理解HashMap的原理
.png)
static int hash( int h ) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ ( h >>> 12) ;
return h ^ (h >>> 7 ) ^ (h >>> 4);
}
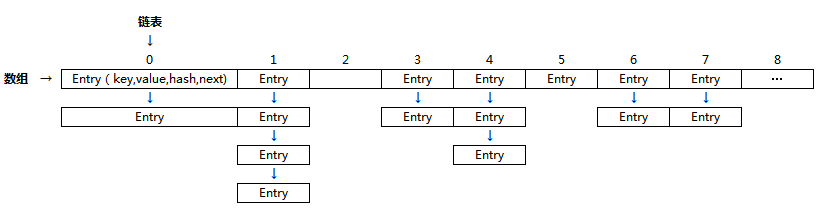
说明:该hash算法的内部实现乍一看的确很晦涩难懂。参数值h是key.hashCode(),很明显,该方法的意图就是根据key.hasCode()的值进行重新计算。为什么要这么做呢?因为HashMap要求key的hashCode值分布越均匀性能就越好(见上图,若hash函数计算出的hash值越均匀,链表的长度也就越均衡,就不会造成有的链表长度很短,而有的链表长度特别长的情况,我们知道,链表长度越长,检索效率就越慢)。而put到HashMap作为key的对象的hashCode可能五花八门,有的对象的hashCode可能还进行过重写,这可能导致put到HashMap中的key的hashCode值分布可能会不均衡,所以HashMap就利用这样一个算法对hashCode进行重新计算,以期望得到更加分布均衡的hashCode值。
static int indexFor( int h , int length) {
return h & (length - 1 );
}
说明:在计算机数学里有这么一个法则: 当SIZE满足大小是2的幂的时候,X % SIZE(取模操作)和 X & (SIZE-1)是等价的,不信?自己动手演算一下?因此我们知道了为什么HashMap要求我们提供的capacity大小是2的幂的原因了吧?用户提供给HashMap构造函数的capacity值可能不是2的幂,所以hashmap内部进行了验证并将其重设为最接近指定capacity值的2的幂的那个值:
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
介绍了前两个重要方法,下面欢迎我们熟悉的put方法出场:
public V put ( K key , V value ) {
if ( key == null)
return putForNullKey ( value) ;
int hash = hash (key . hashCode()) ;
int i = indexFor (hash , table . length) ;
for ( Entry <K , V> e = table [ i ]; e != null ; e = e. next ) {
Object k ;
//
if ( e .hash == hash && ((k = e .key ) == key || key .equals ( k))) {
V oldValue = e. value ;
e .value = value ;
e .recordAccess ( this) ;
return oldValue ;
}
}
modCount ++;
addEntry (hash , key , value , i ) ;
return null ;
}
- http://blog.csdn.net/csfreebird/article/details/7355282
- http://stackoverflow.com/questions/9335169/understanding-strange-java-hash-function
- http://stackoverflow.com/questions/299304/why-does-javas-hashcode-in-string-use-31-as-a-multiplier
理解HashMap的原理的更多相关文章
- 深入理解HashMap(原理,查找,扩容)
面试的时候闻到了Hashmap的扩容机制,之前只看到了Hasmap的实现机制,补一下基础知识,讲的非常好 原文链接: http://www.iteye.com/topic/539465 Hashmap ...
- 理解HashMap底层原理,一个简单的HashMap例子
package com.jl.testmap; /** * 自定义一个HashMap * @author JiangLai * */ public class MyHashMap<K,V> ...
- java基础之hashcode理解及hashmap实现原理及MD5
HashCode值 1. hashcode值是int的,64位.int hashCode(). 2. java object类默认的hashcode()计算方法是根据对象的内存地址来计算的.所以可由此 ...
- HashMap实现原理及源码分析
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出 ...
- JVM里面hashtable和hashmap实现原理
JVM里面hashtable和hashmap实现原理 文章分类:Java编程 转载 在hashtable和hashmap是java里面常见的容器类, 是Java.uitl包下面的类, 那么Hash ...
- 基础进阶(一)之HashMap实现原理分析
HashMap实现原理分析 1. HashMap的数据结构 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端. 数组 数组存储区间是连续的,占用内存严重,故空间复杂的很大.但数组的二 ...
- Java HashMap工作原理及实现
Java HashMap工作原理及实现 2016/03/20 | 分类: 基础技术 | 0 条评论 | 标签: HASHMAP 分享到:3 原文出处: Yikun 1. 概述 从本文你可以学习到: 什 ...
- HashMap实现原理及源码分析(JDK1.7)
转载:https://www.cnblogs.com/chengxiao/p/6059914.html 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技 ...
- HashMap 实现原理
深入Java集合学习系列:HashMap的实现原理 参考文献 引用文献:深入Java集合学习系列:HashMap的实现原理,大部分参考这篇博客,只对其中进行稍微修改 自己曾经写过的:Hashmap ...
随机推荐
- 着重基础之—Spring Boot 编写自己的过滤器
Spring Boot 编写自己的"过滤器" 又好久没有写博客进行总结了,说实话,就是 "懒",懒得总结,懒得动.之所以写这篇博客,是因为最近对接公司SSO服务的时候,需要自定义拦 ...
- 38 Cell-phone Emissions can change Brain Activity 手机辐射有可能改变大脑活动
Cell-phone Emissions can change Brain Activity 手机辐射有可能改变大脑活动 So many people use the cell phone so fr ...
- Linux教程:基础+中级+运维高级
视频内容40G:Linux基础视频.Linux中级视频.Linux运维高级视频+赠送 职业素质视频 +查用服务器安卓文档 目录 Linux基础教程81节 常用命令.文件管理命令详解.bash脚本编程. ...
- Myeclipse2014的Preview乱码问题
1.问题图样 2.问题探究:之前的版本没有这个问题,正常服务器部署也没有问题,而且改正了工程的编码设置 JSP的编码方式 3.问题解决:问题还是没有解决,最后找到了方法,似乎是跟本地编码反冲 选中pr ...
- LA 4670 Dominating Patterns (AC自动机)
题意:给定n个字符串和一个文本串,查找哪个字符串出现的次数的最多. 析:一匹配多,很明显是AC自动机.只需要对原来的进行修改一下,就可以得到这个题的答案, 计算过程中,要更新次数,并且要映射字符串.如 ...
- GitBash入门
转载自:http://www.cnblogs.com/randomsteps/p/5415116.html 作为一个初学者,我是跟着廖学峰老师的官方博客学习,这里只是做个笔记,哈哈,关于git的历史. ...
- C++标准模板库(STL)和容器
1.什么是标准模板库(STL)? (1)C++标准模板库与C++标准库的关系 C++标准模板库其实属于C++标准库的一部分,C++标准模板库主要是定义了标准模板的定义与声明,而这些模板主要都是 类模板 ...
- oss上传文件夹-cloud2-泽优软件
泽优软件云存储上传控件(cloud2)支持上传整个文件夹,并在云空间中保留文件夹的层级结构,同时在数据库中也写入层级结构信息.文件与文件夹层级结构关系通过id,pid字段关联. 本地文件夹结构 文件 ...
- 201709021工作日记--CAS解读
CAS主要参考博文:classtag http://www.jianshu.com/p/473e14d5ab2d CAS(Compare and swap)比较和替换是设计并发算法时用到的一种技术 ...
- PAT甲 1046. Shortest Distance (20) 2016-09-09 23:17 22人阅读 评论(0) 收藏
1046. Shortest Distance (20) 时间限制 100 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue The ...