【经典爬虫案例】用Python爬取微博热搜榜!
一、爬取目标
您好,我是@马哥python说,一名10年程序猿。
本次爬取的目标是: 微博热搜榜
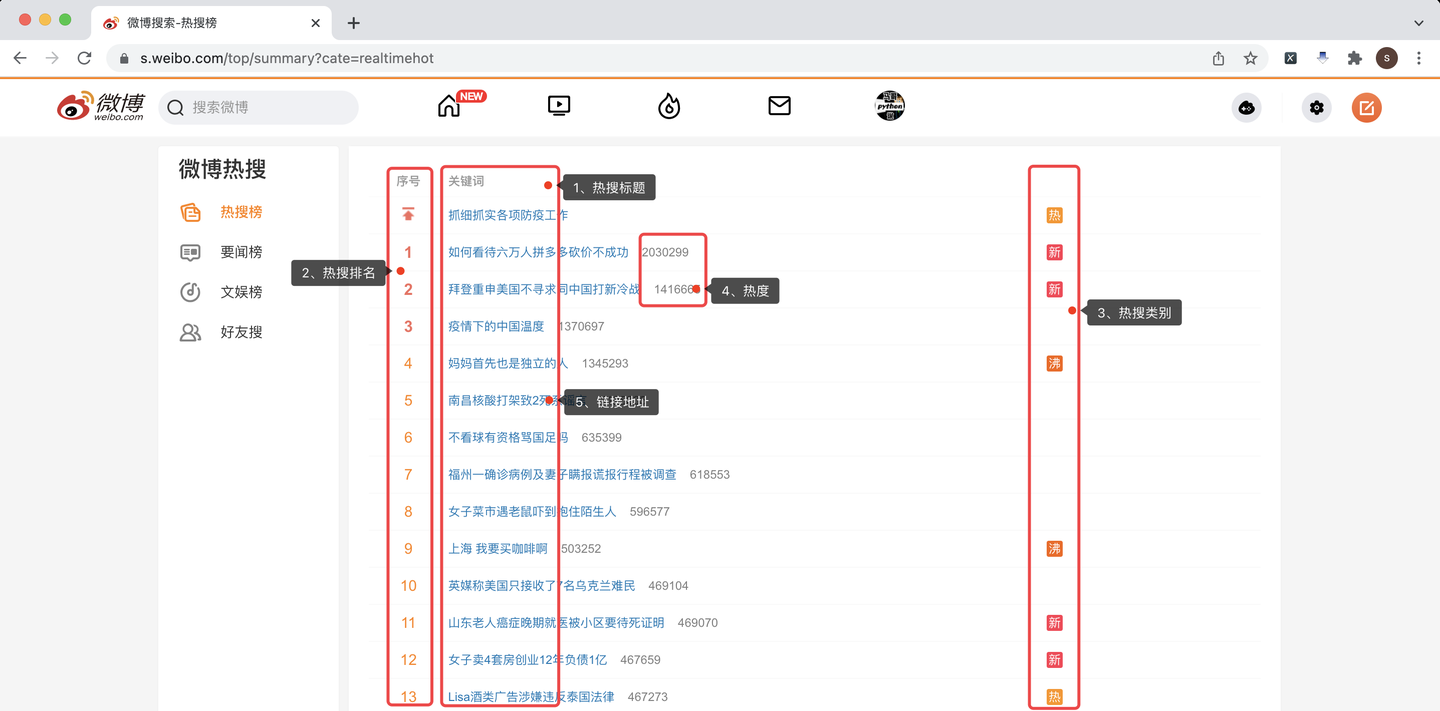
分别爬取每条热搜的:
热搜标题、热搜排名、热搜类别、热度、链接地址。
下面,对页面进行分析。
经过分析,此页面没有XHR链接通过,也就是说,没有采用AJAX异步技术。
所以,只能针对原页面进行爬取。
二、编写爬虫代码
2.1 前戏
首先,导入需要用到的库:
import pandas as pd # 存入excel数据
import requests # 向页面发送请求
from bs4 import BeautifulSoup as BS # 解析页面
定义一个爬取目标地址:
# 目标地址
url = 'https://s.weibo.com/top/summary?cate=realtimehot'
定义一个请求头:
# 请求头
header = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Mobile Safari/537.36',
'Host': 's.weibo.com',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh-Hans;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
# 定期更换Cookie
'Cookie': '换成自己的Cookie值'
}
其中,Cookie需要换成自己的Cookie值。
2.2 获取cookie
怎么查看自己的Cookie?
Chrome浏览器,按F12打开开发者模式,按照以下步骤操作:
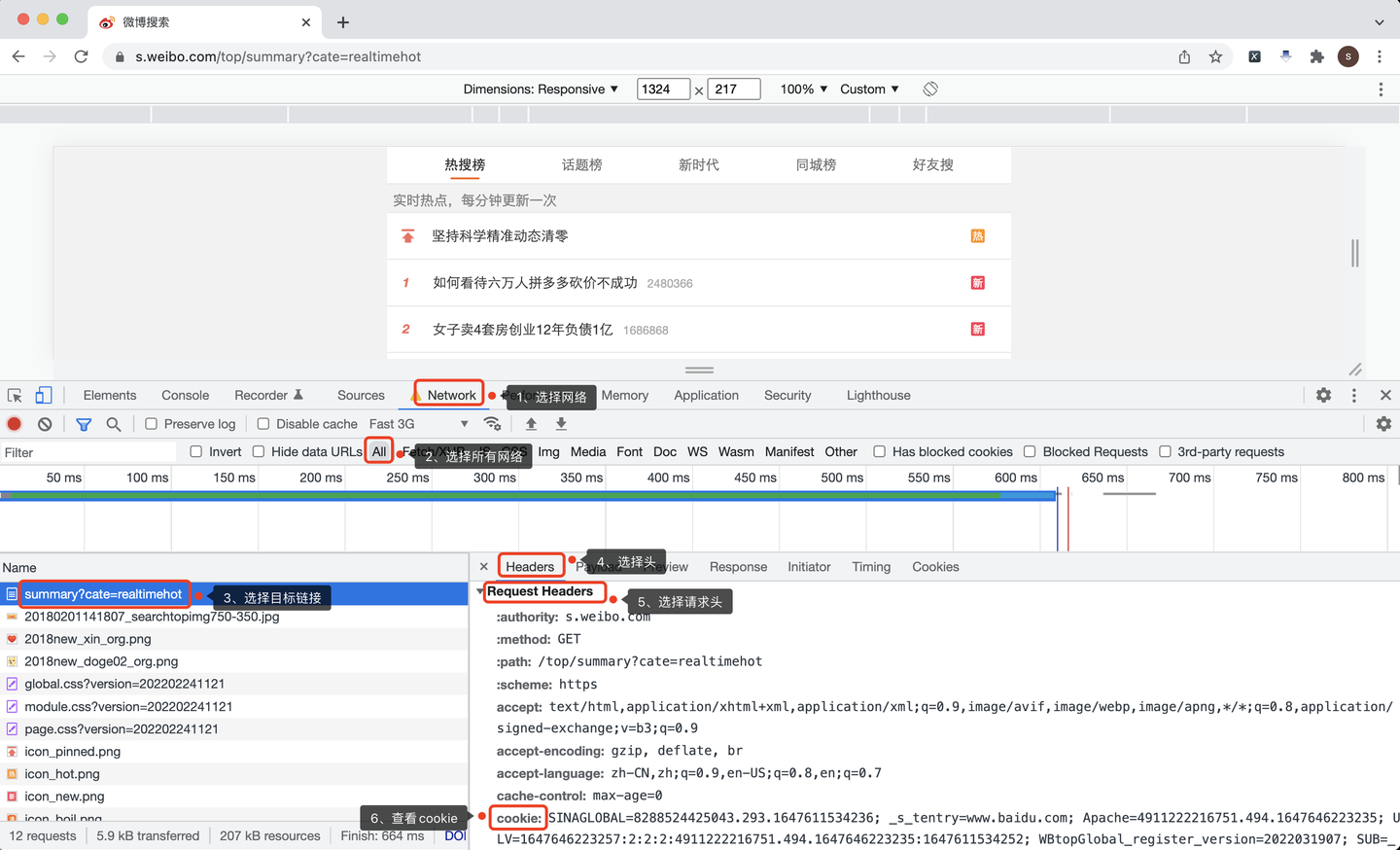
- 选择网络:Network
- 选择所有网络:All
- 选择目标链接地址
- 选择头:Headers
- 选择请求头:Request Headers
- 查看cookie值
2.3 请求页面
下面,向页面发送请求:
r = requests.get(url, headers=header) # 发送请求
2.4 解析页面
接下来,解析返回的页面:
soup = BS(r.text, 'html.parser')
```
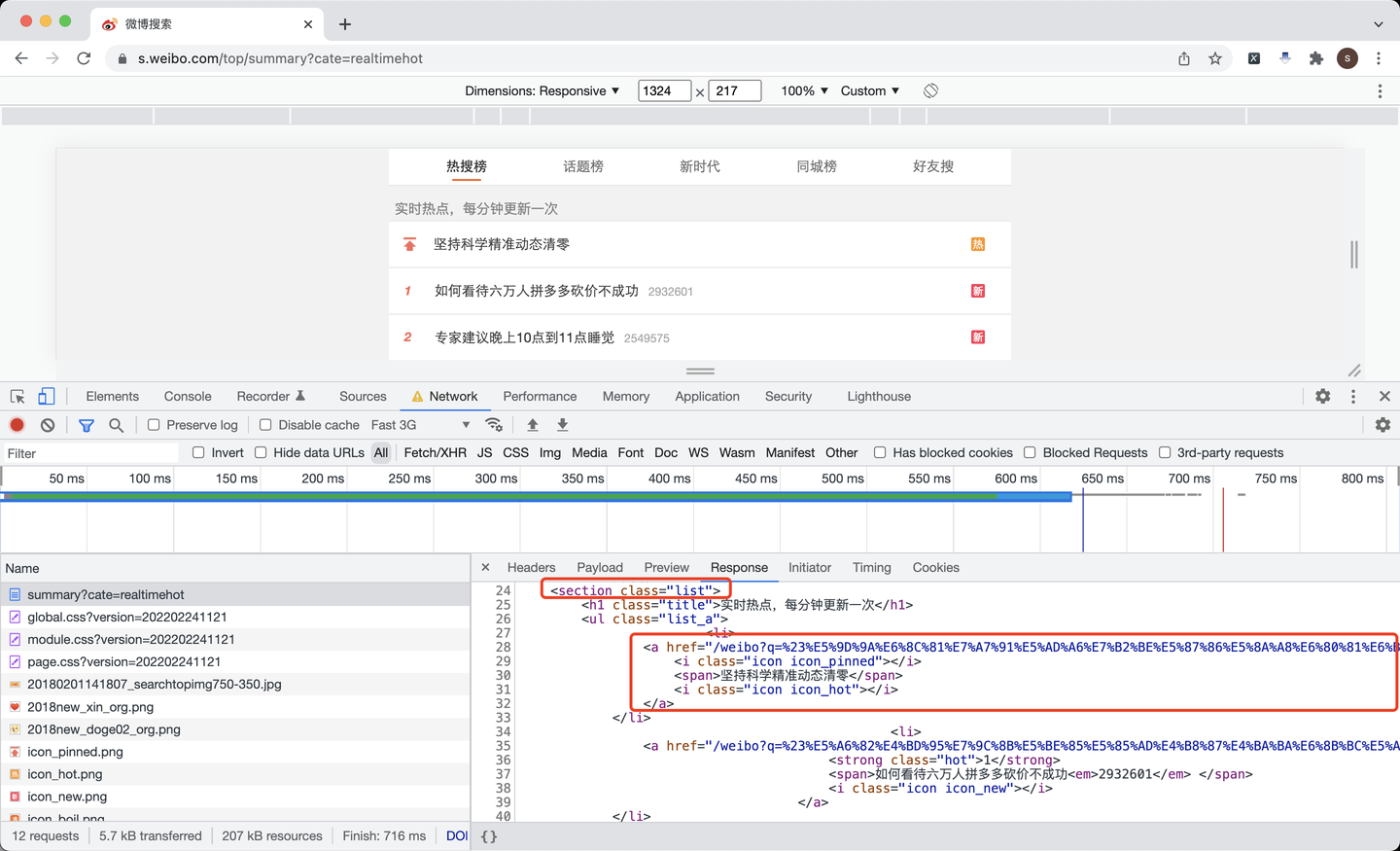
根据页面分析,每条热搜都放在了标签为section的、class值为list的数据里,里面每条热搜,又是一个a标签。
所以,根据这个逻辑,解析页面,以获取链接地址为例:
```python
items = soup.find('section', {'class': 'list'})
for li in items.find_all('li'):
# 链接地址
href = li.find('a').get('href')
href_list.append('https://s.weibo.com' + href)
页面其他元素,热搜标题、排名、热度、类别等获取代码,不再一一赘述。
2.5 转换热搜类别
其中,热搜类别这个元素需要注意,在页面上是一个个图标,背后对应的是class值,是个英文字符串,需要转换成对应的中文含义,定义以下函数进行转换:
def trans_icon(v_str):
"""转换热搜类别"""
if v_str == 'icon_new':
return '新'
elif v_str == 'icon_hot':
return '热'
elif v_str == 'icon_boil':
return '沸'
elif v_str == 'icon_recommend':
return '商'
else:
return '未知'
目前的转换函数包括了"新"、"热"、"沸"、"商"等类别。
我记得,微博热搜类别,是有个"爆"的,就是热度最高的那种,突然蹿升的最热的热点,爆炸性的。但是现在没有爆炸性新闻,所以我看不到"爆"背后的class值是什么。
后续如果有爆炸性热点,可以按照代码的逻辑,加到这个转换函数里来。
2.6 保存结果
依然采用我最顺手的to_excel方式,存入爬取的数据:
df = pd.DataFrame( # 拼装爬取到的数据为DataFrame
{
'热搜标题': text_list,
'热搜排名': order_list,
'热搜类别': type_list,
'热度': view_count_list,
'链接地址': href_list
}
)
df.to_excel('微博热搜榜.xlsx', index=False) # 保存结果数据
至此,整个爬取过程完毕。
2.7 查看结果数据
查看一下,保存到excel里的数据:

其中,第一条是置顶热搜,所以一共是 (1+50=51) 条数据。
演示视频:
https://www.bilibili.com/video/BV1Xb4y1p7Ka
三、获取完整源码
get完整代码:【最新爬虫案例】用Python爬取微博热搜榜!
我是@马哥python说,持续分享python源码干货中!
【经典爬虫案例】用Python爬取微博热搜榜!的更多相关文章
- BeautifulSoup爬取微博热搜榜
获取url 设定请求头 requests发出get请求 实例化BeautifulSoup对象 BeautifulSoup提取数据 import requests 2 from bs4 import B ...
- Python爬取微博热搜以及链接
基本操作,不再详述 直接贴源码(根据当前时间创建文件): import requests from bs4 import BeautifulSoup import time def input_to_ ...
- nodejs实现定时爬取微博热搜
The summer is coming " 我知道,那些夏天,就像青春一样回不来. - 宋冬野 青春是回不来了,倒是要准备渡过在西安的第三个夏天了. 废话 我发现,自己对 coding 这 ...
- Python网络爬虫-爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库 url=https://s.weibo.com/top/summary?Refer=top_hot&topnav=1& ...
- 【网络爬虫】【java】微博爬虫(一):小试牛刀——网易微博爬虫(自定义关键字爬取微博数据)(附软件源码)
一.写在前面 (本专栏分为"java版微博爬虫"和"python版网络爬虫"两个项目,系列里所有文章将基于这两个项目讲解,项目完整源码已经整理到我的Github ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- 2020不平凡的90天,Python分析三个月微博热搜数据带你回顾
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:刘早起早起 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- 【python网络编程】新浪爬虫:关键词搜索爬取微博数据
上学期参加了一个大数据比赛,需要抓取大量数据,于是我从新浪微博下手,本来准备使用新浪的API的,无奈新浪并没有开放关键字搜索的API,所以只能用爬虫来获取了.幸运的是,新浪提供了一个高级搜索功能,为我 ...
- 用python爬取微博数据并生成词云
很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,放在今天应该比较应景. 一年一度的虐汪节,是继续蹲在角落默 ...
- Python爬取酷狗飙升榜前十首(100)首,写入CSV文件
酷狗飙升榜,写入CSV文件 爬取酷狗音乐飙升榜的前十首歌名.歌手.时间,是一个很好的爬取网页内容的例子,对爬虫不熟悉的读者可以根据这个例子熟悉爬虫是如何爬取网页内容的. 需要用到的库:requests ...
随机推荐
- KingbaseES 使用sys_bulkload远程导入
前言 sys_bulkload 常见场景是本地导入数据,也可以在远程运行 sys_bulkload ,对数据库上的CSV 文件进行导入.远程导入数据时候需要注意,csv文件和ctl文件所在服务器.以下 ...
- UE4 c++ -- 简单的UMG
说明 学习一下如何将Widget蓝图与C++连接起来,将处理逻辑写在C++中 基础 在蓝图中,我们显示Widget是通过一个Actor或者PlayerController,甚至关卡蓝图,利用Creat ...
- Python 基于 xlsxwriter 实现百万数据导出 excel
追加导出 + 自动切换 sheet ️ excel 中的每个 sheet 最多只能保存 1048576 行数据 # 获取项目的根路径 rootPath curPath = os.path.abspat ...
- 使用fiddler抓取HTTPS的数据包(抓取App端的数据包)
众所周知,我们在做接口测试的时候有两种情况: 第一种是先拿到接口测试规范文档,再去做接口测试. 第二种是没有接口文档,只有通过自己抓包. 那么说到抓包,就不得不说抓包工具,对于浏览器web端,我们只需 ...
- 第一个hello驱动
Linux驱动程序的分类 字符设备驱动.块设备驱动和网络设备驱动. Linux驱动程序运行方式 把驱动程序编译进内核里面,这样内核启动后就会自动运行驱动程序了: 把驱动程序编译成以.ko为后缀的模块文 ...
- #树上带修莫队,树链剖分#洛谷 4074 [WC2013]糖果公园
题目 分析 考虑将树转换成序列求解,那就用欧拉序,入栈一次出栈一次正好抵消掉 注意当起点不是LCA的时候要将起点加入,剩下就是带修莫队板子题了 代码 #include <cstdio> # ...
- 详解SSL证书系列(10)SSL的加密算法
HTTPS协议的主要功能依赖于SSL,SSL全称为安全套接层(Secure Socket Layer). SSL的功能主要依赖于三类加密算法,散列函数,对称加密和非对称加密. HASH算法 HAS ...
- RabbitMQ 11 死信队列
死信队列 概述 消息队列中的数据,如果迟迟没有消费者来处理,就会一直占用消息队列的空间. 比如抢车票的场景,用户下单高铁票之后,会进行抢座,然后再进行付款,但是如果用户下单之后并没有及时的付款,这张票 ...
- FreeMarker 去除循环末尾的符号
在使用 FreeMarker 模板引擎来生成文件时,经常会使用到 list 标签用于循环生成. 有时会遇到需要处理末尾符号的情况,比如 Json 文件,循环生成的标签中末尾是不需要 , 的,例如: & ...
- 聚焦AI新技术,HMS Core机器学习服务为移动应用智能化注入新动力
近年来,以机器学习为代表的人工智能技术(以下简称AI技术)蓬勃发展.新算法层出不穷,开发出的图像识别.自然语言.活体检测等能力令智能化的未来生活不再遥不可及.同时,这些AI技术正持续演化和发展,数据和 ...