SparkStreaming消费Kafka,手动维护Offset到Mysql
说明
当前处理只实现手动维护offset到mysql,只能保证数据不丢失,可能会重复
要想实现精准一次性,还需要将数据提交和offset提交维护在一个事务中
官网说明
Your own data store
For data stores that support transactions, saving offsets in the same transaction as the results can keep the two in sync, even in failure situations. If you’re careful about detecting repeated or skipped offset ranges, rolling back the transaction prevents duplicated or lost messages from affecting results. This gives the equivalent of exactly-once semantics. It is also possible to use this tactic even for outputs that result from aggregations, which are typically hard to make idempotent.
您自己的数据存储
对于支持事务的数据存储,即使在失败情况下,将偏移与结果保存在同一事务中也可以使两者保持同步。 如果您在检测重复或跳过的偏移量范围时很谨慎,则回滚事务可防止重复或丢失的消息影响结果。 这相当于一次语义。 即使是由于聚合而产生的输出(通常很难使等幂),也可以使用此策略。
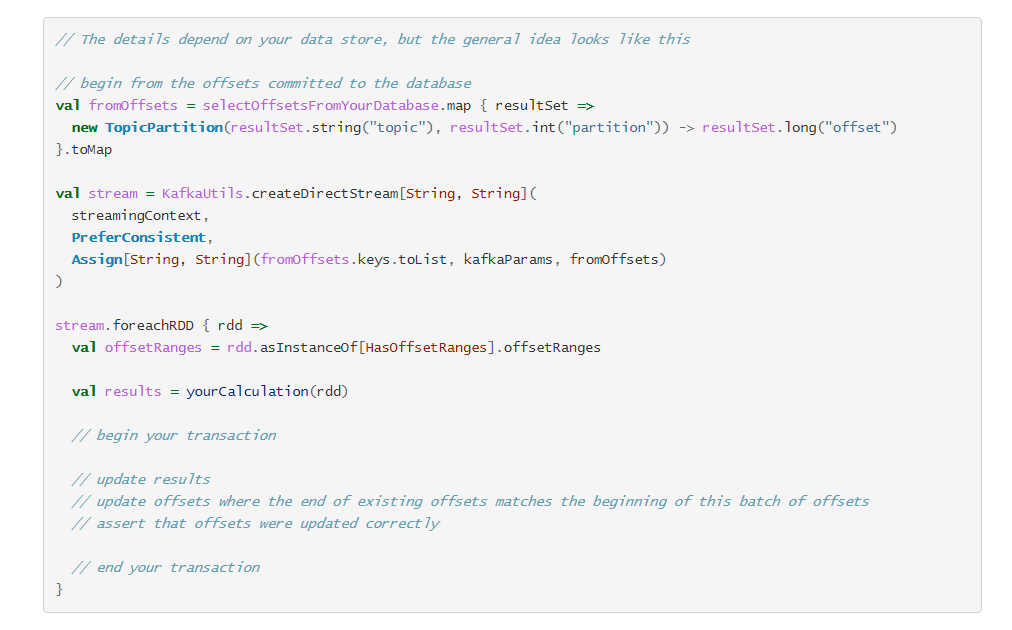
整体逻辑
offset建表语句
CREATE TABLE `offset_manager` (
`groupid` varchar(50) DEFAULT NULL,
`topic` varchar(50) DEFAULT NULL,
`partition` int(11) DEFAULT NULL,
`untiloffset` mediumtext,
UNIQUE KEY `offset_unique` (`groupid`,`topic`,`partition`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1

代码实现
在线教育:知识点实时统计
import java.sql.{Connection, ResultSet}
import com.atguigu.qzpoint.util.{DataSourceUtil, QueryCallback, SqlProxy}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.SparkConf
import scala.collection.mutable
/**
* @description: 知识点掌握实时统计
* @author: HaoWu
* @create: 2020年10月13日
*/
object QzPointStreaming_V2 {
val groupid = "test1"
def main(args: Array[String]): Unit = {
/**
* 初始化ssc
*/
val conf: SparkConf = new SparkConf()
.setAppName("test1")
.setMaster("local[*]")
.set("spark.streaming.kafka.maxRatePerPartition", "100")
.set("spark.streaming.backpressure.enabled", "true")
val ssc = new StreamingContext(conf, Seconds(3))
/**
* 读取mysql历史的offset
*/
val sqlProxy = new SqlProxy()
val client: Connection = DataSourceUtil.getConnection
val offsetMap = new mutable.HashMap[TopicPartition, Long]
try {
sqlProxy.executeQuery(client, "select * from `offset_manager` where groupid=?", Array(groupid), new QueryCallback {
override def process(rs: ResultSet): Unit = {
while (rs.next()) {
val model = new TopicPartition(rs.getString(2), rs.getInt(3))
val offset = rs.getLong(4)
offsetMap.put(model, offset)
}
rs.close()
}
})
} catch {
case e: Exception => e.printStackTrace()
} finally {
sqlProxy.shutdown(client)
}
/**
* 消费kafka主题,获取数据流
*/
val topics = Array("qz_log")
val kafkaMap: Map[String, Object] = Map[String, Object](
"bootstrap.servers" -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> groupid,
"auto.offset.reset" -> "earliest",
//手动维护offset,要设置为false
"enable.auto.commit" -> (false: Boolean)
)
val inStream: InputDStream[ConsumerRecord[String, String]] = if (offsetMap.isEmpty) {
//第一次启动程序消费
KafkaUtils.createDirectStream(
ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap))
} else {
//程序挂了,恢复程序
KafkaUtils.createDirectStream(
ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaMap, offsetMap))
}
//*************************************************处理逻辑 开始**********************************************//
/**
* 逻辑处理的套路:统计当前批 + DB中历史的数据 => 更新DB中的表数据
*/
inStream
.filter(
record => record.value().split("\t") == 6
)
//*************************************************处理逻辑 结束**********************************************//
/**
* 逻辑处理完后,更新 mysql中维护的offset
*/
inStream.foreachRDD(rdd => {
val sqlProxy = new SqlProxy()
val client = DataSourceUtil.getConnection
try {
val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
for (or <- offsetRanges) {
sqlProxy.executeUpdate(client, "replace into `offset_manager` (groupid,topic,`partition`,untilOffset) values(?,?,?,?)",
Array(groupid, or.topic, or.partition.toString, or.untilOffset))
}
/*for (i <- 0 until 100000) {
val model = new LearnModel(1, 1, 1, 1, 1, 1, "", 2, 1l, 1l, 1, 1)
map.put(UUID.randomUUID().toString, model)
}*/
} catch {
case e: Exception => e.printStackTrace()
} finally {
sqlProxy.shutdown(client)
}
})
//启动
ssc.start()
//阻塞
ssc.awaitTermination()
}
}
SparkStreaming消费Kafka,手动维护Offset到Mysql的更多相关文章
- spark streaming读取kakfka数据手动维护offset
在spark streaming读取kafka的数据中,spark streaming提供了两个接口读取kafka中的数据,分别是KafkaUtils.createDstream,KafkaUtils ...
- Spark Streaming消费Kafka Direct保存offset到Redis,实现数据零丢失和exactly once
一.概述 上次写这篇文章文章的时候,Spark还是1.x,kafka还是0.8x版本,转眼间spark到了2.x,kafka也到了2.x,存储offset的方式也发生了改变,笔者根据上篇文章和网上文章 ...
- SparkStreaming消费kafka中数据的方式
有两种:Direct直连方式.Receiver方式 1.Receiver方式: 使用kafka高层次的consumer API来实现,receiver从kafka中获取的数据都保存在spark exc ...
- kafka手动设置offset
项目中经常有需求不是消费kafka队列全部的数据,取区间数据 查询kafka最大的offset: ./kafka-run-class.sh kafka.tools.GetOffsetShell --b ...
- Spring-Kafka —— 实现批量消费和手动提交offset
spring-kafka的官方文档介绍,可以知道自1.1版本之后, @KafkaListener开始支持批量消费,只需要设置batchListener参数为true 把application.yml中 ...
- sparkstreaming消费kafka后bulk到es
不使用es-hadoop的saveToES,与scala版本冲突问题太多.不使用bulkprocessor,异步提交,es容易oom,速度反而不快.使用BulkRequestBuilder同步提交. ...
- 使用spark-streaming实时读取Kafka数据统计结果存入MySQL
在这篇文章里,我们模拟了一个场景,实时分析订单数据,统计实时收益. 场景模拟 我试图覆盖工程上最为常用的一个场景: 1)首先,向Kafka里实时的写入订单数据,JSON格式,包含订单ID-订单类型-订 ...
- 17-Flink消费Kafka写入Mysql
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- SparkStreaming与Kafka,SparkStreaming接收Kafka数据的两种方式
SparkStreaming接收Kafka数据的两种方式 SparkStreaming接收数据原理 一.SparkStreaming + Kafka Receiver模式 二.SparkStreami ...
随机推荐
- accept error: Too many open files
今天测试socket服务器同一时间处理多个客户端连接问题,第一次测试1000个的时候没问题,第二次测试1000个服务器accept的时候就报错了 accept error: Too many open ...
- binary-tree-postorder-traversal leetcode C++
Given a binary tree, return the postorder traversal of its nodes' values. For example: Given binary ...
- java核心技术 第3章 java基本程序设计结构
类名规范:以大写字母开头的名词 若由多个单词组成 每个单词的第一个字母应大写(驼峰命名法) 与.java文件名相同 运行程序:java ClassName(dos命令) 打印语句:System.ou ...
- Redis源码分析(intset)
源码版本:4.0.1 源码位置: intset.h:数据结构的定义 intset.c:创建.增删等操作实现 1. 整数集合简介 intset是Redis内存数据结构之一,和之前的 sds. skipl ...
- Git使用教程之初级入门命令行(二)
一.Git 操作流程图 1.git --help 查看帮助 Administrator@PC-xiaobing MINGW64 /d/Git (master) $ git --help usage: ...
- APP自动化环境搭建之appium工具介绍(二)
1.下载解压android-sdk-windows-appium //配置环境: ANDROID_HOME:D:\android-sdk-windows-appium path:...;%ANDROI ...
- css语法规范、选择器、字体、文本
css语法规范 使用 HTML 时需要遵从一定的规范,CSS 也是如此.要想熟练地使用 CSS 对网页进行修饰,首先需要了解CSS 样式规则. CSS 规则由两个主要的部分构成:选择器以及一条或多条声 ...
- git远程仓库、提交代码操作
初始化仓库 1.初始化 git init #或 git clone 远程仓库地址 git init 后续要添加远程仓库,git clone不需要再添加 2.连接仓库 git remote add 远程 ...
- XMLHttpRequest—>Promise
XMLHttpRequest.open() 初始化 HTTP 请求参数 语法open(method, url, async, username, password) method 参数是用于请求的 H ...
- python实现超大图像的二值化方法
一,分块处理超大图像的二值化问题 (1) 全局阈值处理 (2) 局部阈值 二,空白区域过滤 三,先缩放进行二值化,然后还原大小 np.mean() 返回数组元素的平均值 np.std() 返回数 ...