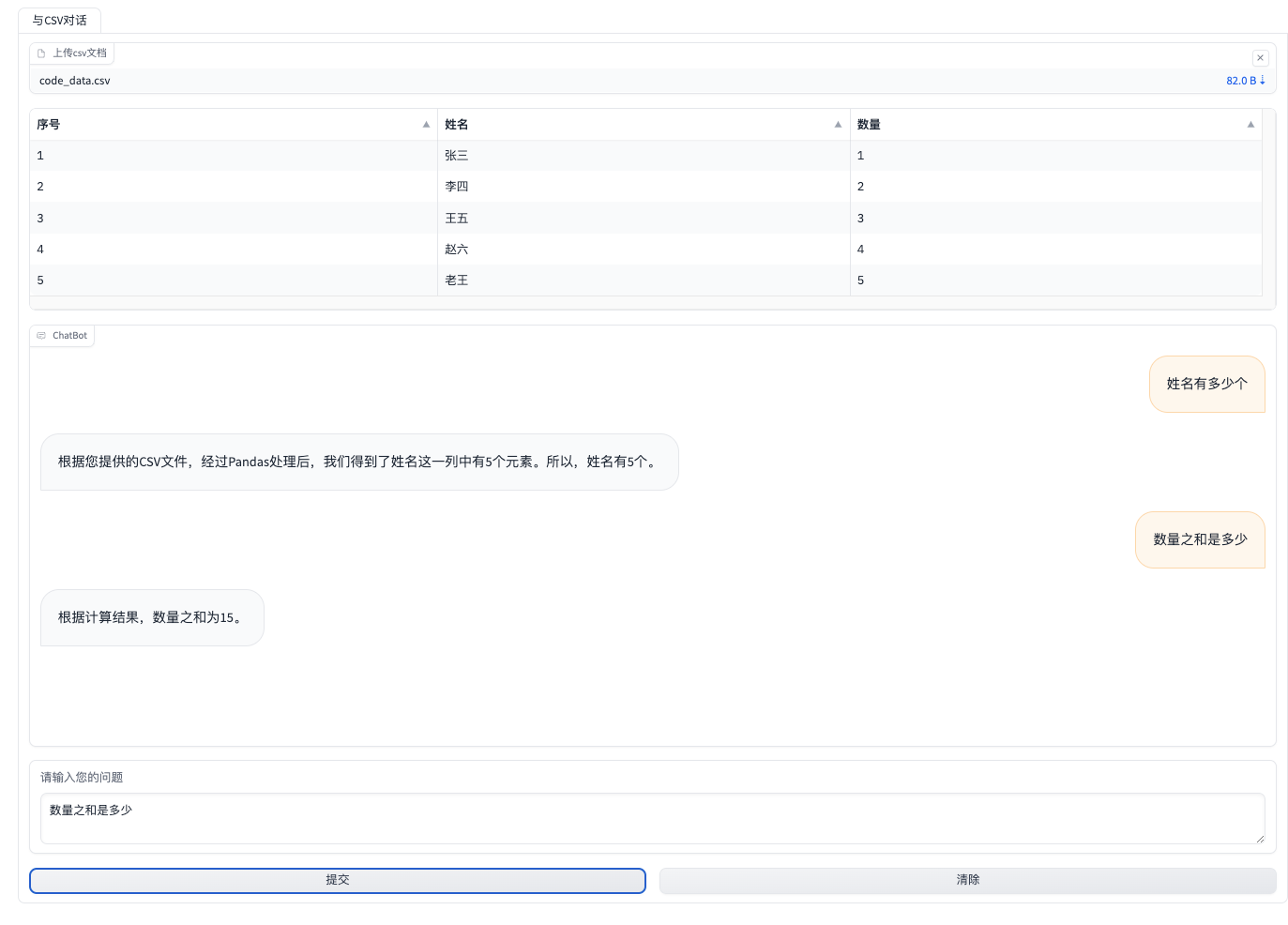
五 效果展示
Gradio库有dataframe组件,可以用来显示上传表格的内容,实现预览功能。此外,上传的文档会存放在一个临时的路径下,当会话断开后则删除,不会保存到本地中,不占用本地存储。
表格分析助手搭建效果如图:
完整代码如下:
from transformers import AutoTokenizer, AutoModel
import gradio as gr
from pathlib import Path
import re
import pandas as pd
# 加载模型
model = AutoModel.from_pretrained("/chatglm3-6b", trust_remote_code=True).to("mps").eval()
tokenizer = AutoTokenizer.from_pretrained("/chatglm3-6b", trust_remote_code=True)
def read_tbl_2_pd(filename):
if filename.endswith('.csv'):
df = pd.read_csv(filename)
elif filename.endswith('.xlsx') or filename.endswith('.xls'):
pd.read_excel(filename, sheet_name=None)
return df
def fn_analysis_table(query, robot, filename):
if robot is None:
robot = []
robot.append([query, " "])
if filename.endswith('.csv'):
schema = pd.read_csv(filename).columns
elif filename.endswith('.xlsx') or filename.endswith('.xls'):
schema = pd.read_excel(filename, sheet_name=None)['Sheet1'].columns
chat_history = []
prompt = f"已知文件:{filename}\n\n文件Schema:{schema}\n\n问题:{query}\n\n请利用Pandas生成Python代码解决这个问题,最后的结果务必赋值给变量result\n\ndPython代码:\n\n"
print(prompt)
response, history = model.chat(tokenizer, prompt, history=[])
print(response)
pat = re.compile(r'```python\n([\s\S]+)\n```')
code_string = pat.findall(response)[0]
print(code_string)
loc = {}
exec(code_string, None, loc)
result = loc['result']
response, history = model.chat(tokenizer, f'result:{result}', history=history, role='observation')
robot[-1] = [query, response]
yield robot
with gr.Blocks() as app:
with gr.Tab("与CSV对话"):
with gr.Row():
with gr.Column(scale=1):
upload = gr.File(label="上传csv文档")
df = gr.Dataframe()
chatbot = gr.Chatbot(
label="ChatBot",
height=500,
bubble_full_width=False
)
instruction = gr.Textbox(lines=2, label="请输入您的问题", placeholder="问题...", max_lines=2)
with gr.Row():
submit = gr.Button("提交", size="sm",interactive=True)
clean = gr.Button("清除", size="sm")
upload.upload(fn=read_tbl_2_pd, inputs=[upload], outputs=[df], queue=False)
submit.click(
fn=fn_analysis_table,
inputs=[instruction, chatbot, upload],
outputs=[chatbot],
queue=True
)
clean.click(fn=lambda: None, inputs=None, outputs=chatbot, queue=False)
app.queue(max_size=3)
app.launch(share=False)
Chat2table,简易表格分析助手的更多相关文章
- code_analyzer(代码分析助手)
软件名: code_analyzer 使用c语言 pcre正则库分析源码文件,包括文件中的头文件.宏定义.函数. 用途: 无聊时,可以用来打发下时间. 演示: 对于本源程序的分析结果如下: ##### ...
- 爬虫系列1:python简易爬虫分析
决定写一个小的爬虫系列,本文是第一篇,讲爬虫的基本原理和简易示例. 1.单个网页的简易爬虫 以下爬虫的主要功能是爬取百度贴吧中某一页面的所有图片.代码由主要有两个函数:其中getHtml()通过页面u ...
- APP 性能分析工作台——你的最佳桌面端性能分析助手
目前 MARS-App 性能分析工作台版本为开发者提供Fastbot桌面版的服务. 旨在帮助开发者们更快.更便捷地开启智能测试之旅,成倍提升稳定性测试的效率. 作者:字节跳动终端技术--王凯 背景 F ...
- 网络摄像机IPCamera RTSP直播播放网络/权限/音视频数据/花屏问题检测与分析助手EasyRTSPClient
前言 最近在项目中遇到一个奇怪的问题,同样的SDK调用,访问海康摄像机的RTSP流,发保活OPTIONS命令保活,一个正常,而另一个一发就会被IPC断开,先看现场截图: 图1:发OPTIONS,摄像机 ...
- 通过excel表格分析学生成绩
题目要求: 分析文件’课程成绩.xlsx’,至少要完成内容:分析1)每年不同班级平均成绩情况.2)不同年份总体平均成绩情况.3)不同性别学生成绩情况,并分别用合适的图表展示出三个内容的分析结果. 废话 ...
- NoSQL数据库的四大分类表格分析
- 49.Qt-网络编程之QTCPSocket和QTCPServer(实现简易网络调试助手)
在上章 48.QT-网络通信讲解1,我们学习了网络通信基础后,本章便来实战一篇.源码正在上传中,等下贴地址. PS:支持客户端和服务器,提供源码,并且服务器支持多客户端连入,并且可以指定与个别客户端发 ...
- 如何查看与分析IIS服务器日志?
发布时间:2012-12-01 16:17:28.0 作者:青岛做网站 网站日志分析是站长每天的必备工作之一,服务器的一些状况和访问IP的来源都会记录在IIS日志中,所以IIS日志对每个服务器管理 ...
- 各种RTMP直播流播放权限_音视频_数据花屏_问题检测与分析工具EasyRTMPClient
之前的一篇博客<网络摄像机IPCamera RTSP直播播放网络/权限/音视频数据/花屏问题检测与分析助手EasyRTSPClient>,我们介绍了RTSP流的检测和分析工具EasyRTS ...
- TS流分析
http://blog.csdn.net/zxh821112/article/details/17587215 一 从TS流开始 数字电视机顶盒接收到的是一段段的码流,我们称之为TS(Transpor ...
随机推荐
- 序列图 时序图 PlantUML vscode drawio 制作
序列图 时序图 PlantUML vscode drawio 制作 需求 最近发现 序列图 很多文档都用到,而且很好用.经过研究用vscode,idea都可以编写.这里用vscode编写比较简单. d ...
- 数组动态表单验证,添加数组,逆序添加,表单验证会错位,发现是key的默认index问题,还有验证trigger问题,添加数据会爆红
数组动态表单验证,添加数组,逆序添加,表单验证会错位,发现是key的默认index问题,还有验证trigger问题,添加数据会爆红 解决方案: trigger: 'blur,change' 换 tri ...
- 日常办公——Excel中重复打印标题的设置
打印预览时,所在数据行或列不能显示在同一页,在打印区域之外还有内容,为了方便阅读,可使用顶端标题行重复或左端标题行重复,具体方法如下: 按顺序操作,完成后点击确定即完成操作.
- Kotlin学习快速入门(9)—— 密封类的使用
原文地址: Kotlin学习快速入门(9)-- 密封类的使用 - Stars-One的杂货小窝 代码逻辑中,很多时候我们会需要分支语句,来根据数据的情况走不同的处理逻辑,而密封类就是在这种情况下,方便 ...
- 回顾redis底层数据结构
参考,欢迎点击原文:https://blog.csdn.net/qq_38286618/article/details/102530020 https://www.cnblogs.com/jaycek ...
- MySQL 如何以当前日期时间作为字段初始默认值?
1.以当前时间作为默认值 使用 DEFAULT CURRENT_TIMESTAMP 声明字段,插入记录时不用指定 dt,自动置入当前时间 CREATE TABLE t1 ( dt DATETIME D ...
- 记录--为啥面试官总喜欢问computed是咋实现的?
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 从computed的特性出发 computed最耀眼的几个特性是啥? 1. 依赖追踪 import { reactive, compute ...
- CDC实战:MySQL实时同步数据到Elasticsearch之数组集合(array)如何处理【CDC实战系列十二】
需求背景: mysql存储的一个字段,需要同步到elasticsearch,并存储为数组,以便于查询. 如下例子,就是查询预期. PUT /t_test_1/_doc/1 { "name&q ...
- 靶场搭建----phpstudy2018安装及注意问题
安装 官网下载: https://www.xp.cn/download.html 新人推荐2018 版本phpstudy 介绍 系统服务------开机自启 非服务模式------开机不自启 搭建好环 ...
- 超越极限!80Gbps高速传输,让您的数据瞬间飞速传递
大文件传输是很多企业面临的挑战之一.基于传统的文件传输方法,由于许多原因,例如网络拥塞.数据包丢失.传播延迟等,导致文件的传输速度较慢.不稳定或不安全.尤其是对于像科研机构.金融公司和媒体制作公司等需 ...