Web自动化 - 选择操作元素 1
文章转自 白月黑羽教Python
所有的 UI (用户界面)操作 的自动化,都需要选择界面元素。
选择界面元素就是:先让程序能找到你要操作的界面元素。
先找到元素,才能操作元素。
选择元素的方法
程序 怎么才能找到 要操作的 web 界面元素?
方法就是要根据这个 web 元素的 特征 去选择。
元素的特征怎么查看?
可以使用浏览器的开发者工具栏帮我们查看、选择web 元素。
请大家安装最新版的Chrome浏览器(可以百度搜索下载)。
用chrome浏览器访问百度,按F12后,点击下图箭头处的Elements标签,即可查看页面对应的HTML 元素
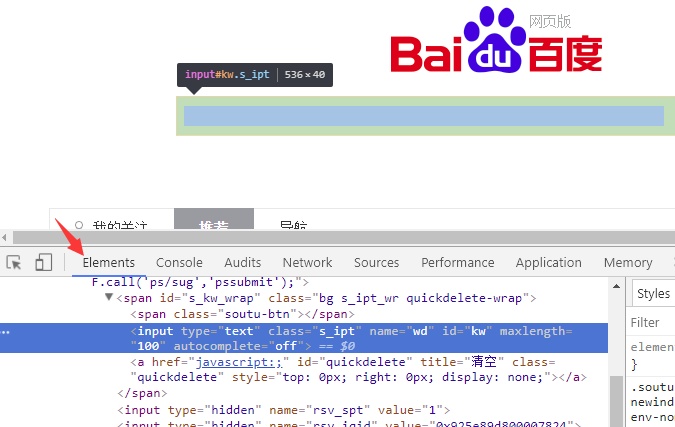
然后,再点击 最左边的图标,如下所示

之后,鼠标在界面上点击哪个元素,就可以查看该元素对应的html标签内容了。
比如,前面的图的高亮处,就是百度搜索输入框对应的input元素。
根据 元素的id 属性选择元素
大家仔细看上面的 input元素 内容,会发现它有一个属性叫id。

我们可以把 id 想象成元素的编号, 是用来在html中标记该元素的。 根据规范, 如果元素有id ,这个id 必须是当前html中唯一的。
所以如果元素有id, 根据id选择元素是最简单高效的方式。
下面的代码,就是用selenium 访问百度,并且在输入框中搜索 黑羽魔巫宗 。
大家可以运行一下看看。
from selenium import webdriver
# 创建 WebDriver 实例对象,指明使用chrome浏览器驱动
driver = webdriver.Chrome(r'd:\webdrivers\chromedriver.exe')
# WebDriver 实例对象的get方法 可以让浏览器打开指定网址
driver.get('https://www.baidu.com')
# 根据id选择元素,返回的就是该元素对应的WebElement对象
element = driver.find_element_by_id('kw')
# 通过该 WebElement对象,就可以对页面元素进行操作了
# 比如输入字符串到 这个 输入框里
element.send_keys('黑羽魔巫宗\n')
其中
driver = webdriver.Chrome(r'd:\webdrivers\chromedriver.exe')
返回的是 WebDriver 实例对象,我们可以通过这个实例对象来操控浏览器,比如 打开网址、选择界面元素等。
下面的代码
driver.find_element_by_id('kw')
就是使用 WebDriver 实例对象 的方法find_element_by_id, 这个方法就是 根据输入框元素的 id 值 ‘kw’ 来选择到元素。
选择到元素之后, find_element_by_id 方法会返回一个 WebElement, 我们通过这个对象就可以操控对应的界面元素。
比如 send_keys 方法就是在对应的元素中输入字符串,
而 click 方法就可以点击该元素。
根据 class属性、tag名 选择元素
除了根据元素的id ,我们还可以根据元素的class 属性选择元素。
大家请访问这个网址 http://www.python3.vip/doc/tutorial/python/code/sample1.html
这个网址对应的html内容 有如下的部分
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>白月黑羽测试网页1</title>
<style>
.animal {color: red;}
</style>
</head>
<body>
<div class="plant"><span>土豆</span></div>
<div class="plant"><span>洋葱</span></div>
<div class="plant"><span>白菜</span></div>
<div class="animal"><span>狮子</span></div>
<div class="animal"><span>老虎</span></div>
<div class="animal"><span>山羊</span></div>
</body>
</html>
所有的植物元素都有个class属性 值为 plant。
所有的动物元素都有个class属性 值为 animal。
如果我们要选择所有的 动物, 就可以使用方法 find_elements_by_class_name
driver.find_elements_by_class_name('animal')
注意
find_elements_by_class_name 方法返回的是找到的符合条件的所有元素 (这里有3个元素), 放在一个列表中返回。
而如果我们使用 find_element_by_class_name (注意少了一个s) 方法, 就只会返回第一个元素。
大家可以运行如下代码看看。
from selenium import webdriver
# 创建 WebDriver 实例对象,指明使用chrome浏览器驱动
driver = webdriver.Chrome(r'd:\webdrivers\chromedriver.exe')
# WebDriver 实例对象的get方法 可以让浏览器打开指定网址
driver.get('http://www.python3.vip/doc/tutorial/python/code/sample1.html')
# 根据 class name 选择元素,返回的是 一个列表
# 里面 都是class 属性值为 animal的元素对应的 WebElement对象
elements = driver.find_elements_by_class_name('animal')
# 取出列表中的每个 WebElement对象,打印出其text属性的值
# text属性就是该 WebElement对象对应的元素在网页中的文本内容
for element in elements:
print(element.text)
如果我们把
elements = driver.find_elements_by_class_name('animal')
去掉一个s ,改为
element = driver.find_element_by_class_name('animal')
print(element.text)
那么返回的就是第一个class 属性为 animal的元素, 也就是这个元素
<div class="animal"><span>狮子</span></div>
类似的,我们可以通过方法 find_elements_by_tag_name ,选择所有的tag名为 div的元素,如下所示
from selenium import webdriver
# 创建 WebDriver 实例对象,指明使用chrome浏览器驱动
driver = webdriver.Chrome(r'd:\webdrivers\chromedriver.exe')
# WebDriver 实例对象的get方法 可以让浏览器打开指定网址
driver.get('http://www.python3.vip/doc/tutorial/python/code/sample1.html')
# 根据 tag name 选择元素,返回的是 一个列表
# 里面 都是 tag 名为 div 的元素对应的 WebElement对象
elements = driver.find_elements_by_tag_name('div')
# 取出列表中的每个 WebElement对象,打印出其text属性的值
# text属性就是该 WebElement对象对应的元素在网页中的文本内容
for element in elements:
print(element.text)
等待界面元素出现
在我们进行网页操作的时候, 有的元素内容不是可以立即出现的, 可能会等待一段时间。
比如 百度搜索一个词语, 我们点击搜索后, 浏览器需要把这个搜索请求发送给百度服务器, 百度服务器进行处理后,把搜索结果返回给我们。
只是通常百度服务器的处理比较快,我们感觉好像是立即出现了搜索结果。
百度搜索的每个结果 对应的界面元素 其ID 分别是数字 1, 2 ,3, 4 。。。
如下

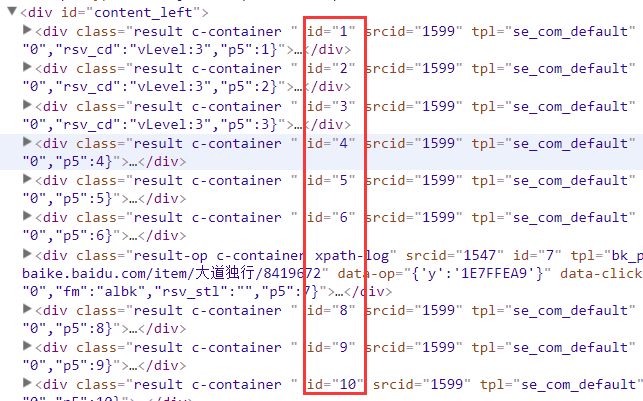
那么我们可以试试用如下代码 来将 第一个搜索结果里面的文本内容 打印出来
from selenium import webdriver
driver = webdriver.Chrome(r'd:\webdrivers\chromedriver.exe')
driver.get('https://www.baidu.com')
element = driver.find_element_by_id('kw')
element.send_keys('黑羽魔巫宗\n')
# id 为 1 的元素 就是第一个搜索结果
element = driver.find_element_by_id('1')
# 打印出 第一个搜索结果的文本字符串
print (element.text)
如果大家去运行一下,就会发现有如下异常抛出
selenium.common.exceptions.NoSuchElementException:
Message: no such element:
Unable to locate element: {"method":"id","selector":"1"}
NoSuchElementException 的意思就是在当前的网页上 找不到该元素, 就是找不到 id 为 1 的元素。
为什么呢?
因为我们的代码执行的速度比 百度服务器响应的速度 快。
百度还没有来得及 返回搜索结果,我们就执行了如下代码
element = driver.find_element_by_id('1')
在那短暂的瞬间, 网页上是没有用 id为1的元素的 (因为还没有搜索结果呢)。自然就会报告错误 id为1 的元素不存在了。
那么怎么解决这个问题呢?
很多聪明的读者可以想到, 点击搜索后, 用sleep 来 等待几秒钟, 等百度服务器返回结果后,再去选择 id 为1 的元素, 就像下面这样
from selenium import webdriver
driver = webdriver.Chrome(r'd:\webdrivers\chromedriver.exe')
driver.get('https://www.baidu.com')
element = driver.find_element_by_id('kw')
element.send_keys('黑羽魔巫宗\n')
# 等待 2 秒
from time import sleep
sleep(2)
# 2 秒 过后,再去搜索
element = driver.find_element_by_id('1')
# 打印出 第一个搜索结果的文本字符串
print (element.text)
大家可以运行一下,基本是可以的,不会再报错了。
但是这样的方法 有个很大的问题,就是设置等待多长时间合适呢?
这次百度网站反应可能比较快,我们等了一秒钟就可以了。
但是谁知道下次他的反应是不是还这么快呢?百度也曾经出现过服务器瘫痪的事情。
可能有的读者说,我干脆sleep比较长的时间, 等待 20 秒, 总归可以了吧?
这样也有很大问题,假如一个自动化程序里面需要10次等待, 就要花费 200秒。 而可能大部分时间, 服务器反映都是很快的,根本不需要等20秒, 这样就造成了大量的时间浪费了。
Selenium提供了一个更合理的解决方案,是这样的:
当发现元素没有找到的时候, 并不 立即抛出 找不到元素的异常。
而是周期性(每隔半秒钟)重新寻找该元素,直到该元素找到,
或者超出指定最大等待时长,这时才 抛出异常(如果是 find_elements 则是返回空列表)。
Selenium 的 Webdriver 对象 有个方法叫 implicitly_wait
该方法接受一个参数 就是指定的 最大等待时长。
如果我们 加入如下代码
driver.implicitly_wait(10)
那么后续所有的 find_element 或者 find_elements 之类的方法调用 都会采用上面的策略。
就是找不到元素 每隔 半秒钟 再去界面上查看一次, 直到找到该元素, 或者 过了10秒钟 最大时长。
这样,我们的百度搜索的例子的最终代码如下
from selenium import webdriver
driver = webdriver.Chrome()
# 设置最大等待时长为 10秒
driver.implicitly_wait(10)
driver.get('https://www.baidu.com')
element = driver.find_element_by_id('kw')
element.send_keys('黑羽魔巫宗\n')
element = driver.find_element_by_id('1')
print (element.text)
大家再运行一下,可以发现不会有错误了。
访问原文网站,看 下一篇 操作web界面 2
文章转自 白月黑羽教Python
Web自动化 - 选择操作元素 1的更多相关文章
- Web自动化 - 选择操作元素 2
文章转自 白月黑羽教Python 前面我们看到了根据 id.class属性.tag名 选择元素. 如果我们要选择的 元素 没有id.class 属性, 这时候我们通常可以通过 CSS selector ...
- Appium之选择/操作元素
Appium是如何选择.操作元素的呢? appium自动化 ------ 选择界面 元素 操作元素 ------- ① 点击 ② 输入字符 ③ 拖拽 ④ 获取页面元素的各种属性 根据appium ...
- Selenium Web 自动化 - 如何找到元素
Selenium Web 自动化 - 如何找到元素 2016-07-29 1. 什么是元素? 元素:http://www.w3school.com.cn/html/html_elements.asp ...
- web自动化 -- js操作(滑动屏幕、修改页面)
一.selenium对 js 的操作方法 1.先定义 js 操作 或者 定义 目标元素 2.执行 js 操作: driver.execute_script(js操作) 或者 ...
- Selenium Web 自动化
1 Selenium Web 自动化 - Selenium(Java)环境搭建 2 Selenium Web 自动化 - 如何找到元素 3 Selenium Web 自动化 - Selenium常用A ...
- 【Selenium01篇】python+selenium实现Web自动化:搭建环境,Selenium原理,定位元素以及浏览器常规操作!
一.前言 最近问我自动化的人确实有点多,个人突发奇想:想从0开始讲解python+selenium实现Web自动化测试,请关注博客持续更新! 二.话不多说,直接开干,开始搭建自动化测试环境 这里以前在 ...
- Web自动化必会知识:「Web基础、元素定位、元素操作、Selenium运行原理、项目实战+框架」
1.web 基础-html.dom 对象.js 基本语法 Dom 对象里面涉及元素定位以及对元素的修改.因为对元素操作当中涉及的一些 js 操作,js 基本语法要会用.得要掌握前端的基本用法.为什么要 ...
- 【Selenium03篇】python+selenium实现Web自动化:元素三类等待,多窗口切换,警告框处理,下拉框选择
一.前言 最近问我自动化的人确实有点多,个人突发奇想:想从0开始讲解python+selenium实现Web自动化测试,请关注博客持续更新! 这是python+selenium实现Web自动化第三篇博 ...
- 【python+selenium的web自动化】- 元素的常用操作详解(一)
如果想从头学起selenium,可以去看看这个系列的文章哦! https://www.cnblogs.com/miki-peng/category/1942527.html 本篇主要内容:1.元素 ...
随机推荐
- Oracle实现递归查询
前几天在开发的过程中遇到一个递归查询的问题,java代码大致是这样的: // 递归得到四级机构对象 public UserManagerDept getuserManagerDeptBy(String ...
- Hdu2102 A计划 2017-01-18 14:40 60人阅读 评论(0) 收藏
A计划 Time Limit : 3000/1000ms (Java/Other) Memory Limit : 32768/32768K (Java/Other) Total Submissio ...
- hdu 5023 线段树+状压
http://acm.hdu.edu.cn/showproblem.php?pid=5023 在片段上着色,有两种操作,如下: 第一种:P a b c 把 a 片段至 b 片段的颜色都变为 c . 第 ...
- spring案列——annotation配置
一.需要的jar包 spring.jar commons-loggin.jar commons-loggin.jar commons-annotation.jar 二.项目结构 三.entity pa ...
- delphi 使用oauth的控件
unit OAuth; interface uses Classes, SysUtils, IdURI, Windows; type EOAuthException = class(Exception ...
- Android-Xml,PullParser,解析
在上一篇博客,Android-XML格式描述,介绍来XML在Android中的格式: 解析persons.xml文件内容: <?xml version="1.0" encod ...
- 【算法33】LRU算法
题目来源 LeetCode: https://leetcode.com/problems/lru-cache/ LRU简介 LRU (Least Recently Used,最近最少使用)算法是操作系 ...
- WinRT 中后台任务类的声明
要实现后台任务,需要实现IBackgroundTask接口 public sealed class SimpleTask : IBackgroundTask { public void Run(IBa ...
- vim 安装vim-javascript插件--Vundle管理
最近看了一下node.js,但是写的时候,vim对js没有很好的提示.于是就安装插件来处理,准备安装vim-javascript.但是安装github上面的插件时,推荐用Vundle和pathogen ...
- Linux - 修改文件编码
enca -L zh_CN -x UTF- file