正则表达式_爬取豆瓣电影排行Top250
前言:
利用简单的正则表达式,获取响应内容爬取数据。
Part1 正则表达式(Regular Expression)
1.1 简介
正则表达式,又称规则表达式,它是一种文本模式,就是通过事先定义好的一些特定字符及这些特定字符的组合成一个规则,对文本字符串进行匹配筛选过滤。
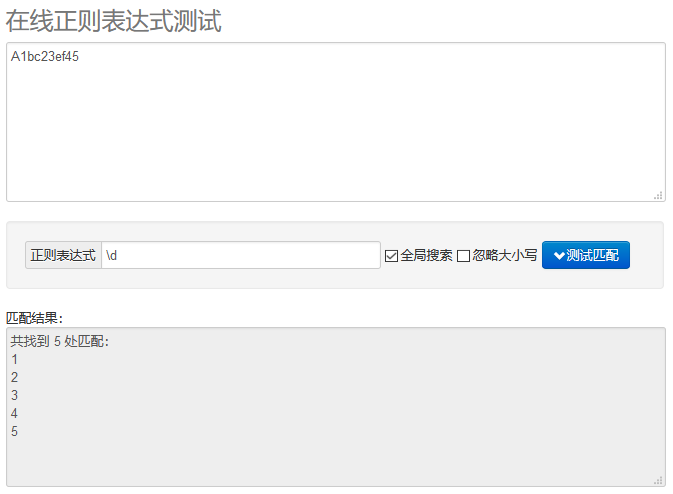
比如:“A1bc23ef45”这个字符串,我只想要里面的数字,通过正则表达式中的“\d”就可以快速的提取出来。
注:正则表达式在线测试工具:开源中国——实用工具——https://tool.oschina.net
1.2 常用字符
| 字符 | 描述 |
| [...] | 匹配 [...] 中的所有字符,如[eno],将匹配Python is fun中的e n o字母(若有) |
| [^...] | 匹配除了 [...] 中字符的所有字符,上面的例子取反 |
| \w | 匹配字母、数字、下划线。等价于 [A-Za-z0-9_] |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等 |
| \S | 匹配任何非空白字符 |
| ( ) | 标记一个子表达式的开始和结束位置。 |
| * | 匹配前面的子表达式零次或多次。 |
| . | 匹配除换行符 \n 之外的任何单字符。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符 |
| \ | 转义字符 |
| ^ | 匹配输入字符串的开始位置 |
| $ | 匹配输入字符串的结尾位置 |
| + | 匹配前面的子表达式一次或多次 |
| \d | 匹配数字 |
| \D | 匹配非数字 |
| {n} | n 是一个非负整数,匹配确定的 n 次 |
| {n,} | n 是一个非负整数,至少匹配n 次 |
| {n,m} | m 和 n 均为非负整数,其中n <= m,最少匹配 n 次且最多匹配 m 次 |
| .* | 贪婪匹配,匹配所有内容 |
| .*? | 非贪婪匹配,在所有内容中匹配一次 |
1.3 re模块中的常用方法
1.3.1 findall 查找字符串中所有内容,返回符合条件的数据,返回的数据是列表形式
1 lst = re.findall('o','Python is fun otoy')
2 print(lst)
3 # 查找字符串中所有的o,返回三个['o', 'o', 'o']
1.3.2 search 返回匹配到的第一个结果,如果没有返回None
lst = re.search('o','Python is fun otoy')
print(lst)
# <re.Match object; span=(4, 5), match='o'>
lst = re.search('a','Python is fun otoy')
print(lst)
# None
1.3.3 match 只能从字符串开头进行匹配
1 lst = re.match('o','Python is fun otoy')
2 print(lst)
3 # None
4
5 lst = re.match('P','Python is fun otoyPPPP')
6 print(lst)
7 # <re.Match object; span=(0, 1), match='P'>
1.3.4 finditer 和findall差不多,但是返回值是一个迭代器
1 lst = re.finditer('o','Python is fun otoy')
2 print(lst)
3 # <callable_iterator object at 0x000002820BCF6B20>
4
5 # 获取迭代器里的内容
6 for i in lst:
7 print(i)
8 # <re.Match object; span=(4, 5), match='o'>
9 # <re.Match object; span=(14, 15), match='o'>
10 # <re.Match object; span=(16, 17), match='o'>
11
12 # 只想要o
13 for i in lst:
14 print(i.group())# o# o# o
注:从finditer中获取内容,使用group方法,从search中获取也是使用这个方法
Part2 思路
2.1 目标
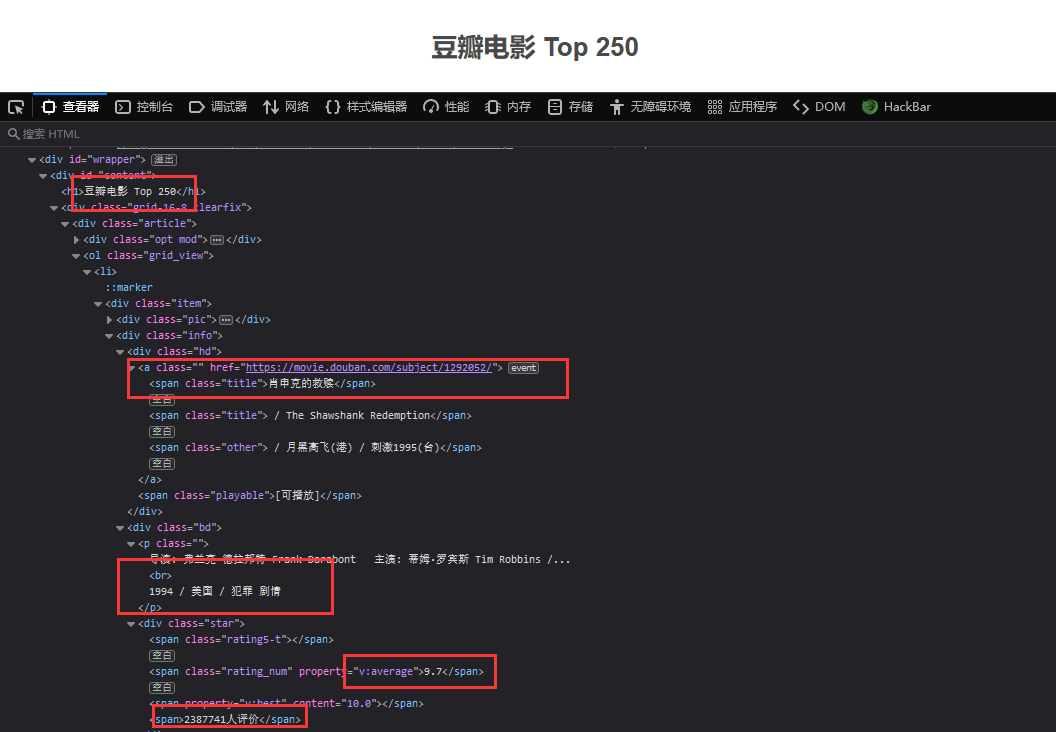
地址:https://movie.douban.com/top250
访问地址,F12打开开发者工具查看源代码,可以看到需要数据都在前端页面,开始分析需要的数据所在位置
2.2 步骤
发起请求——获取响应文本——正则表达式解析获取数据——数据存储
Part3 编写脚本
3.1 导入库
1 import requests
2 import re
3 import csv
re模块和csv为python自带,不需要安装,这里使用csv文本模式储存数据,是因为csv储存数据的特点:a,b,c 以逗号分割的格式,方便爬取数据后做进一步的处理分析。
3.2 撸代码
1 url = 'https://movie.douban.com/top250'
2 headers = {
3 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0)Gecko/20100101 Firefox/85.0"
4 }
5
6 resp = requests.get(url=url, headers=headers).text
7 # 获取到响应数据之后,转换成text文本数据,这样才能使用re来进行操作
3.3 分析
需要获取到电影的链接,电影名字,年份/地区/分类,评分,评价人数
3.4 提前定义一个正则表达式,方便后面调用
1 obj = re.compile(r'<li>.*?<div class="item">.*?<a href="(?P<link>.*?)">.*?<span class="title">(?P<name>.*?)</span>.*?<br>(?P<year>.*?)</p>.*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>.*?<span>(?P<comments>.*?)</span>', re.S)
注:使用 .*? 匹配过滤掉中间的所有的内容,使用(.*?)将匹配到内容提取,(?P<name>.*?)将匹配到的内容赋值给"name"
3.5 获取数据,写入保存
1 result = obj.finditer(resp)
2 fp = open('data.csv', 'w', encoding='utf-8')
3 wp = csv.writer(fp)
4
5 for it in result:
6 dic = it.groupdict()
7 dic['year'] = dic['year'].strip().replace(" ", "")
8 # 去除空格,替换字符
9 wp.writerow(dic.values())
10 fp.close()
注:从响应的文本里匹配到数据,使用groupdict()方法,将数据放到字典里,“year”匹配到的数据里含有空格和特殊字符,使用strip()方法去除空格,然后使用replace()方法把特殊字符替换成空
Part4 完整代码
4.1 说明
按照上面的代码,爬取到的是第一页的内容,只有25条数据,通过分析URL参数,改变参数内容发起请求即可获取全部的数据。
1 import requests
2 import re
3 import csv
4
5 fp = open('data.csv', 'w', encoding='utf-8')
6 wp = csv.writer(fp)
7
8 for i in range(0, 256, 25):
9 url = f'https://movie.douban.com/top250?start={i}&filter='
10 headers = {
11 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0"
12 }
13
14 resp = requests.get(url=url, headers=headers).text
15
16 # 数据解析
17 obj = re.compile(r'<li>.*?<div class="item">.*?<a href="(?P<link>.*?)">.*?'
18 r'<span class="title">(?P<name>.*?)</span>.*?<br>(?P<year>.*?)</p>.*?'
19 r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>.*?'
20 r'<span>(?P<comments>.*?)</span>', re.S)
21
22 result = obj.finditer(resp)
23
24 for it in result:
25 dic['year'] = dic['year'].strip().replace(" ", "")
26 # 去除空格,替换字符
27 wp.writerow(dic.values())
28
29 fp.close()
30 print('top250已下载完成')
4.2 运行结果

奇盛测试攻城狮 专业就是不断地学习,除去偶然性,你永远无法发现认知以外的BUG。——C_N_Candy 公众号
正则表达式_爬取豆瓣电影排行Top250的更多相关文章
- 爬取豆瓣电影排行top250
功能描述V1.0: 爬取豆瓣电影排行top250 功能分析: 使用的库 1.time 2.json 3.requests 4.BuautifulSoup 5.RequestException 上机实验 ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- 爬虫——正则表达式爬取豆瓣电影TOP前250的中英文名
正则表达式爬取豆瓣电影TOP前250的中英文名 1.首先要实现网页的数据的爬取.新建test.py文件 test.py 1 import requests 2 3 def get_Html_text( ...
- urllib+BeautifulSoup无登录模式爬取豆瓣电影Top250
对于简单的爬虫任务,尤其对于初学者,urllib+BeautifulSoup足以满足大部分的任务. 1.urllib是Python3自带的库,不需要安装,但是BeautifulSoup却是需要安装的. ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
随机推荐
- ln -s 新目录(最后一个目录新建images) 旧目录(删除最后的images目录)
sudo yum install libvirt virt-install qemu-kvm 默认安装会启用一个NAT模式的bridgevirbr0 启动激活libvirtd服务 systemctl ...
- 诸神之眼-Nmap 教程 2
|>>>简版先附上<<<| Nmap基础学习 语法 nmap + [空格] + <选项|多选项|协议> + [空格]+ <目标> 如 nma ...
- MegaCli是一款管理维护硬件RAID软件,可以通过它来了解当前raid卡的所有信息,包括 raid卡的型号,raid的阵列类型,raid 上各磁盘状态
MegaCli 监控raid状态 转载weixin_30344131 最后发布于2015-10-16 13:05:00 阅读数 简介 MegaCli是一款管理维护硬件RAID软件,可以通过它来了 ...
- 8.5-7 mkfs、dumpe2fs、resize2fs
8.5 mkfs:创建Linux文件系统 mkfs命令用于在指定的设备(或硬盘分区等)上创建格式化并创建文件系统,fdisk和parted等分区工具相当于建房的人,把房子(硬盘),分成几居室( ...
- Spring-Cloud之Feign原理剖析
Feign 主要是帮助我们方便进行rest api服务间的调用,其大体实现思路就我们通过标记注解在一个接口类上(注解上将包含要调用的接口信息),之后在调用时根据注解信息组装好请求信息,接下来基于rib ...
- Jmeter- 笔记7 - 服务器监控(ServerAgent配置)
文件:ServerAgent - 2.2.3.zip 放网盘了 在服务器的操作:只需要把这个文件上传到被监控服务器,然后解压,启动sh startagent.sh --udp-port 0 --tc ...
- Xilinx FPGA全局介绍
Xilinx FPGA全局介绍 现场可编程门阵列 (FPGA) 具有诸多特性,无论是单独使用,抑或采用多样化架构,皆可作为宝贵的计算资产:许多设计人员并不熟悉 FPGA,亦不清楚如何将这类器件整合到设 ...
- Paddle概述
Paddle概述 本文结合深度学习理论与实践,使用百度飞桨平台实现自然语言处理.计算机视觉及个性化推荐等领域的经典应用. 实践部分使用飞桨深度学习开源框架,适配最新的2.0版本,默认使用动态图编程范式 ...
- Python“九九乘法表”
用Python语言编程,使用双重循环语句输出"九九乘法表". for i in range(1, 10): # 控制行 for j in range(1, i+1): # 控制列 ...
- 解决:django.core.exceptions.ImproperlyConfigured: Requested setting INSTALLED_APPS, but settings are not 的方法
错误类型: 该错误是在在创建Django工程时出现遇到的错误 完整报错信息:(博文标题输入长度有限制) django.core.exceptions.ImproperlyConfigured: Req ...