canal从mysql拉取数据,并以protobuf的格式往kafka中写数据
大致思路:
canal去mysql拉取数据,放在canal所在的节点上,并且自身对外提供一个tcp服务,我们只要写一个连接该服务的客户端,去拉取数据并且指定往kafka写数据的格式就能达到以protobuf的格式往kafka中写数据的要求。
1. 配置canal(/bigdata/canal/conf/canal.properties),然后启动canal,这样就会开启一个tcp服务
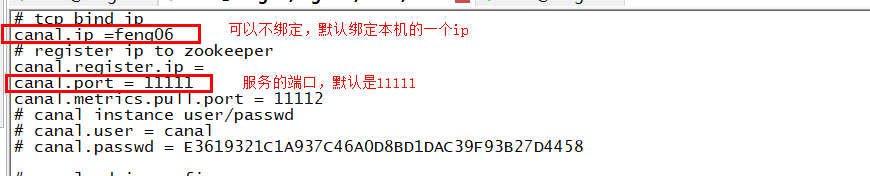
2. 写拉取数据的客户端代码
PbOfCanalToKafka


package cn._51doit.flink.canal;
import cn._51doit.proto.OrderDetailProto;
import com.alibaba.google.common.base.CaseFormat;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord; import java.net.InetSocketAddress;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties; public class PbOfCanalToKafka {
public static void main(String[] args) throws Exception {
CanalConnector canalConnector = CanalConnectors.newSingleConnector((new InetSocketAddress("192.168.57.12", 11111)), "example", "canal", "canal123");
// 1 配置参数
Properties props = new Properties();
//连接kafka节点
props.setProperty("bootstrap.servers", "feng05:9092,feng06:9092,feng07:9092");
props.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.setProperty("value.serializer", "org.apache.kafka.common.serialization.ByteArraySerializer");
KafkaProducer<String, byte[]> producer = new KafkaProducer<String, byte[]>(props); while (true) {
//建立连接
canalConnector.connect();
//订阅bigdata数据库下的所有表
canalConnector.subscribe("doit.orderdetail");
//每100毫秒拉取一次数据
Message message = canalConnector.get(10);
if (message.getEntries().size() > 0) {
// System.out.println(message);
List<CanalEntry.Entry> entries = message.getEntries();
for (CanalEntry.Entry entry : entries) {
//获取表名
String tableName = entry.getHeader().getTableName();
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList();
// System.out.println(rowDatasList);
//判断对数据库操作的类型,这里只采集INSERT/update的数据
OrderDetailProto.OrderDetail.Builder bean = OrderDetailProto.OrderDetail.newBuilder();
CanalEntry.EventType eventType = rowChange.getEventType();
if (eventType == CanalEntry.EventType.INSERT || eventType == CanalEntry.EventType.UPDATE) {
for (CanalEntry.RowData rowData : rowDatasList) {
List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();
System.out.println("======================打印afterColumnsList==============================");
System.out.println(afterColumnsList);
Map<String, String> kv = new HashMap<String, String>();
for (CanalEntry.Column column : afterColumnsList) {
String propertyName = CaseFormat.LOWER_UNDERSCORE.to(CaseFormat.LOWER_CAMEL, column.getName());
kv.put(propertyName, column.getValue());
}
// 设置属性
bean.setAmount(Integer.parseInt(kv.get("amount")));
bean.setMoney(Double.parseDouble(kv.get("money")));
bean.setOrderId(Long.parseLong(kv.get("orderId")));
bean.setCreateTime(kv.get("createTime"));
bean.setUpdateTime(kv.get("updateTime"));
bean.setId(Integer.parseInt(kv.get("id")));
bean.setSku(Long.parseLong(kv.get("sku")));
bean.setCategoryId(Integer.parseInt(kv.get("categoryId")));
//将数据转成JSON格式,然后用Kafka的Producer发送出去
byte[] bytes = bean.build().toByteArray();
ProducerRecord<String, byte[]> record = new ProducerRecord<>(tableName, bytes);
producer.send(record);
}
}
}
}
}
}
}
注意:数据被拉取到canal的格式不为json(若是不开启tcp服务,直接将数据发送给kafka,则数据在kafka中的格式为json),OrderDetailProto的生成见flink实时项目day07
Message
Message[id=1,entries=[header {
version: 1
logfileName: "mysql-bin.000002"
logfileOffset: 6669
serverId: 1
serverenCode: "UTF-8"
executeTime: 1594134782000
sourceType: MYSQL
schemaName: ""
tableName: ""
eventLength: 31
}
entryType: TRANSACTIONEND
storeValue: "\022\0042179"
, header {
version: 1
logfileName: "mysql-bin.000002"
logfileOffset: 6765
serverId: 1
serverenCode: "UTF-8"
executeTime: 1594147469000
sourceType: MYSQL
schemaName: ""
tableName: ""
eventLength: 80
}
entryType: TRANSACTIONBEGIN
storeValue: " A"
, header {
version: 1
logfileName: "mysql-bin.000002"
logfileOffset: 6911
serverId: 1
serverenCode: "UTF-8"
executeTime: 1594147469000
sourceType: MYSQL
schemaName: "doit"
tableName: "orderdetail"
eventLength: 82
eventType: INSERT
props {
key: "rowsCount"
value: "1"
}
}
entryType: ROWDATA
storeValue: "\b\177\020\001P\000b\332\002\022\'\b\000\020\373\377\377\377\377\377\377\377\377\001\032\002id \001(\0010\000B\00212R\nbigint(20)\0220\b\001\020\373\377\377\377\377\377\377\377\377\001\032\border_id \000(\0010\000B\00529002R\nbigint(20)\022#\b\002\020\004\032\vcategory_id \000(\0010\000B\0012R\aint(11)\022#\b\003\020\f\032\003sku \000(\0010\000B\00520001R\vvarchar(50)\022!\b\004\020\b\032\005money \000(\0010\000B\0062000.0R\006double\022\036\b\005\020\004\032\006amount \000(\0010\000B\0012R\aint(11)\0227\b\006\020]\032\vcreate_time \000(\0010\000B\0232020-07-01 20:19:08R\ttimestamp\0227\b\a\020]\032\vupdate_time \000(\0010\000B\0232020-07-02 20:19:13R\ttimestamp"
, header {
version: 1
logfileName: "mysql-bin.000002"
logfileOffset: 6993
serverId: 1
serverenCode: "UTF-8"
executeTime: 1594147469000
sourceType: MYSQL
schemaName: ""
tableName: ""
eventLength: 31
}
entryType: TRANSACTIONEND
storeValue: "\022\0042197"
],raw=false,rawEntries=[]]
在mysql表orderdetail表中添加了一行
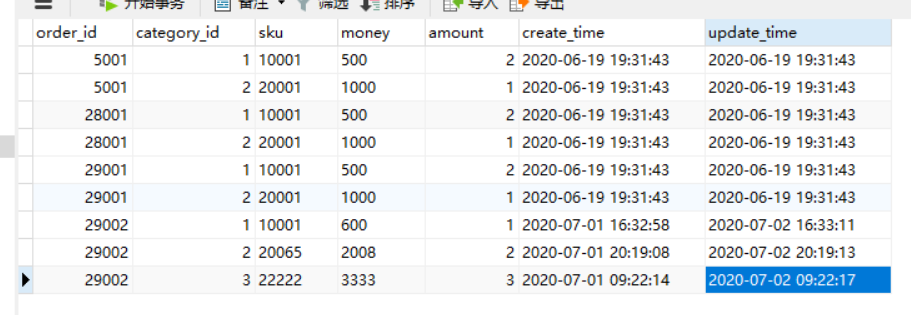
rowDatasList
[afterColumns {
index: 0
sqlType: -5
name: "id"
isKey: true
updated: true
isNull: false
value: "13"
mysqlType: "bigint(20)"
}
afterColumns {
index: 1
sqlType: -5
name: "order_id"
isKey: false
updated: true
isNull: false
value: "29002"
mysqlType: "bigint(20)"
}
afterColumns {
index: 2
sqlType: 4
name: "category_id"
isKey: false
updated: true
isNull: false
value: "3"
mysqlType: "int(11)"
}
afterColumns {
index: 3
sqlType: 12
name: "sku"
isKey: false
updated: true
isNull: false
value: "22333"
mysqlType: "varchar(50)"
}
afterColumns {
index: 4
sqlType: 8
name: "money"
isKey: false
updated: true
isNull: false
value: "1111.0"
mysqlType: "double"
}
afterColumns {
index: 5
sqlType: 4
name: "amount"
isKey: false
updated: true
isNull: false
value: "3"
mysqlType: "int(11)"
}
afterColumns {
index: 6
sqlType: 93
name: "create_time"
isKey: false
updated: true
isNull: false
value: "2020-07-01 22:02:50"
mysqlType: "timestamp"
}
afterColumns {
index: 7
sqlType: 93
name: "update_time"
isKey: false
updated: true
isNull: false
value: "2020-07-02 22:02:54"
mysqlType: "timestamp"
}
]
afterColumnsList
[index: 0
sqlType: -5
name: "id"
isKey: true
updated: false
isNull: false
value: "12"
mysqlType: "bigint(20)"
, index: 1
sqlType: -5
name: "order_id"
isKey: false
updated: false
isNull: false
value: "29002"
mysqlType: "bigint(20)"
, index: 2
sqlType: 4
name: "category_id"
isKey: false
updated: false
isNull: false
value: "2"
mysqlType: "int(11)"
, index: 3
sqlType: 12
name: "sku"
isKey: false
updated: true
isNull: false
value: "20011"
mysqlType: "varchar(50)"
, index: 4
sqlType: 8
name: "money"
isKey: false
updated: false
isNull: false
value: "2000.0"
mysqlType: "double"
, index: 5
sqlType: 4
name: "amount"
isKey: false
updated: false
isNull: false
value: "2"
mysqlType: "int(11)"
, index: 6
sqlType: 93
name: "create_time"
isKey: false
updated: false
isNull: false
value: "2020-07-01 20:19:08"
mysqlType: "timestamp"
, index: 7
sqlType: 93
name: "update_time"
isKey: false
updated: false
isNull: false
value: "2020-07-02 20:19:13"
mysqlType: "timestamp"
]
3. 若是想从kafka中读取protobuf格式的数据,则需要自定义序列化器,这里以flink读取盖格师的数据为例
具体见flink实时项目day07
canal从mysql拉取数据,并以protobuf的格式往kafka中写数据的更多相关文章
- flink04 -----1 kafkaSource 2. kafkaSource的偏移量的存储位置 3 将kafka中的数据写入redis中去 4 将kafka中的数据写入mysql中去
1. kafkaSource 见官方文档 2. kafkaSource的偏移量的存储位置 默认存在kafka的特殊topic中,但也可以设置参数让其不存在kafka的特殊topic中 3 将k ...
- Linux启动kettle及linux和windows中kettle往hdfs中写数据(3)
在xmanager中的xshell运行进入图形化界面 sh spoon.sh 新建一个job
- IDEA中Spark往Hbase中写数据
import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.io.ImmutableBytesWr ...
- Kafka消费者 从Kafka中读取数据并写入文件
Kafka消费者 从Kafka中读取数据 最近有需求要从kafak上消费读取实时数据,并将数据中的key输出到文件中,用于发布端的原始点进行比对,以此来确定是否传输过程中有遗漏数据. 不废话,直接上代 ...
- Flink 使用(一)——从kafka中读取数据写入到HBASE中
1.前言 本文是在<如何计算实时热门商品>[1]一文上做的扩展,仅在功能上验证了利用Flink消费Kafka数据,把处理后的数据写入到HBase的流程,其具体性能未做调优.此外,文中并未就 ...
- git拉取远程分支并创建本地分支和Git中从远程的分支获取最新的版本到本地
git拉取远程分支并创建本地分支 一.查看远程分支 使用如下Git命令查看所有远程分支: git branch -r 二.拉取远程分支并创建本地分支 方法一 使用如下命令: git checkout ...
- Kafka生产者-向Kafka中写入数据
(1)生产者概览 (1)不同的应用场景对消息有不同的需求,即是否允许消息丢失.重复.延迟以及吞吐量的要求.不同场景对Kafka生产者的API使用和配置会有直接的影响. 例子1:信用卡事务处理系统,不允 ...
- mapreduce 只使用Mapper往多个hbase表中写数据
只使用Mapper不使用reduce会大大减少mapreduce程序的运行时间. 有时候程序会往多张hbase表写数据. 所以有如题的需求. 下面给出的代码,不是可以运行的代码,只是展示driver中 ...
- 当From窗体中数据变化时,使用代码获取数据库中的数据然后加入combobox中并且从数据库中取得最后的结果
private void FormLug_Load(object sender, EventArgs e) { FieldListLug.Clear();//字段清除 DI = double.Pars ...
随机推荐
- 碰撞的蚂蚁 牛客网 程序员面试金典 C++ Java Python
碰撞的蚂蚁 牛客网 程序员面试金典 C++ Java Python 题目描述 在n个顶点的多边形上有n只蚂蚁,这些蚂蚁同时开始沿着多边形的边爬行,请求出这些蚂蚁相撞的概率.(这里的相撞是指存在任意两只 ...
- 【数据结构&算法】02-复杂度分析之执行效率和资源消耗
目录 前言 复杂度 分析方法 大 O 复杂度表示法 例子-评估累加和的各种算法执行效率 算法 1(for 循环): 算法 2(嵌套 for 循环): 大 O 表示 时间复杂度分析 关注执行最多的一段代 ...
- 变量命名网站 Codelf
程序员最头疼的事情除了头发以外就是给变量或函数命名,一开始学编程语言的时候还可以 abc.a1.x2 等方式命名,等到工作过程中开始真正的项目开发时,如果还是这样随意的命名,即使同事可以忍受你的 ab ...
- k8s入坑之路(10)kubernetes coredns详解
概述 作为服务发现机制的基本功能,在集群内需要能够通过服务名对服务进行访问,那么就需要一个集群范围内的DNS服务来完成从服务名到ClusterIP的解析. DNS服务在kubernetes中经历了三个 ...
- 【AI测试】人工智能 (AI) 测试--第二篇
测试用例 人工智能 (AI) 测试 或者说是 算法测试,主要做的有三件事. 收集测试数据 思考需要什么样的测试数据,测试数据的标注 跑测试数据 编写测试脚本批量运行 查看数据结果 统计正确和错误的个数 ...
- pyinstaller打包:AttributeError: module ‘win32ctypes.pywin32.win32api’ has no attribute ‘error’
pyinstaller打包:AttributeError: module 'win32ctypes.pywin32.win32api' has no attribute 'error' 是因为pyin ...
- 第2章-7 产生每位数字相同的n位数 (30分)
第2章-7 产生每位数字相同的n位数 (30分) 读入2个正整数A和B,1<=A<=9, 1<=B<=10,产生数字AA-A,一共B个A 输入格式: 在一行中输入A和B. 输出 ...
- BAT面试必问细节:关于Netty中的ByteBuf详解
在Netty中,还有另外一个比较常见的对象ByteBuf,它其实等同于Java Nio中的ByteBuffer,但是ByteBuf对Nio中的ByteBuffer的功能做了很作增强,下面我们来简单了解 ...
- vue3 学习笔记 (四)——vue3 setup() 高级用法
本篇文章干货较多,建议收藏! 从 vue2 升级到 vue3,vue3 是可以兼容 vue2 的,所以 vue3 可以采用 vue2 的选项式API.由于选项式API一个变量存在于多处,如果出现问题时 ...
- [atAGC055B]ABC Supremacy
将第$i$个字符在$A->C->B->A$这个环上操作$i$次,而此时的操作也即将$AAA,BBB$或$CCC$变为其中的另一个字符串 通过操作$XXXY->YYYY-> ...