论文解读(AAD)《Knowledge distillation for BERT unsupervised domain adaptation》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文信息
论文标题:Knowledge distillation for BERT unsupervised domain adaptation
论文作者:Minho Ryu、Geonseok Lee、Kichun Lee
论文来源:2022 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
出发点:域偏移导致的性能下降;
问题定义:UDA
比较有意思,这篇工作被抄袭了,但是抄袭的家伙还成功发论文了.............
2 相关工作
知识蒸馏 [7,8](KD)最初是一种模型压缩技术,旨在训练一个紧凑的模型(学生),以便将一个训练良好的更大的模型(教师)的知识转移到学生模型[28,29]。KD 可以通过最小化以下目标函数来表示:
$\mathcal{L}_{K D}=t^{2} \sum_{k}-\operatorname{softmax}\left(p_{k}^{T} / t\right) \times \log \left(\operatorname{softmax}\left(p_{k}^{S} / t\right)\right)$
其中,$p^{S}$ 和 $p^{T}$ 分别为学生模型和教师模型的预测,温度值 $t$ 控制着知识转移的程度。
推导过程:
$K L(p \| q)=\sum_{i=1}^{n} p\left(x_{i}\right) \log \left(\frac{p\left(x_{i}\right)}{q(x i)}\right)$
$\begin{array}{l} K L(p \| q)&=\sum_{i=1}^{n} p\left(x_{i}\right) \log \left(p\left(x_{i}\right)\right)-\sum_{i=1}^{n} p\left(x_{i}\right) \log \left(q\left(x_{i}\right)\right)\\&=H(p(x)) -\sum_{i=1}^{n} p\left(x_{i}\right) \log \left(q\left(x_{i}\right)\right)\end{array}$
注意:$P$ 代表着真实分布, $Q$ 代表着模型分布;
注意:学生模型训练时,教师模型的参数是固定的,因此 $H(p(x))$ 为常数,可以去掉;
注意:标准的监督训练,由于使用的是硬标签做监督训练,所以在重复训练的时候容易造成过拟合。由于较大的 $t$ 值产生较软的概率分布,知识蒸馏在结合领域自适应方法可以缓解这一问题。
3 方法
3.1 模型框架
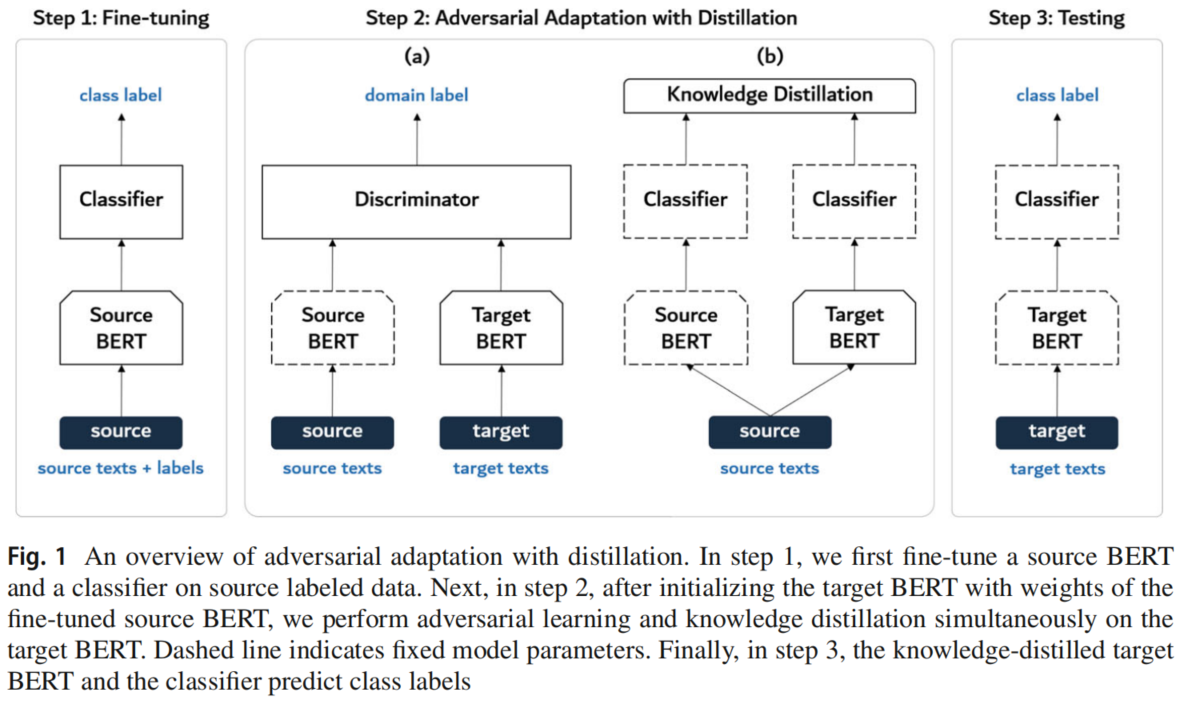
3.2 Adversarial adaptation with distillation
Step 1: fine-tune the source encoder and the classifier
使用源域数据进行标准的监督训练,训练 $E_s$ 和 $C$:
$\underset{E_{S}, C}{\text{min}} \; \mathcal{L}_{S}\left(\mathbf{X}_{S}, \mathbf{y}_{S}\right)=\mathbb{E}_{\left(\boldsymbol{x}_{s}, y_{s}\right) \sim\left(\mathbb{X}_{S}, \mathbb{Y}_{S}\right)}-\sum_{k=1}^{K} \mathbb{1}_{\left[k=y_{s}\right]} \log C\left(E_{S}\left(\boldsymbol{x}_{S}\right)\right)$
Step 2: adapt the target encoder via adversarial adaptation with distillation
固定 $E_s$ 的参数,并使用 $E_s$ 初始化 $E_t$ 的参数,接着进行对抗性训练:
$\begin{array}{l}\underset{D}{\text{min}} \; \mathcal{L}_{\text {dis }}\left(\mathbf{X}_{S}, \mathbf{X}_{T}\right)=\mathbb{E}_{\boldsymbol{x}_{s} \sim \mathbb{X}_{S}}-\log D\left(E_{S}\left(\boldsymbol{x}_{s}\right)\right)+\mathbb{E}_{\boldsymbol{x}_{t} \sim \mathbb{X}_{T}}-\log \left(1-D\left(E_{t}\left(\boldsymbol{x}_{t}\right)\right)\right)\\\underset{E_{t}}{\text{min}} \; \mathcal{L}_{g e n} \left(\mathbf{X}_{T}\right)=\mathbb{E}_{\boldsymbol{x}_{t} \sim \mathbb{X}_{T}}-\log D\left(E_{t}\left(\boldsymbol{x}_{t}\right)\right)\end{array}$
然而,由于无法使用类标签,该公式很容易导致灾难性的遗忘,从而导致分类性能下降。对于一个使用大的 $t$ 的知识蒸馏模型,它不仅可以使得对抗性训练稳定,还可以良好的保存类信息。因此,引入了知识蒸馏损失:
$\mathcal{L}_{K D}\left(\mathbf{X}_{S}\right)=t^{2} \times \mathbb{E}_{\boldsymbol{x}_{s} \sim \mathbb{X}_{S}} \sum_{k=1}^{K}-\operatorname{softmax}\left(p_{k}^{S} / t\right) \times \log \left(\operatorname{softmax}\left(p_{k}^{T} / t\right)\right)$
其中,$p^{S}=C\left(E_{S}\left(\boldsymbol{x}_{s}\right)\right)$、$\boldsymbol{p}^{T}=C\left(E_{t}\left(\boldsymbol{x}_{s}\right)\right)$;
因此,训练目标编码器 $E_{t}$ 的最终目标函数变为:
$\underset{E_{t}}{\text{min}} \;\mathcal{L}_{T}\left(\mathbf{X}_{S}, \mathbf{X}_{T}\right)=\mathcal{L}_{\text {gen }}\left(\mathbf{X}_{T}\right)+\mathcal{L}_{K D}\left(\mathbf{X}_{S}\right)$
Step 3: test the target encoder on the target data
使用训练好的目标编码器 $E_t$ 和分类器 $C$ 对用于测试的目标数据情绪极性标签预测如下:
$\hat{y}_{t}=\arg \max C\left(E_{t}\left(\boldsymbol{x}_{t}\right)\right)$
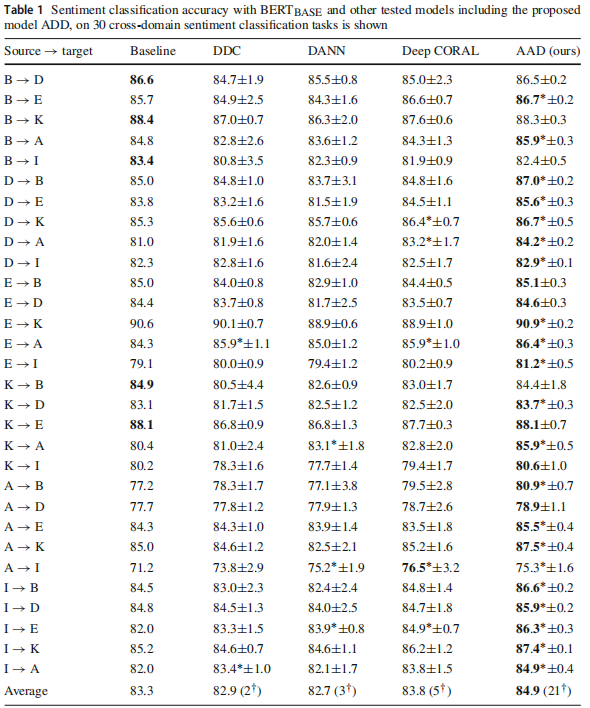
4 实验
跨域情感分析
论文解读(AAD)《Knowledge distillation for BERT unsupervised domain adaptation》的更多相关文章
- 论文解读(CDCL)《Cross-domain Contrastive Learning for Unsupervised Domain Adaptation》
论文信息 论文标题:Cross-domain Contrastive Learning for Unsupervised Domain Adaptation论文作者:Rui Wang, Zuxuan ...
- 论文解读(CDTrans)《CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation》
论文信息 论文标题:CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation论文作者:Tongkun Xu, Weihu ...
- 论文解读(ToAlign)《ToAlign: Task-oriented Alignment for Unsupervised Domain Adaptation》
论文信息 论文标题:ToAlign: Task-oriented Alignment for Unsupervised Domain Adaptation论文作者:Guoqiang Wei, Cuil ...
- 论文解读(CAN)《Contrastive Adaptation Network for Unsupervised Domain Adaptation》
论文信息 论文标题:Contrastive Adaptation Network for Unsupervised Domain Adaptation论文作者:Guoliang Kang, Lu Ji ...
- 虚假新闻检测(CADM)《Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup》
论文信息 论文标题:Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversari ...
- 迁移学习(IIMT)——《Improve Unsupervised Domain Adaptation with Mixup Training》
论文信息 论文标题:Improve Unsupervised Domain Adaptation with Mixup Training论文作者:Shen Yan, Huan Song, Nanxia ...
- 迁移学习(DCCL)《Domain Confused Contrastive Learning for Unsupervised Domain Adaptation》
论文信息 论文标题:Domain Confused Contrastive Learning for Unsupervised Domain Adaptation论文作者:Quanyu Long, T ...
- 迁移学习(TSRP)《Improving Pseudo Labels With Intra-Class Similarity for Unsupervised Domain Adaptation》
论文信息 论文标题:Improving Pseudo Labels With Intra-Class Similarity for Unsupervised Domain Adaptation论文作者 ...
- 迁移学习《Asymmetric Tri-training for Unsupervised Domain Adaptation》
论文信息 论文标题:Asymmetric Tri-training for Unsupervised Domain Adaptation论文作者:Kuniaki Saito, Y. Ushiku, T ...
- 迁移学习《Efficient and Robust Pseudo-Labeling for Unsupervised Domain Adaptation》
论文信息 论文标题:Efficient and Robust Pseudo-Labeling for Unsupervised Domain Adaptation论文作者:Hochang Rhee.N ...
随机推荐
- Prism Sample 23-RegionMemberLifetime
在导航中跳转时,视图是缓存的.如果要求某视图在离开后就销毁,需要实现 public class ViewAViewModel : BindableBase, INavigationAware, IRe ...
- 如何利用Requestly提升前端开发与测试的效率,让你事半功倍?
痛点 前端测试 在进行前端页面开发或者测试的时候,我们会遇到这一类场景: 在开发阶段,前端想通过调用真实的接口返回响应 在开发或者生产阶段需要验证前端页面的一些 异常场景 或者 临界值 时 在测试阶段 ...
- 张量(Tensor)、标量(scalar)、向量(vector)、矩阵(matrix)
张量(Tensor):Tensor = multi-dimensional array of numbers 张量是一个多维数组,它是标量,向量,矩阵的高维扩展 ,是一个数据容器,张量是矩阵向任意维度 ...
- 最短路(Floyed、Dijkstra、Bellman-Ford、SPFA)
一.Floyed-Warshall算法 枚举中间点起点终点,对整个图进行松弛操作,就能得到整个图的多源最短路径: 例:POJ2240 Arbitrage Arbitrage is the use of ...
- Stream流根据属性去重
List根据属性去重 创建一个user集合 User user1 = new User("user1", 18, "AAA"); User user2 = ne ...
- 树莓派上使用docker部署aria2,minidlna
目前在树莓派上安装aria2跟minidlna能搜到的教程基本上都是直接apt-get install安装的.现在是docker的时代了,其实这2个东西可以直接使用docker run跑起来.有什么问 ...
- 数据分析缺失值处理(Missing Values)——删除法、填充法、插值法
缺失值指数据集中某些变量的值有缺少的情况,缺失值也被称为NA(not available)值.在pandas里使用浮点值NaN(Not a Number)表示浮点数和非浮点数中的缺失值,用NaT表示时 ...
- HTML转为PDF,图片导出失败的终极解决方案
如题项目有需求将一个页面导出为pdf,然而页面中的图片却始终无法导出成功 文章目录 一.导出的方法 二.初步测试的结果 三.使用f12查找原油 四.方案一 五.方案二 六.方案三 七.完整代码 1.使 ...
- Git及可视化工具TortoiseGit的安装及使用
前言: TortoiseGit(中文称git小乌龟),是一款开源的git可视化gui工具,让你可以用图形化的界面来使用git,如此即使不会git命令也能流畅的使用git(我就是不想学git命令才使用的 ...
- ChatGPT 是否会夺走人们的工作
ChatGPT 是否会夺走人们的工作? 最近,以 ChatGPT 为代表的人工智能项目在自然语言处理这一领域得到了一些突破性的进展,重新引发了人们对于"人工智能会抢走人类工作机会" ...