Python网络爬虫-爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库
url=https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6
1.分析网页的源代码:右键--查看网页源代码.
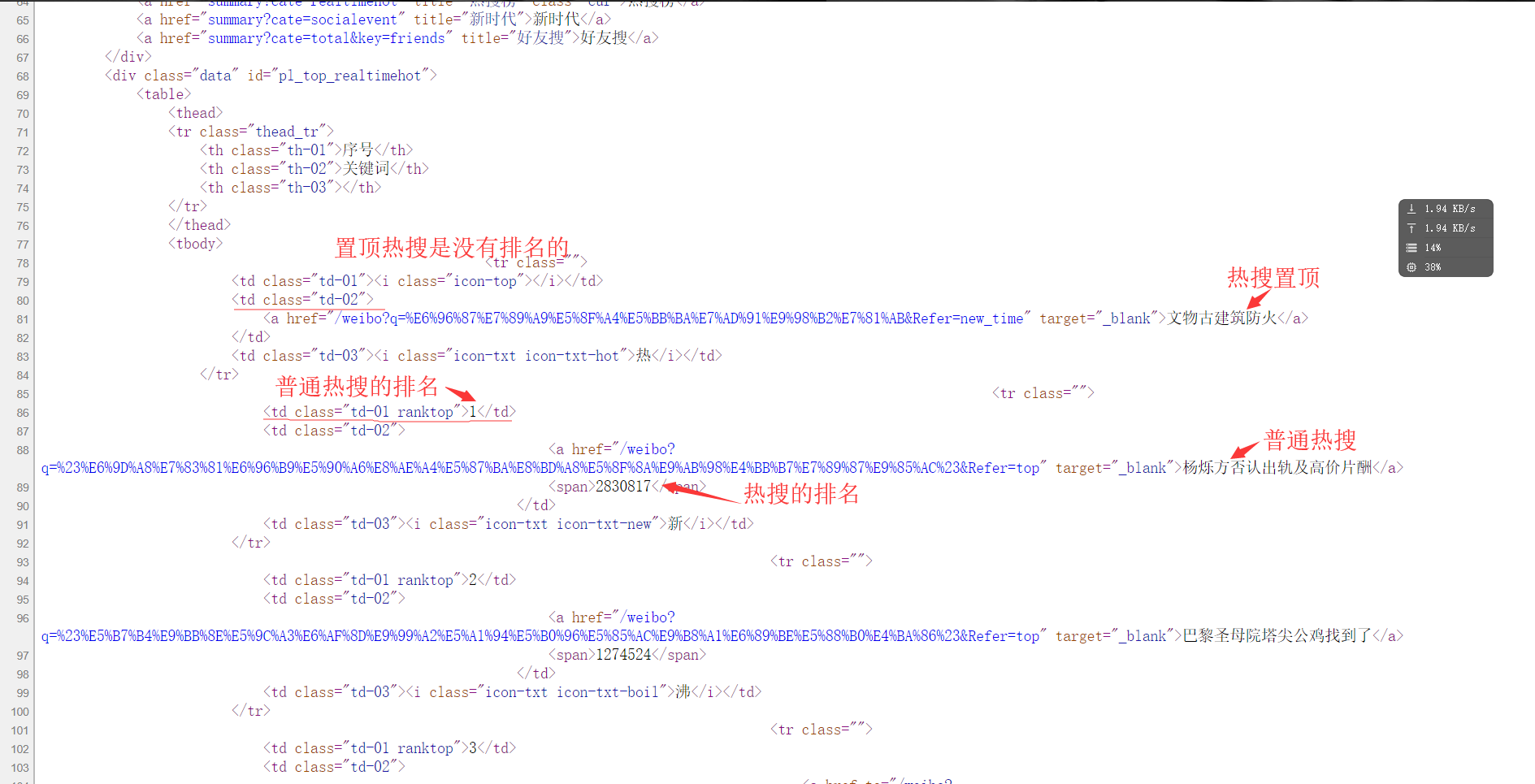
从网页代码中可以获取到信息
(1)热搜的名字都在<td class="td-02">的子节点<a>里
(2)热搜的排名都在<td class=td-01 ranktop>的里(注意置顶微博是没有排名的!)
(3)热搜的访问量都在<td class="td-02">的子节点<span>里
2.requests获取网页
(1)先设置url地址,然后模拟浏览器(这一步可以不用)防止被认出是爬虫程序。
###网址
url="https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
###模拟浏览器,这个请求头windows下都能用
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
(2)利用requests库的get()和lxml的etree()来获取网页代码
###获取html页面
html=etree.HTML(requests.get(url,headers=header).text)
3.构造xpath路径
上面第一步中三个xath路径分别是:
affair=html.xpath('//td[@class="td-02"]/a/text()')
rank=html.xpath('//td[@class="td-01 ranktop"]/text()')
view=html.xpath('//td[@class="td-02"]/span/text()')
xpath的返回结果是列表,所以affair、rank、view都是字符串列表
4.格式化输出
需要注意的是affair中多了一个置顶热搜,我们先将他分离出来。
top=affair[0]
affair=affair[1:]
这里利用了python的切片。
print('{0:<10}\t{1:<40}'.format("top",top))
for i in range(0, len(affair)):
print("{0:<10}\t{1:{3}<30}\t{2:{3}>20}".format(rank[i],affair[i],view[i],chr(12288)))
这里还是没能做到完全对齐。。。 5.全部代码
###导入模块
import requests
from lxml import etree ###网址
url="https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
###模拟浏览器
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'} ###主函数
def main():
###获取html页面
html=etree.HTML(requests.get(url,headers=header).text)
rank=html.xpath('//td[@class="td-01 ranktop"]/text()')
affair=html.xpath('//td[@class="td-02"]/a/text()')
view = html.xpath('//td[@class="td-02"]/span/text()')
top=affair[0]
affair=affair[1:]
print('{0:<10}\t{1:<40}'.format("top",top))
for i in range(0, len(affair)):
print("{0:<10}\t{1:{3}<30}\t{2:{3}>20}".format(rank[i],affair[i],view[i],chr(12288)))
main()
结果展示:

Python网络爬虫-爬取微博热搜的更多相关文章
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- nodejs实现定时爬取微博热搜
The summer is coming " 我知道,那些夏天,就像青春一样回不来. - 宋冬野 青春是回不来了,倒是要准备渡过在西安的第三个夏天了. 废话 我发现,自己对 coding 这 ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
- BeautifulSoup爬取微博热搜榜
获取url 设定请求头 requests发出get请求 实例化BeautifulSoup对象 BeautifulSoup提取数据 import requests 2 from bs4 import B ...
- python网络爬虫&&爬取网易云音乐
#爬取网易云音乐 url="https://music.163.com/discover/toplist" #歌单连接地址 url2 = 'http://music.163.com ...
- Python网络爬虫 - 爬取中证网银行相关信息
最终版:07_中证网(Plus -Pro).py # coding=utf-8 import requests from bs4 import BeautifulSoup import io impo ...
- Python爬取微博热搜以及链接
基本操作,不再详述 直接贴源码(根据当前时间创建文件): import requests from bs4 import BeautifulSoup import time def input_to_ ...
随机推荐
- How to increase timeout for your ASP.NET Application ?
How to increase timeout for your ASP.NET Application ? 原文链接:https://www.techcartnow.com/increase-tim ...
- 多线程09-Mutex
))) { Console.WriteLine("second instance is runing" ...
- [2019杭电多校第七场][hdu6655]Just Repeat
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6655 题意是说两个人都有一些带有颜色的牌,两人轮流出牌,但是不能出对面出过的颜色的牌,最后谁不能出牌谁 ...
- Balanced Lineup poj3264 线段树
Balanced Lineup poj3264 线段树 题意 一串数,求出某个区间的最大值和最小值之间的差 解题思路 使用线段树,来维护最大值和最小值,使用两个查询函数,一个查区间最大值,一个查区间最 ...
- 用户权限管理数据库设计(RBAC)
RBAC(Role-Based Access Control,基于角色的访问控制),就是用户通过角色与权限进行关联.简单地说,一个用户拥有若干角色,每一个角色拥有若干权限.这样,就构造成“用户-角色- ...
- Sudoku (剪枝+状态压缩+预处理)
[题目描述] In the game of Sudoku, you are given a large 9 × 9 grid divided into smaller 3 × 3 subgrids. ...
- service worker介绍
原文:Service workers explained 译者:neal1991 welcome to star my articles-translator, providing you advan ...
- Node 12 值得关注的新特性
前言 时隔一年,Node.js 12 如约而至,正式发布第一个 Current 版本. 该版本带来了诸如: V8 更新带来好多不错的特性. HTTP 解析速度提升. 启动速度大幅提升. 更好的诊断报告 ...
- JSP学习(5)
JSP学习(5) 保存用户状态的两大机制 session对象 Cookie Cookie简介 是Web服务器保存在客户端的一系列文本信息 典型应用 判断注册用户是否已经登录 购物车处理 作用 对特定对 ...
- dotnet ef执行报错, VS 2019发布时配置项中的Entity Framework迁移项显示不出来
VS 2019发布时配置项中的Entity Framework迁移项显示不出来 dotnet ef dbcontext list --json “无法执行,因为找不到指定的命令或文件.可能的原因包括: ...