分布式调度任务-ElasticJob
一:问题的引出与复现
在一个风和日丽的工作日,公司运营发现系统的任务数据没有推送执行,整个流程因此停住了。我立马远程登陆服务器,查看日志,好家伙,系统在疯狂的打印相同的一段日志:c.d.d.j.i.e.LeaderElectionService [traceId=] - Elastic job: leader node is electing, waiting for 100 ms at server '192.168.0.6'
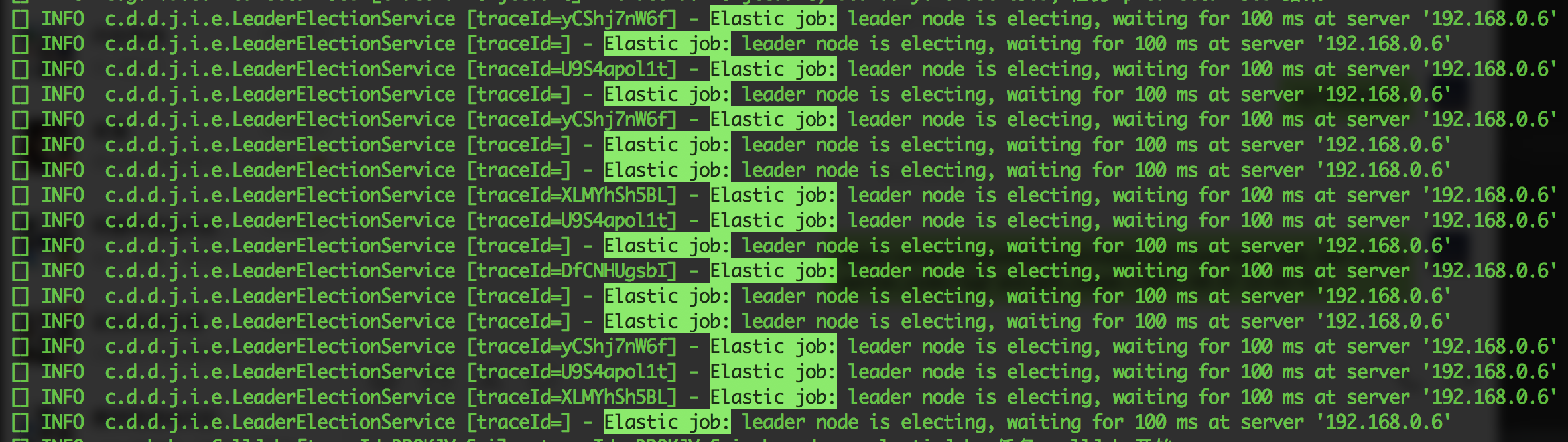
第一反应就是基建出问题了,无奈和运营商量,准备重启项目服务,重启后,问题立刻解决,业务也正常运行了。
有句话说得好,你觉得可能再次出现的问题,一定会再次出现。忘记了多少天后(开发初期,业务很紧张,这个问题没有时间及时去处理),又有别的定时任务也不执行了,出现的问题也是一模一样。
同一个问题在生产出现了两次,已经必须要去解决了,首先去网上搜索下,也有网友遇到过这种问题,但是下面的回复却是说:”Elastic job正在选举主节点,等它选完就正常了。“
先说下当时生产正在用的就是 com.dangdang.elastic-job-core,是当当网开源的一个分布式调度的组件,在上家公司三个机器节点做的集群用了很长时间也重来没有遇到这个问题,
当时就纳闷了,难道是有什么配置设置的不对,导致它无法正常选主吗?
然后花了点时间,自己搭了一个项目,准备去仔细分析debug下它的源码,在这儿就发现,每次远程debug的时候,一两分钟后,项目日志就会复现 c.d.d.j.i.e.LeaderElectionService [traceId=] - Elastic job: leader node is electing, waiting for 100 ms at server '192.168.0.6' 。
因此大胆猜测,因为debug导致Elastic job和注册中心心跳链接超时了,而生产环境的系统也可能因为网络抖动或者IO的压力,导致这个问题。
二:ElasticJob简单使用
2020年6月,经过Apache ShardingSphere社区投票,接纳ElasticJob为其子项目。目前ElasticJob的四个子项目已经正式迁入Apache仓库。
http://shardingsphere.apache.org/elasticjob/index_zh.html 最新的3.x版本在开源社区的帮助下,相比之前已经有了很大的优化,当然经过测试,也完美解决了选主的问题。
大致翻阅一下官方文档,下面就准备接入测试下。
引入maven依赖
<dependency>
<groupId>org.apache.shardingsphere.elasticjob</groupId>
<artifactId>elasticjob-lite-core</artifactId>
<version>${latest.release.version}</version>
</dependency>
# Spring 命名空间,可以与 Spring 容器配合使用
<dependency>
<groupId>org.apache.shardingsphere.elasticjob</groupId>
<artifactId>elasticjob-lite-spring-namespace</artifactId>
<version>3.0.0-beta</version>
</dependency>
# zk的版本要求3.6.0 以上
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.2</version>
</dependency>
elasticjob.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:elasticjob="http://shardingsphere.apache.org/schema/elasticjob"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://shardingsphere.apache.org/schema/elasticjob
http://shardingsphere.apache.org/schema/elasticjob/elasticjob.xsd
"> <elasticjob:zookeeper id="regCenter2" server-lists="${zkHost}" namespace="${elastic.job.namespace}"
base-sleep-time-milliseconds="${elastic.job.baseSleepTimeMilliseconds}"
max-sleep-time-milliseconds="${elastic.job.maxSleepTimeMilliseconds}" max-retries="${elastic.job.maxRetries}"/>
<elasticjob:job id="apacheTestJob"
job-ref="apacheTestJob"
registry-center-ref="regCenter2" sharding-total-count="${apacheTestJob.shardingTotalCount}"
cron="${apacheTestJob.cron}"
failover="${apacheTestJob.failover}" description="${apacheTestJob.description}"
disabled="${apacheTestJob.disabled}"
overwrite="${apacheTestJob.overwrite}"
job-executor-service-handler-type="SINGLE_THREAD"/> <bean id="apacheTestJob" class="com.yxy.nova.elastic.job.ApacheTestJob" /> </beans>
可配置属性:
| 属性名 | 是否必填 |
|---|---|
| id | 是 |
| class | 否 |
| job-ref | 否 |
| registry-center-ref | 是 |
| tracing-ref | 否 |
| cron | 是 |
| sharding-total-count | 是 |
| sharding-item-parameters | 否 |
| job-parameter | 否 |
| monitor-execution | 否 |
| failover | 否 |
| misfire | 否 |
| max-time-diff-seconds | 否 |
| reconcile-interval-minutes | 否 |
| job-sharding-strategy-type | 否 |
| job-executor-service-handler-type | 否 |
| job-error-handler-type | 否 |
| job-listener-types | 否 |
| description | 否 |
| props | 否 |
| disabled | 否 |
| overwrite | 否 |
1:cron 定时执行的表达式
2:sharding-total-count 总的分片数
3:job-sharding-strategy-type 分片策略
可以看它内置的三种策略,说明比较详细,默认的是 平均分片策略。
下面再说说如何自定义分片策略,ElasticJob加载分片策略使用的是JDK的spi (Service Provider Interface)加载的。
要使用SPI比较简单,只需要按照以下几个步骤操作即可:
- 在META-INF/services目录下创建一个以"接口全限定名"为命名的文件,内容为实现类的全限定名
- 接口实现类所在的jar包在classpath下
- 主程序通过java.util.ServiceLoader动态状态实现模块,它通过扫描META-INF/services目录下的配置文件找到实现类的全限定名,把类加载到JVM
- SPI的实现类必须带一个无参构造方法
首先自定义一个策略类MyJobShardingStrategy,实现 JobShardingStrategy
package com.nova.elastic.job; import org.apache.shardingsphere.elasticjob.infra.handler.sharding.JobInstance;
import org.apache.shardingsphere.elasticjob.infra.handler.sharding.JobShardingStrategy; import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map; public class MyJobShardingStrategy implements JobShardingStrategy { /**
* Sharding job.
*
* @param jobInstances all job instances which participate in sharding
* @param jobName job name
* @param shardingTotalCount sharding total count
* @return sharding result
*/
@Override
public Map<JobInstance, List<Integer>> sharding(List<JobInstance> jobInstances, String jobName, int shardingTotalCount) { Map<JobInstance, List<Integer>> result = new HashMap<>();
List<Integer> shardingItems = new ArrayList<>(shardingTotalCount + 1);
for (int i=0; i<shardingTotalCount; i++) {
shardingItems.add(i);
}
result.put(jobInstances.get(0), shardingItems);
return result;
} /**
* Get type.
*
* @return type
*/
@Override
public String getType() {
return "MY_TEST";
}
}
然后我们只需要在自己项目的resources下,建一个META-INF/services的文件夹,再创建以 a接口的全限定名(org.apache.shardingsphere.elasticjob.infra.handler.sharding.JobShardingStrategy),内容则为”com.nova.elastic.job.MyJobShardingStrategy“

这样ElasticJob的主程序通过java.util.ServiceLoader就可以把我们自定义的策略类加载好。
最后就可以在xml中,job-sharding-strategy-type="MY_TEST", 配置使用自定义的分片策略。
三:存在的问题
我模拟了 1 台作业服务器且分片总数为2,则分片结果为:1=[0,1],然后我再自己的调度任务中打印了 shardingContext,
2021-06-08 16:33:35.029 [] INFO c.y.n.e.j.ApacheTestJob [traceId=] - ShardingContext(jobName=apacheTestJob-no-repeat, taskId=apacheTestJob-no-repeat@-@0,1@-@READY@-@172.16.0.4@-@23146, shardingTotalCount=2, jobParameter=, shardingItem=0, shardingParameter=null)
2021-06-08 16:33:35.029 [] INFO c.y.n.e.j.ApacheTestJob [traceId=] - ShardingContext(jobName=apacheTestJob-no-repeat, taskId=apacheTestJob-no-repeat@-@0,1@-@READY@-@172.16.0.4@-@23146, shardingTotalCount=2, jobParameter=, shardingItem=1, shardingParameter=null)
可以看到,在这种配置条件下,ApacheTestJob 是同时执行两次,只有 shardingItem 有区别,那么这样就会存在一个问题,我job的代码逻辑就会执行两次,只不过每次的shardingItem不同而已。
如果业务逻辑需要查询数据库,那么这样就select了多次,在数据库有瓶颈的系统下,效率肯定低。
反之,如果在这个配置下,调度任务只被调度一次,但是 ShardingContext 可以保存一个 shardingItem的列表,这样就可以解决多次查询数据库的问题。
这也是用了这两种ElasticJob后,感受到的最大的区别。
不知道有没有正在使用 shardingsphere.elasticjob的小伙伴,你们的系统是如何使用的?有没有存在相同的疑惑?又是如何解决这个问题的?
分布式调度任务-ElasticJob的更多相关文章
- Elastic-Job 分布式调度平台
概述 referred:http://elasticjob.io/docs/elastic-job-lite/00-overview Elastic-Job是一个分布式调度解决方案,由两个相互独立的子 ...
- elastic-job分布式调度与zookeeper的简单应用
一.对分布式调度的理解 调度->定时任务,分布式调度->在分布式集群环境下定时任务这件事 Elastic-job(当当⽹开源的分布式调度框架) 1 定时任务的场景 定时任务形式:每隔⼀定时 ...
- ElasticJob 3.0.0:打造面向互联网生态和海量任务的分布式调度解决方案
ElasticJob 于 2020 年 5 月 28 日重启并成为 Apache ShardingSphere 子项目.新版本借鉴了 ShardingSphere 可拔插架构的设计理念,对内核进行了大 ...
- Elastic-Job-一个分布式调度解决方案
注:Elastic-Job是一个分布式调度解决方案,由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成.Elastic-Job-Lite定位为轻量级无中心化 ...
- 基于Quartz编写一个可复用的分布式调度任务管理WebUI组件
前提 创业小团队,无论选择任何方案,都优先考虑节省成本.关于分布式定时调度框架,成熟的候选方案有XXL-JOB.Easy Scheduler.Light Task Scheduler和Elastic ...
- 详解应对平台高并发的分布式调度框架TBSchedule
转载: 详解应对平台高并发的分布式调度框架TBSchedule
- spring boot / cloud (十五) 分布式调度中心进阶
spring boot / cloud (十五) 分布式调度中心进阶 在<spring boot / cloud (十) 使用quartz搭建调度中心>这篇文章中介绍了如何在spring ...
- Spring整合Quartz分布式调度
前言 为了保证应用的高可用和高并发性,一般都会部署多个节点:对于定时任务,如果每个节点都执行自己的定时任务,一方面耗费了系统资源,另一方面有些任务多次执行,可能引发应用逻辑问题,所以需要一个分布式的调 ...
- Spring整合Quartz分布式调度(山东数漫江湖)
前言 为了保证应用的高可用和高并发性,一般都会部署多个节点:对于定时任务,如果每个节点都执行自己的定时任务,一方面耗费了系统资源,另一方面有些任务多次执行,可能引发应用逻辑问题,所以需要一个分布式的调 ...
随机推荐
- CSS快速入门基础篇,让你快速上手(附带代码案例)
1.什么是CSS 学习思路 CSS是什么 怎么去用CSS(快速上手) CSS选择器(难点也是重点) 网页美化(文字,阴影,超链接,列表,渐变等) 盒子模型 浮动 定位 网页动画(特效效果) 项目格式: ...
- form表单验证提交
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 技术面试问题汇总第003篇:猎豹移动反病毒工程师part3
从现在开始,面试的问题渐渐深入.这次的三个问题,都是对PE格式的不断深入的提问.从最初的概念,到病毒对PE格式的利用,再到最后的壳的问题.这里需要说明的是,由于壳是一个比较复杂的概念,面试中也仅仅只能 ...
- hdu4642博弈(矩阵)
题意: 给一个01矩阵,每次可以选择1的格子,选择之后以他为左上角的矩阵全都取反,两个人轮班取,不能取的人输. 思路: 博弈的题目,结论是右下角是0就输,1就赢,原因可以这么 ...
- Windows核心编程 第十一章 线程池的使用
第11章 线程池的使用 第8章讲述了如何使用让线程保持用户方式的机制来实现线程同步的方法.用户方式的同步机制的出色之处在于它的同步速度很快.如果关心线程的运行速度,那么应该了解一下用户方式的同步机制是 ...
- Caddy-基于go的微型serve用来做反向代理和Gateway
1.简单配置 2.go实现,直接一个二进制包,没依赖. 3.默认全站https 常用 反向代理,封装多端口gateway 使用:启动直接执行二进制文件 caddy 就行 根据输出信息 直接https: ...
- 【python】Leetcode每日一题-前缀树(Trie)
[python]Leetcode每日一题-前缀树(Trie) [题目描述] Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的 ...
- 【python】Leetcode每日一题-逆波兰表达式求值
[python]Leetcode每日一题-逆波兰表达式求值 [题目描述] 根据 逆波兰表示法,求表达式的值. 有效的算符包括 +.-.*./ .每个运算对象可以是整数,也可以是另一个逆波兰表达式. 说 ...
- [LeetCode每日一题]1143. 最长公共子序列
[LeetCode每日一题]1143. 最长公共子序列 问题 给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度.如果不存在 公共子序列 ,返回 0 . 一个字符串 ...
- 【转】浅谈自动特征构造工具Featuretools
转自https://www.cnblogs.com/dogecheng/p/12659605.html 简介 特征工程在机器学习中具有重要意义,但是通过手动创造特征是一个缓慢且艰巨的过程.Python ...