SKLearn数据集API(二)
注:本文是人工智能研究网的学习笔记
计算机生成的数据集
用于分类任务和聚类任务,这些函数产生样本特征向量矩阵以及对应的类别标签集合。
| 数据集 | 简介 |
|---|---|
| make_blobs | 多类单标签数据集,为每个类分配一个或者多个正态分布的点集,提供了控制每个数据点的参数:中心点(均值),标准差,常用于聚类算法。 |
| make_classification | 多类单标签数据集,为每个类分配了一个或者多个正态分布的点集。提供了为数据集添加噪声的方式,包括维度相性,无效特征和冗余特征等。 |
| make_gaussian_quantiles | 将一个单高斯分布的点集活粉为两个数量均等的点集,作为两类。 |
| make_hastie_10_2 | 产生一个相似的二元分类器数据集,有10个维度。 |
| make_circles/make_moons | 产生二维分类数据集来测试某些算法(e.g.centroid-based clustering或linear classfication)的性能。可以为数据集添加噪声,可以为二元分类器产生一些球形判决表面的数据。 |
用于多标签分类任务
| 数据集 | 简介 |
|---|---|
| make_multilabel_classification | 产生多类多标签随机样本,这些样本模拟了从很多话题的混合分布中抽取的词袋模型,每个文档的话题数量符合泊松分布,话题本身则从一个固定的随机分布中抽取出来,同样的,单词数量也是泊松分布抽取,句子则是从多项式抽取。 |
用于回归任务的
| 数据集 | 简介 |
|---|---|
| make_regression | 产生回归任务的数据集,期望目标输出是随机特征的稀疏随机线性组合,并且附带有噪声,它的有用的特征可能是不相关的,或者低秩的(引起目标值的变动的只有少量的集合特征) |
| make_sparse_uncorrelated | 产生四个特征的线性组合(固定参数)作为期望目标输出 |
| make_friedman1 | 采用了多项式和正弦变换 |
| make_friedman2 | 包含了特征的乘积和互换操作 |
| make_friedman3 | 类似于arctan变换 |
用于流行学习的
| 数据集 | 简介 |
|---|---|
| make_s_curve | 生成S型曲线数据集 |
| make_swiss_roll | 生成瑞士卷曲线数据集 |
用于因子分解的
| 数据集 | 简介 |
|---|---|
| make_low_rank_matrix | |
| make_sparse_coded_signal | |
| nake_spd_matrix | 产生的是随机的堆成的正定矩阵 |
| make_sparse_spd_matrix | 产生的是稀疏的堆成正定矩阵 |
make_blobs()
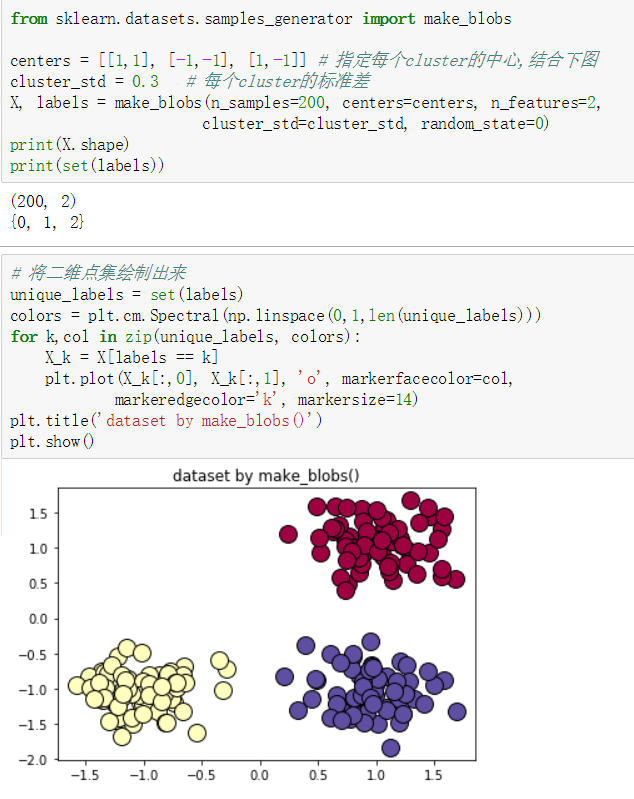
make_classification()
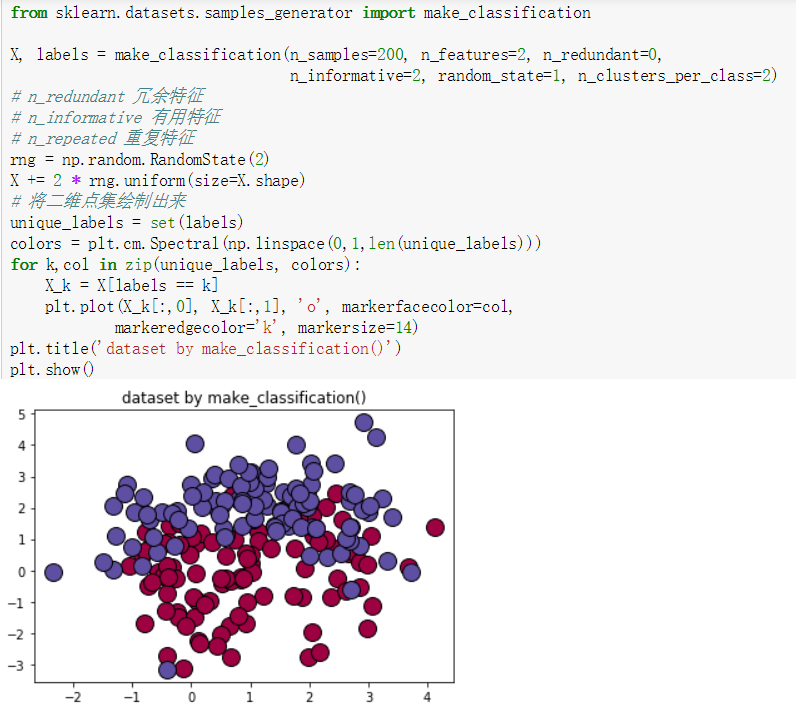
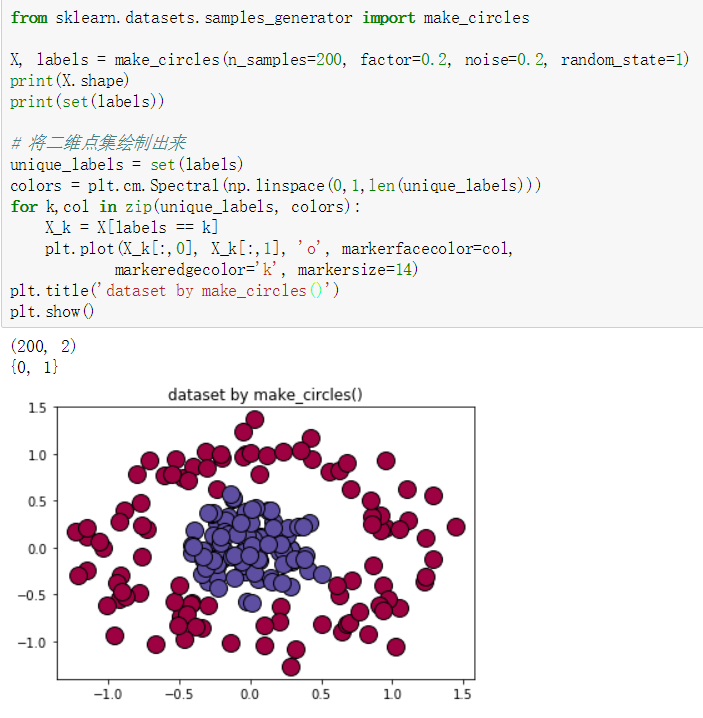
make_moons()

make_circles()
svmlight/libsvm格式的数据集
svmlight/libsvm的每一行样本的存放格式
<label> <feature-id>:<feature-value> <feature-id>:<feature-value>...
使用下面的方式导入该格式的数据集
X_train, y_train = sklearn.datasets.load_svmlight_file('train.txt')
还可以使用下面的方式将训练集和测试集一起导入,可以保证X_train和X_test有同样数目的特征
X_train, y_train, X_test, y_test = sklearn.datasets.load_svmlight_file(('train.txt', 'test.txt'))
SKLearn数据集API(二)的更多相关文章
- SKLearn数据集API(一)
注:本文是人工智能研究网的学习笔记 数据集一览 类型 获取方式 自带的小数据集 sklearn.datasets.load_ 在线下载的数据集 sklearn.datasets.fetch_ 计算机生 ...
- 【学习笔记】sklearn数据集与估计器
数据集划分 机器学习一般的数据集会划分为两个部分: 训练数据:用于训练,构建模型 测试数据:在模型检验时使用,用于评估模型是否有效 训练数据和测试数据常用的比例一般为:70%: 30%, 80%: 2 ...
- 机器学习笔记(四)--sklearn数据集
sklearn数据集 (一)机器学习的一般数据集会划分为两个部分 训练数据:用于训练,构建模型. 测试数据:在模型检验时使用,用于评估模型是否有效. 划分数据的API:sklearn.model_se ...
- sklearn——数据集调用及应用
忙了许久,总算是又想起这边还没写完呢. 那今天就写写sklearn库的一部分简单内容吧,包括数据集调用,聚类,轮廓系数等等. 自带数据集API 数据集函数 中文翻译 任务类型 数据规模 load_ ...
- Sklearn数据集与机器学习
sklearn数据集与机器学习组成 机器学习组成:模型.策略.优化 <统计机器学习>中指出:机器学习=模型+策略+算法.其实机器学习可以表示为:Learning= Representati ...
- sklearn数据集
数据集划分: 机器学习一般的数据集会划分为两个部分 训练数据: 用于训练,构建模型 测试数据: 在模型检验时使用,用于评估模型是否有效 sklearn数据集划分API: 代码示例文末! scikit- ...
- Civil 3D API二次开发学习指南
Civil 3D构建于AutoCAD 和 Map 3D之上,在学习Civil 3D API二次开发之前,您至少需要了解AutoCAD API的二次开发,你可以参考AutoCAD .NET API二次开 ...
- 用JSON-server模拟REST API(二) 动态数据
用JSON-server模拟REST API(二) 动态数据 上一篇演示了如何安装并运行 json server , 在这里将使用第三方库让模拟的数据更加丰满和实用. 目录: 使用动态数据 为什么选择 ...
- Express4.x API (二):Request (译)
写在前面 最近学习express想要系统的过一遍API,www.expressjs.com是express英文官网(进入www.epxressjs.com.cn发现也是只有前几句话是中文呀~~),所以 ...
随机推荐
- 【leetcode 简单】 第五十六题 快乐数
编写一个算法来判断一个数是不是“快乐数”. 一个“快乐数”定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是无限循环但始终变不到 1.如 ...
- Ping程序的实现
Ping程序的实现 在windows系统下进行cmd可以进行ping操作. ping命令是用来确定本地主机与网络中其他主机的网络通信情况,或者查看是否是为效IP. ping的工作原理:网络另一主机发送 ...
- 2018Java开发面经(持续更新)
不要给自己挖坑!!!不要给自己挖坑!!!不要给自己挖坑!!!如果面试官只是问你了解xxx吗,如果不是很了解,就直接说不知道,不要说知道,不然面试官深问再不知道就印象很不好! 处女面送给了头条(北京)日 ...
- oracle11g创建修改删除表
oracle11g创建修改删除表 我的数据库名字: ORCL 密码:123456 1.模式 2.创建表 3.表约束 4.修改表 5.删除表 1.模式 set oracle_sid=OR ...
- static, const 和 static const 变量的初始化问题
const 常量的在超出其作用域的时候会被释放,但是 static 静态变量在其作用域之外并没有释放,只是不能访问. static 修饰的是静态变量,静态函数.对于类来说,静态成员和静态函数是属于整个 ...
- 【2017-10-1】雅礼集训day1
今天的题是ysy的,ysy好呆萌啊. A: 就是把一个点的两个坐标看成差分一样的东西,以此作为区间端点,然后如果点有边->区间没有交. B: cf原题啊.....均摊分析,简单的那种. 线段树随 ...
- lucene-利用内存中索引和多线程提高索引效率
转载地址: http://hi.baidu.com/idoneing/item/bc1cb914521c40603e87ce4d 1.RAMDirectory和FSDirectory对比 RAMDir ...
- TCP包服务器接受程序
//功能:客户端发送TCP包,此程序接受到,将字母转换为大写,在发送到客户端#include <stdio.h>#include <sys/socket.h>#include ...
- 10 个优质的 Laravel 扩展推荐
这里有 10+ 个用来搭建 Laravel 应用的包 为何会创建这个包的列表?因为我是一个「比较懒」的开发者,在脸书上是多个 Laravel 小组的成员.平日遇到最多的问题就是开发是需要用那些包.我很 ...
- window服务器上搭建git服务,window server git!!!
先给大家看一个高大上的,这是我给我公司配置的,小伙伴们都说好! 阿里云的2012server 基于这篇大神的教程,我把服务端搭建好了. 传送门,当然我还是自己做个笔记的好. 1.下载java,并安装 ...