深度学习基础系列(七)| Batch Normalization
Batch Normalization(批量标准化,简称BN)是近些年来深度学习优化中一个重要的手段。BN能带来如下优点:
- 加速训练过程;
- 可以使用较大的学习率;
- 允许在深层网络中使用sigmoid这种易导致梯度消失的激活函数;
- 具有轻微地正则化效果,以此可以降低dropout的使用。
但为什么BN能够如此有效?让我们来一探究竟。
一、Covariate Shift
Convariate shift是BN论文作者提出来的概念,其意是指具有不同分布的输入值对深度网络学习的影响。举个例子,假设我们有一个玫瑰花的深度学习网络,这是一个二分类的网络,1表示识别为玫瑰,0则表示非玫瑰花。我们先看看训练数据集的一部分:

直观来说,玫瑰花的特征表现很明显,都是红色玫瑰花。 再看看训练数据集的另一部分:

很明显,这部分数据的玫瑰花各种颜色都有,其特征分布与上述数据集是不一样的。通过下图我们可以再比较下:

图中右侧部分绿色圆圈指的是玫瑰,红色打叉指的是非玫瑰,蓝色线为深度学习最后训练出来的边界。这张图可以更加直观地比较出两个数据集的特征分布是不一样的,这种不一样也就是所谓的covariate shift,而这种分布不一致将减缓训练速度。
为什么这么说呢?输入值的分布不同,也可以理解为输入特征值的scale差异较大,与权重进行矩阵相乘后,会产生一些偏离较大地差异值;而深度学习网络需要通过训练不断更新完善,那么差异值产生的些许变化都会深深影响后层,偏离越大表现越为明显;因此,对于反向传播来说,这些现象都会导致梯度发散,从而需要更多的训练步骤来抵消scale不同带来的影响,也需要更多地步骤才能最终收敛。
而BN的作用就是将这些输入值进行标准化,降低scale的差异至同一个范围内。这样做的好处在于一方面提高梯度的收敛程度,加快训练速度;另一方面使得每一层可以尽量面对同一特征分布的输入值,减少了变化带来的不确定性,也降低了对后层网路的影响,各层网路变得相对独立。
也许上述的解释可能有些晦涩,让我们通过代码和图像来直观理解。
二、Batch Normalization
BN的计算公式如下图所示:

简单地说,通过计算均值和方差后,mini-batch的数据进行标准化,再加上β和γ可以使数据进行移动和缩放。
我们以某个CIFAR-10的数据为例,通过BN的转换来查看数据分布的前后变化,以下为示例代码:
import numpy as np
import matplotlib.pyplot as plt
import tensorflow.keras.backend as K
from tensorflow import keras (train_images, train_labels), (test_images, test_labels) = keras.datasets.cifar10.load_data() # 输入图片尺寸为(32, 32, 3),经flatten后大小为(3072, 1)
x = train_images[0].reshape(-1) / 255
print("x:", x.shape)
# 假设我们的隐藏层第一层的输出为(1024, 1),则反推权重大小为(1024, 3072)
w = K.eval(K.random_normal_variable(shape=(1024, 3072), mean=0, scale=1))
print("w:", w.shape)
# 进行矩阵乘法得到大小为(1024, 1)的集合z
z = np.dot(w, x)
print("z:", z.shape) a = K.constant(z)
# 求均值
mean = K.mean(a)
print("mean:", K.eval(mean))
var = K.var(a)
# 求方差
print("var:", K.eval(var))
# 对z进行batch normalization,gamma为0表示不进行移动,beta为0.25表示将normal后的值压缩至1/4大小
a = K.eval(K.batch_normalization(a, mean, var, 0, 0.25))
# flatten normal值
a = a.reshape(-1)
print("batch_normal_a:", a.shape) #以图的方式直观展示without_BN和with_BN的区别
p1 = plt.subplot(211)
p1.hist(z, 50, density=1, facecolor='g', alpha=0.75)
p1.set_title("data distribution without BN")
p1.set_xlabel('data range')
p1.set_ylabel('probability')
p1.grid(True)
#p1.axis([-4, 4, 0, 1]) p2 = plt.subplot(212)
p2.hist(a, 50, density=1, facecolor='g', alpha=0.75)
p2.set_title("data distribution with BN")
p2.set_xlabel('data range')
p2.set_ylabel('probability')
p2.grid(True)
#p2.axis([-4, 4, 0, 1]) plt.subplots_adjust(hspace=1)
plt.show()
其图像为:

从图像分析可知,数据经过标准化后,其形状保持大致不变,但尺寸被我们压缩至(-1, 1)之间,而原尺寸在(-80,80)之间。
通过平移和缩放,BN可以使数据被限定在我们想要的范围内,所以每层的输出数据都进行BN的话,可以使后层网络面对稳定的输入值,降低梯度发散的可能,从而加快训练速度;同时也意味着允许使用大点的学习率,加快收敛过程。
被缩放的数据让使用sigmoid或tanh激活函数在深层网络变成可能,并且在实际应用中β和γ是可以学习的,下图是一个直观的解释图。

三、Batch Normalizaiotn的实际应用
理论结合实践才能确定是否有用,让我们以keras举例,看看BN是否能提高效率。

上图简要地绘制了BN在神经网络中的位置,在每层网络的激活函数前。与前述例子不同之处在于,数据不是单个进行标准化,而是以mini batch集合的方式进行标准化。
我们通过下述代码来比较和观察without_BN模型和with_BN模型的差异:
import keras
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten, BatchNormalization
from keras.layers import Conv2D, MaxPooling2D
from matplotlib import pyplot as plt
import numpy as np # 为保证公平起见,两种方式都使用相同的随机种子
np.random.seed(7)
batch_size = 32
num_classes = 10
epochs = 100
data_augmentation = True # The data, split between train and test sets:
(x_train, y_train), (x_test, y_test) = cifar10.load_data() # Convert class vectors to binary class matrices.
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes) x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255 # without_BN模型的训练
model_without_bn = Sequential()
model_without_bn.add(Conv2D(32, (3, 3), padding='same',
input_shape=x_train.shape[1:]))
model_without_bn.add(Activation('relu'))
model_without_bn.add(Conv2D(32, (3, 3)))
model_without_bn.add(Activation('relu'))
model_without_bn.add(MaxPooling2D(pool_size=(2, 2)))
model_without_bn.add(Dropout(0.25)) model_without_bn.add(Conv2D(64, (3, 3), padding='same'))
model_without_bn.add(Activation('relu'))
model_without_bn.add(Conv2D(64, (3, 3)))
model_without_bn.add(Activation('relu'))
model_without_bn.add(MaxPooling2D(pool_size=(2, 2)))
model_without_bn.add(Dropout(0.25)) model_without_bn.add(Flatten())
model_without_bn.add(Dense(512))
model_without_bn.add(Activation('relu'))
model_without_bn.add(Dropout(0.5))
model_without_bn.add(Dense(num_classes))
model_without_bn.add(Activation('softmax')) opt = keras.optimizers.rmsprop(lr=0.0001, decay=1e-6) model_without_bn.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
if not data_augmentation:
history_without_bn = model_without_bn.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
shuffle=True)
else:
# 使用数据增强获取更多的训练数据
datagen = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True)
datagen.fit(x_train)
history_without_bn = model_without_bn.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size), epochs=epochs,
validation_data=(x_test, y_test), workers=4) # with_BN模型的训练
model_with_bn = Sequential()
model_with_bn.add(Conv2D(32, (3, 3), padding='same', input_shape=x_train.shape[1:]))
model_with_bn.add(BatchNormalization())
model_with_bn.add(Activation('relu'))
model_with_bn.add(Conv2D(32, (3, 3)))
model_with_bn.add(BatchNormalization())
model_with_bn.add(Activation('relu'))
model_with_bn.add(MaxPooling2D(pool_size=(2, 2))) model_with_bn.add(Conv2D(64, (3, 3), padding='same'))
model_with_bn.add(BatchNormalization())
model_with_bn.add(Activation('relu'))
model_with_bn.add(Conv2D(64, (3, 3)))
model_with_bn.add(BatchNormalization())
model_with_bn.add(Activation('relu'))
model_with_bn.add(MaxPooling2D(pool_size=(2, 2))) model_with_bn.add(Flatten())
model_with_bn.add(Dense(512))
model_with_bn.add(BatchNormalization())
model_with_bn.add(Activation('relu'))
model_with_bn.add(Dense(num_classes))
model_with_bn.add(BatchNormalization())
model_with_bn.add(Activation('softmax')) opt = keras.optimizers.rmsprop(lr=0.001, decay=1e-6) model_with_bn.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy']) if not data_augmentation:
history_with_bn = model_without_bn.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
shuffle=True)
else:
# 使用数据增强获取更多的训练数据
datagen = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True)
datagen.fit(x_train)
history_with_bn = model_with_bn.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size), epochs=epochs,
validation_data=(x_test, y_test), workers=4) # 比较两种模型的精确度
plt.plot(history_without_bn.history['val_acc'])
plt.plot(history_with_bn.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Validation Accuracy')
plt.xlabel('Epoch')
plt.legend(['No Batch Normalization', 'With Batch Normalization'], loc='lower right')
plt.grid(True)
plt.show() # 比较两种模型的损失率
plt.plot(history_without_bn.history['loss'])
plt.plot(history_without_bn.history['val_loss'])
plt.plot(history_with_bn.history['loss'])
plt.plot(history_with_bn.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Training Loss without BN', 'Validation Loss without BN', 'Training Loss with BN', 'Validation Loss with BN'], loc='upper right')
plt.show()
两种模型的代码差异主要为两点:
- with_BN模型放弃了dropout函数,因为BN本身带有轻微地正则效果
- with_BN的学习率较without_BN模型放大了10倍
本模型中,我们使用了数据增强技术,我们来看看最终的比较图像:
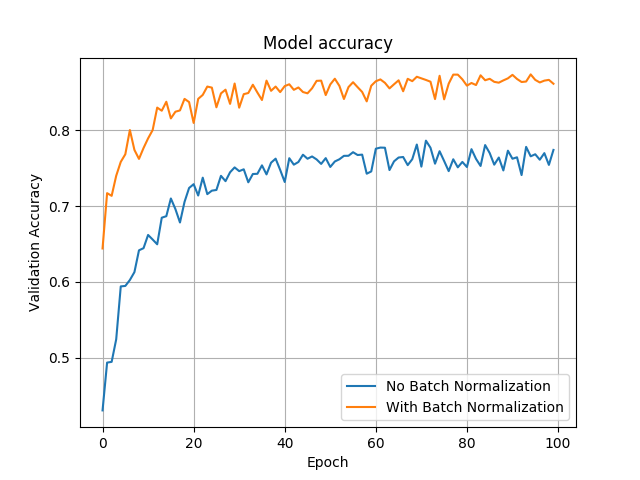
上图显示,测试数据集的精确度明显with_BN模型(87%)要高于without_BN模型(77%)。从训练速度来说,with_BN模型大概在第22代时已经很接近于最终收敛,而without_BN模型大概在第40代时接近于最终收敛,说明with_BN模型也会比较快。
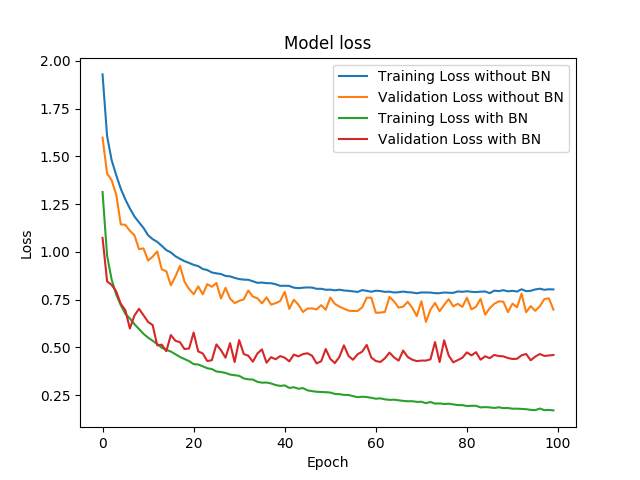
再比较看看损失度,明显可以看出无论是训练集还是测试集,with_BN模型要低于without_BN模型。
四、结论
BN对于优化神经网络,加快训练速度甚至在提高准确度、降低损失度方面都能发挥积极作用,当然想要取得理想的效果也得需要反复地尝试各种组合(比如上述的例子,如果去掉数据增强技术,在我的测试结果,显示测试集的损失度反而更高,过拟合更严重)。
深度学习基础系列(七)| Batch Normalization的更多相关文章
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- 转载-【深度学习】深入理解Batch Normalization批标准化
全文转载于郭耀华-[深度学习]深入理解Batch Normalization批标准化: 文章链接Batch Normalization: Accelerating Deep Network T ...
- 深度学习(八) Batch Normalization
一:BN的解释: 定义: 顾名思义,batch normalization嘛,就是“批规范化”咯.Google在ICML文中描述的非常清晰,即在每次SGD时,通过mini-batch来对相应的act ...
- 【深度学习】深入理解Batch Normalization批标准化
这几天面试经常被问到BN层的原理,虽然回答上来了,但还是感觉答得不是很好,今天仔细研究了一下Batch Normalization的原理,以下为参考网上几篇文章总结得出. Batch Normaliz ...
- 深度学习基础系列(十一)| Keras中图像增强技术详解
在深度学习中,数据短缺是我们经常面临的一个问题,虽然现在有不少公开数据集,但跟大公司掌握的海量数据集相比,数量上仍然偏少,而某些特定领域的数据采集更是非常困难.根据之前的学习可知,数据量少带来的最直接 ...
- 深度学习基础系列(四)| 理解softmax函数
深度学习最终目的表现为解决分类或回归问题.在现实应用中,输出层我们大多采用softmax或sigmoid函数来输出分类概率值,其中二元分类可以应用sigmoid函数. 而在多元分类的问题中,我们默认采 ...
- 深度学习基础系列(十)| Global Average Pooling是否可以替代全连接层?
Global Average Pooling(简称GAP,全局池化层)技术最早提出是在这篇论文(第3.2节)中,被认为是可以替代全连接层的一种新技术.在keras发布的经典模型中,可以看到不少模型甚至 ...
- 深度学习基础系列(三)| sigmoid、tanh和relu激活函数的直观解释
常见的激活函数有sigmoid.tanh和relu三种非线性函数,其数学表达式分别为: sigmoid: y = 1/(1 + e-x) tanh: y = (ex - e-x)/(ex + e-x) ...
随机推荐
- SpringBoot 线程池配置 实现AsyncConfigurer接口方法
目的是: 通过实现AsyncConfigurer自定义线程池,包含异常处理 实现AsyncConfigurer接口对异常线程池更加细粒度的控制 *a) 创建线程自己的线程池 b) 对void ...
- 一些达成共识的JavaScript编码约定[转]
如果你的代码易于阅读,那么代码中bug也将会很少,因为一些bug可以很容被调试,并且,其他开发者参与你项目时的门槛也会比较低.因此,如果项目中有多人参与,采取一个有共识的编码风格约定非常有必要.与其他 ...
- python的数字IP实现
第一种方法: import socket, struct >>> def ip2num(ip): ... return struct.unpack("!L", s ...
- Python练习-面向过程编程-模拟Grep命令
其实这个面向过程编写程序,是编写程序的基础,所以一定要好好掌握 此程序涉及知识点:装饰器,生成器,协程器应用 # 编辑者:闫龙 import os Distinct = [] #定义一个列表用于判断重 ...
- UNIX网络编程 第1章:简介和TCP/IP
1.1 按1.9节未尾的步骤找出你自己的网络拓扑的信息. 1.2 获取本书示例的源代码(见前言),编译并测试图1-5所示的TCP时间获取客户程序.运行这个程序若干次,每次以不同IP地址作为命令行参数. ...
- pytorch--cnn的理解
class Model(nn.Module): def __init__(self): super(Model, self).__init__() self.conv1 = nn.Conv2d(1, ...
- 搭建本地git服务器
最近因为项目需求,需要实现一个原型系统,加上后期项目需要多人协作,考虑采用了git做版本控制. 这里主要简要描述下git服务器和客户端的搭建和配置. 1.git服务器 (1)安装git sudo ap ...
- 大数据系列之分布式大数据查询引擎Presto
关于presto部署及详细介绍请参考官方链接 http://prestodb-china.com PRESTO是什么? Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持G ...
- Python之协程(coroutine)
Python之协程(coroutine) 标签(空格分隔): Python进阶 coroutine和generator的区别 generator是数据的产生者.即它pull data 通过 itera ...
- 使用postman做接口测试(三)
三,接口用例的设计 个人感觉用例的设计才是重要的哈,网上查了一些资料总结了一下 1.业务流程测试 通过性验证: 1, 按照接口文档上的参数,正常传参,是否可以返回正确的结果 2, 是否满足前提条件,比 ...