【经典爬虫案例】用Python爬取微博热搜榜!
一、爬取目标
您好,我是@马哥python说,一名10年程序猿。
本次爬取的目标是: 微博热搜榜
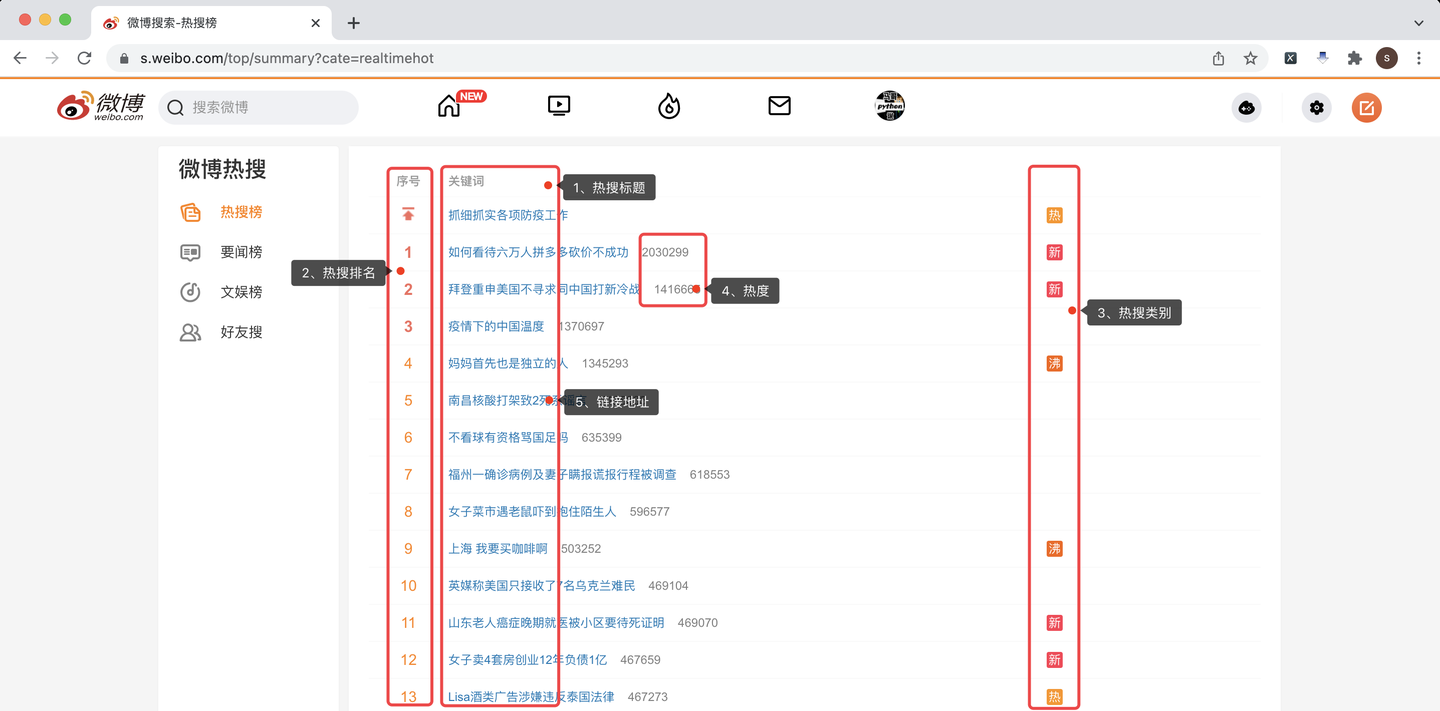
分别爬取每条热搜的:
热搜标题、热搜排名、热搜类别、热度、链接地址。
下面,对页面进行分析。
经过分析,此页面没有XHR链接通过,也就是说,没有采用AJAX异步技术。
所以,只能针对原页面进行爬取。
二、编写爬虫代码
2.1 前戏
首先,导入需要用到的库:
import pandas as pd # 存入excel数据
import requests # 向页面发送请求
from bs4 import BeautifulSoup as BS # 解析页面
定义一个爬取目标地址:
# 目标地址
url = 'https://s.weibo.com/top/summary?cate=realtimehot'
定义一个请求头:
# 请求头
header = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Mobile Safari/537.36',
'Host': 's.weibo.com',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh-Hans;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
# 定期更换Cookie
'Cookie': '换成自己的Cookie值'
}
其中,Cookie需要换成自己的Cookie值。
2.2 获取cookie
怎么查看自己的Cookie?
Chrome浏览器,按F12打开开发者模式,按照以下步骤操作:
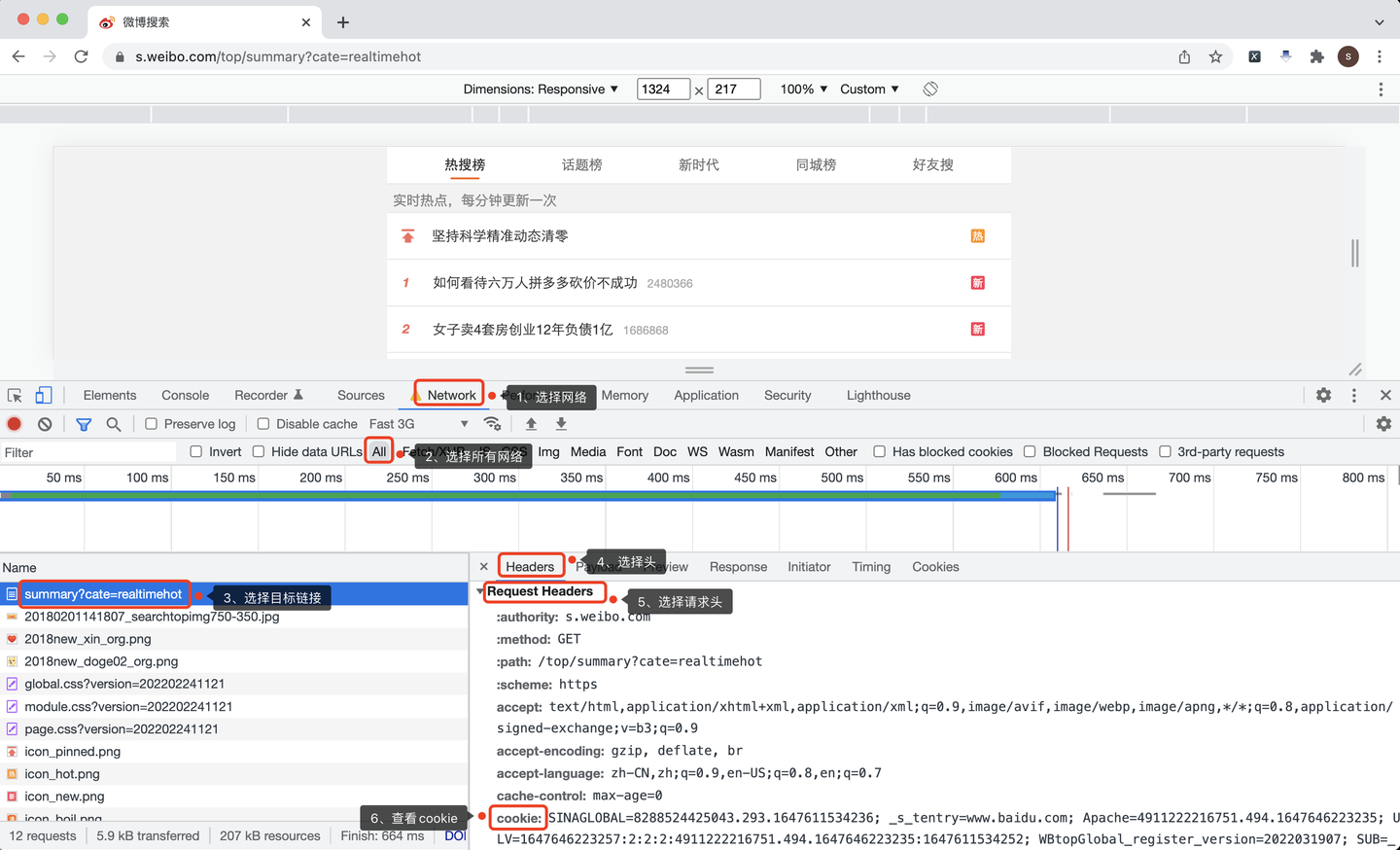
- 选择网络:Network
- 选择所有网络:All
- 选择目标链接地址
- 选择头:Headers
- 选择请求头:Request Headers
- 查看cookie值
2.3 请求页面
下面,向页面发送请求:
r = requests.get(url, headers=header) # 发送请求
2.4 解析页面
接下来,解析返回的页面:
soup = BS(r.text, 'html.parser')
```
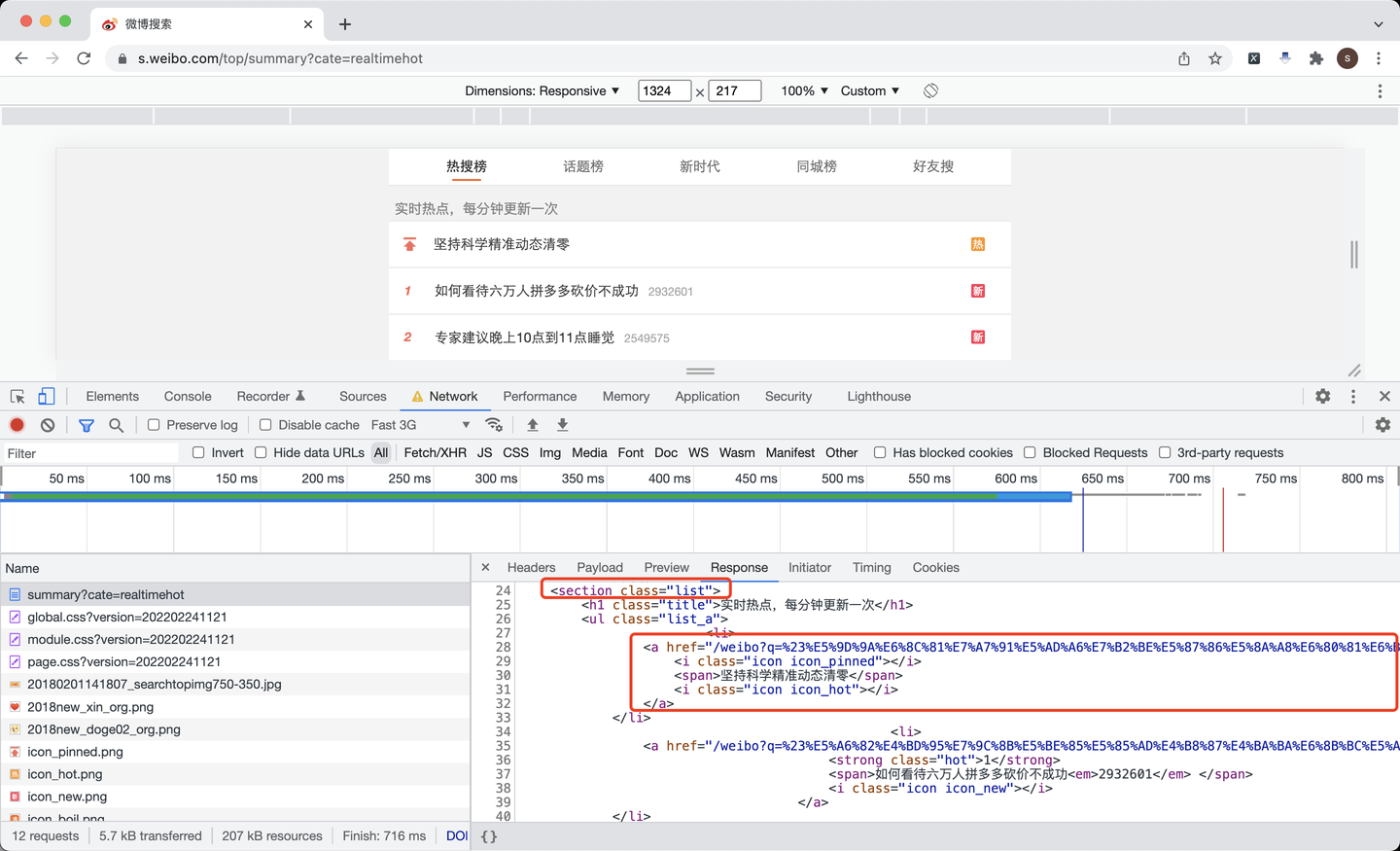
根据页面分析,每条热搜都放在了标签为section的、class值为list的数据里,里面每条热搜,又是一个a标签。
所以,根据这个逻辑,解析页面,以获取链接地址为例:
```python
items = soup.find('section', {'class': 'list'})
for li in items.find_all('li'):
# 链接地址
href = li.find('a').get('href')
href_list.append('https://s.weibo.com' + href)
页面其他元素,热搜标题、排名、热度、类别等获取代码,不再一一赘述。
2.5 转换热搜类别
其中,热搜类别这个元素需要注意,在页面上是一个个图标,背后对应的是class值,是个英文字符串,需要转换成对应的中文含义,定义以下函数进行转换:
def trans_icon(v_str):
"""转换热搜类别"""
if v_str == 'icon_new':
return '新'
elif v_str == 'icon_hot':
return '热'
elif v_str == 'icon_boil':
return '沸'
elif v_str == 'icon_recommend':
return '商'
else:
return '未知'
目前的转换函数包括了"新"、"热"、"沸"、"商"等类别。
我记得,微博热搜类别,是有个"爆"的,就是热度最高的那种,突然蹿升的最热的热点,爆炸性的。但是现在没有爆炸性新闻,所以我看不到"爆"背后的class值是什么。
后续如果有爆炸性热点,可以按照代码的逻辑,加到这个转换函数里来。
2.6 保存结果
依然采用我最顺手的to_excel方式,存入爬取的数据:
df = pd.DataFrame( # 拼装爬取到的数据为DataFrame
{
'热搜标题': text_list,
'热搜排名': order_list,
'热搜类别': type_list,
'热度': view_count_list,
'链接地址': href_list
}
)
df.to_excel('微博热搜榜.xlsx', index=False) # 保存结果数据
至此,整个爬取过程完毕。
2.7 查看结果数据
查看一下,保存到excel里的数据:

其中,第一条是置顶热搜,所以一共是 (1+50=51) 条数据。
演示视频:
https://www.bilibili.com/video/BV1Xb4y1p7Ka
三、获取完整源码
get完整代码:【最新爬虫案例】用Python爬取微博热搜榜!
我是@马哥python说,持续分享python源码干货中!
【经典爬虫案例】用Python爬取微博热搜榜!的更多相关文章
- BeautifulSoup爬取微博热搜榜
获取url 设定请求头 requests发出get请求 实例化BeautifulSoup对象 BeautifulSoup提取数据 import requests 2 from bs4 import B ...
- Python爬取微博热搜以及链接
基本操作,不再详述 直接贴源码(根据当前时间创建文件): import requests from bs4 import BeautifulSoup import time def input_to_ ...
- nodejs实现定时爬取微博热搜
The summer is coming " 我知道,那些夏天,就像青春一样回不来. - 宋冬野 青春是回不来了,倒是要准备渡过在西安的第三个夏天了. 废话 我发现,自己对 coding 这 ...
- Python网络爬虫-爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库 url=https://s.weibo.com/top/summary?Refer=top_hot&topnav=1& ...
- 【网络爬虫】【java】微博爬虫(一):小试牛刀——网易微博爬虫(自定义关键字爬取微博数据)(附软件源码)
一.写在前面 (本专栏分为"java版微博爬虫"和"python版网络爬虫"两个项目,系列里所有文章将基于这两个项目讲解,项目完整源码已经整理到我的Github ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- 2020不平凡的90天,Python分析三个月微博热搜数据带你回顾
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:刘早起早起 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- 【python网络编程】新浪爬虫:关键词搜索爬取微博数据
上学期参加了一个大数据比赛,需要抓取大量数据,于是我从新浪微博下手,本来准备使用新浪的API的,无奈新浪并没有开放关键字搜索的API,所以只能用爬虫来获取了.幸运的是,新浪提供了一个高级搜索功能,为我 ...
- 用python爬取微博数据并生成词云
很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,放在今天应该比较应景. 一年一度的虐汪节,是继续蹲在角落默 ...
- Python爬取酷狗飙升榜前十首(100)首,写入CSV文件
酷狗飙升榜,写入CSV文件 爬取酷狗音乐飙升榜的前十首歌名.歌手.时间,是一个很好的爬取网页内容的例子,对爬虫不熟悉的读者可以根据这个例子熟悉爬虫是如何爬取网页内容的. 需要用到的库:requests ...
随机推荐
- AXI4的PL与PS联合设计
AXI4的PL与PS联合设计 1.实验原理 在前面的学习中,解决了如何利用一个缓冲寄存器控制另外一个寄存器的输入输出配置.接下来就是如何将PL设计直接导入到PS中实现资源互换.PS是可以通过AXI4总 ...
- Selenium 八大元素定位方式
UI自动化测本质无非就是: 定位元素 -> 操作元素 -> 模拟页面动作 -> 断言结果 -> 生成测试报告. 所以我们做UI自动化的第一步就是定位元素,如果连元素都定位不到就 ...
- 【WCH以太网接口系列芯片】CH9121\9120、CH395\392以太网系列芯片的硬件电路注意事项
本篇基于沁恒微电子官方的以太网接口芯片的DEMO参考原理图进行分析,对一些注意事项进行标注,如果硬件设计上出现问题可以对照参考. CH912x系列: 1.CH9121:建议设计中可以将31脚RUN脚预 ...
- Python - 字典4
复制字典 您不能简单地通过输入 dict2 = dict1 来复制一个字典,因为 dict2 只会成为 dict1 的引用,对 dict1 的更改也会自动应用于 dict2. 有多种方法可以复制字典, ...
- 掌握 xUnit 单元测试中的 Mock 与 Stub 实战
引言 上一章节介绍了 TDD 的三大法则,今天我们讲一下在单元测试中模拟对象的使用. Fake Fake - Fake 是一个通用术语,可用于描述 stub或 mock 对象. 它是 stub 还是 ...
- 重新点亮linux 命令树————文件特殊权限[十一]
前言 简单介绍一下文件特殊权限. 正文 SUID 用于二进制可执行文件,执行命令时取得文件属组权限 如 /usr/bin/passwd 当我们使用passwd 修改密码的时候其实是以root用户身份进 ...
- 力扣455(java&python)-分发饼干(简单)
题目: 假设你是一位很棒的家长,想要给你的孩子们一些小饼干.但是,每个孩子最多只能给一块饼干. 对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸:并且每块饼干 j,都有 ...
- 如何使用 Serverless Devs 部署静态网站到函数计算(上)
简介:部署个静态网站到函数计算~ 前言 公司经常有一些网站需要发布上线,对比了几款不同的产品后,决定使用阿里云的函数计算(FC)来托管构建出来的静态网站. FC 弹性实例自带的500 Mb 存储空 ...
- 阿里云容器服务差异化 SLO 混部技术实践
简介:阿里巴巴在"差异化 SLO 混合部署"上已经有了多年的实践经验,目前已达到业界领先水平.所谓"差异化 SLO",就是将不同类型的工作负载混合运行在同一节 ...
- 逸仙电商Seata企业级落地实践
简介: 本文将会以逸仙电商的业务作为背景, 先介绍一下seata的原理, 并给大家进行线上演示, 由浅入深去介绍这款中间件, 以便读者更加容易去理解 Seata 这个中间件. 作者 | 张嘉伟(Git ...