Generative Adversarial Nets (GAN)
这篇文章,引领了对抗学习的思想,更加可贵的是其中的理论证明,证明很少却直击要害.
目标
GAN,译名生成对抗网络,目的就是训练一个网络来拟合数据的分布,以前的方法,类似高斯核,Parzen窗等都可以用来估计(虽然不是很熟).
GAN有俩个网络,一个是G(z)生成网络,和D(x)判别网络, 其中\(z\)服从一个随机分布,而\(x\)是原始数据, \(z\)服从一个随机分布,是很重要的一点,假设\(\hat{x}=G(x)\), 则:
\]
其中\(I\)表示指示函数,这意味着,网络\(G\)也是一个分布,而我们所希望的,就是这个分布能够尽可能取拟合原始数据\(x\)的分布.
框架
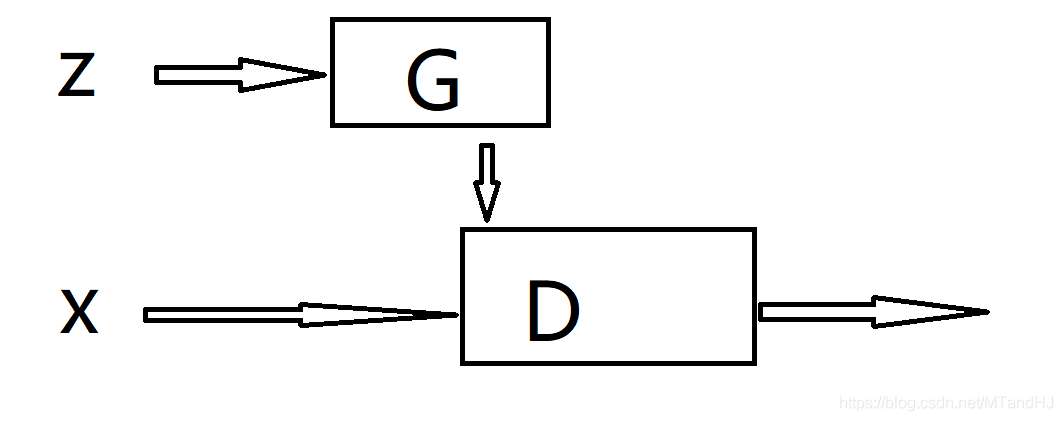
GAN需要训练上面的俩个网络,D的输出是一个0~1的标量,其含义是输入的x是否为真实数据(真实为1), 故其损失函数为(V(D,G)部分):
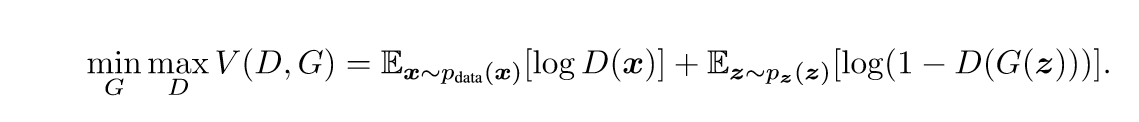
在实际操作中,固定网络G更新网络D,再固定网络D更新网络G,反复迭代:

理论
至于为什么可以这么做,作者给出了精炼的证明.


上面的证明唯一令人困惑的点在于\(p_z \rightarrow p_g\)的变化,我一开始觉得这个是利用换元,但是从别的博客中看到,似乎是用了测度论的导数的知识,最后用到了变分的知识.

其中:
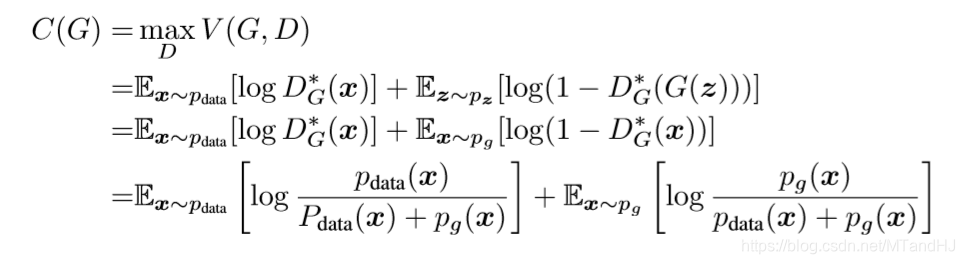
其证明思路是,当\(p_g=p_{data}\)的时候,\(C(G)=-\log 4\), 所以只需证明这个值为最小值,且仅再\(p_g=p_{data}\)的时候成立那么证明就结束了,为了证明这一点,作者凑了一个JSD, 而其正好满足我们要求(实际上只需KL散度即可Gibb不等式).
数值实验
在MNIST数据集上做实验(代码是仿别人的写的), 我们的目标自然是给一个z, G能够给出一些数字.
用不带卷积层的网络:

带卷积层的网络,不过不论\(z\)怎么变,结果都一样,感觉有点怪,但是实际上,如果\(G\)一直生成的都是比方说是1, 那也的确能够骗过\(D\), 这个问题算是什么呢?有悖啊...

代码
代码需要注意的一点是,用BCELoss, 但是更新G网络的时候,并不是传入fake_label, 而是real_label,因为G需要骗过D, 不知道该怎么说,应该明白的.
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
class Generator(nn.Module):
def __init__(self, input_size):
super(Generator, self).__init__()
self.dense = nn.Sequential(
nn.Linear(input_size, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 784)
)
def forward(self, x):
out = self.dense(x)
return out
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.dense = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
x = x.view(x.size(0), -1)
out = self.dense(x)
return out
class Train:
def __init__(self, trainset, batch_size, z_size=100, criterion=nn.BCELoss(), lr=1e-3):
self.generator = Generator(z_size)
self.discriminator = Discriminator()
self.opt1 = torch.optim.SGD(self.generator.parameters(), lr=lr, momentum=0.9)
self.opt2 = torch.optim.SGD(self.discriminator.parameters(), lr=lr, momentum=0.9)
self.trainset = trainset
self.batch_size = batch_size
self.real_label = torch.ones(batch_size)
self.fake_label = torch.zeros(batch_size)
self.criterion = criterion
self.z_size = z_size
def train(self, epoch_size, path):
running_loss1 = 0.0
running_loss2 = 0.0
for epoch in range(epoch_size):
for i, data in enumerate(self.trainset, 0):
try:
real_img, _ = data
out1 = self.discriminator(real_img)
real_loss = self.criterion(out1, self.real_label)
z = torch.randn(self.batch_size, self.z_size)
fake_img = self.generator(z)
out2 = self.discriminator(fake_img)
fake_loss = self.criterion(out2, self.fake_label)
loss = real_loss + fake_loss
self.opt2.zero_grad()
loss.backward()
self.opt2.step()
z = torch.randn(self.batch_size, self.z_size)
fake_img = self.generator(z)
out2 = self.discriminator(fake_img)
fake_loss = self.criterion(out2, self.real_label) #real_label!!!!
self.opt1.zero_grad()
fake_loss.backward()
self.opt1.step()
running_loss1 += fake_loss
running_loss2 += real_loss
if i % 10 == 9:
print("[epoch:{} loss1: {:.7f} loss2: {:.7f}]".format(
epoch,
running_loss1 / 10,
running_loss2 / 10
))
running_loss1 = 0.0
running_loss2 = 0.0
except ValueError as err:
print(err) #最后一批的数据可能不是batch_size
continue
torch.save(self.generator.state_dict(), path)
def loading(self, path):
self.generator.load_state_dict(torch.load(path))
self.generator.eval()
"""
加了点卷积
"""
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
class Generator(nn.Module):
def __init__(self, input_size):
super(Generator, self).__init__()
self.dense = nn.Sequential(
nn.Linear(input_size, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 784)
)
def forward(self, x):
out = self.dense(x)
return out
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 32, 5, 3, 2), # 1x28x28 --> 32x10x10
nn.ReLU(),
nn.MaxPool2d(2, 2), # 32 x 10 x 10 --> 32x5x5
nn.Conv2d(32, 64, 3, 1, 1), # 32x5x5-->32x5x5
nn.ReLU()
)
self.dense = nn.Sequential(
nn.Linear(1600, 512),
nn.ReLU(),
nn.Linear(512, 1),
nn.Sigmoid()
)
def forward(self, x):
x = x.view(x.size(0), 1, 28, 28)
x = self.conv(x)
x = x.view(x.size(0), -1)
out = self.dense(x)
return out
class Train:
def __init__(self, trainset, batch_size, z_size=100, criterion=nn.BCELoss(), lr=1e-3):
self.generator = Generator(z_size)
self.discriminator = Discriminator()
self.opt1 = torch.optim.SGD(self.generator.parameters(), lr=lr, momentum=0.9)
self.opt2 = torch.optim.SGD(self.discriminator.parameters(), lr=lr, momentum=0.9)
self.trainset = trainset
self.batch_size = batch_size
self.real_label = torch.ones(batch_size)
self.fake_label = torch.zeros(batch_size)
self.criterion = criterion
self.z_size = z_size
def train(self, epoch_size, path):
running_loss1 = 0.0
running_loss2 = 0.0
for epoch in range(epoch_size):
for i, data in enumerate(self.trainset, 0):
try:
real_img, _ = data
out1 = self.discriminator(real_img)
real_loss = self.criterion(out1, self.real_label)
z = torch.randn(self.batch_size, self.z_size)
fake_img = self.generator(z)
out2 = self.discriminator(fake_img)
fake_loss = self.criterion(out2, self.fake_label)
loss = real_loss + fake_loss
self.opt2.zero_grad()
loss.backward()
self.opt2.step()
z = torch.randn(self.batch_size, self.z_size)
fake_img = self.generator(z)
out2 = self.discriminator(fake_img)
fake_loss = self.criterion(out2, self.real_label) #real_label!!!!
self.opt1.zero_grad()
fake_loss.backward()
self.opt1.step()
running_loss1 += fake_loss
running_loss2 += real_loss
if i % 10 == 9:
print("[epoch:{} loss1: {:.7f} loss2: {:.7f}]".format(
epoch,
running_loss1 / 10,
running_loss2 / 10
))
running_loss1 = 0.0
running_loss2 = 0.0
except ValueError as err:
print(err) #最后一批的数据可能不是batch_size
continue
torch.save(self.generator.state_dict(), path)
def loading(self, path):
self.generator.load_state_dict(torch.load(path))
self.generator.eval()
Generative Adversarial Nets (GAN)的更多相关文章
- 一文读懂对抗生成学习(Generative Adversarial Nets)[GAN]
一文读懂对抗生成学习(Generative Adversarial Nets)[GAN] 0x00 推荐论文 https://arxiv.org/pdf/1406.2661.pdf 0x01什么是ga ...
- Generative Adversarial Nets(GAN Tensorflow)
Generative Adversarial Nets(简称GAN)是一种非常流行的神经网络. 它最初是由Ian Goodfellow等人在NIPS 2014论文中介绍的. 这篇论文引发了很多关于神经 ...
- Generative Adversarial Nets[Wasserstein GAN]
本文来自<Wasserstein GAN>,时间线为2017年1月,本文可以算得上是GAN发展的一个里程碑文献了,其解决了以往GAN训练困难,结果不稳定等问题. 1 引言 本文主要思考的是 ...
- Generative Adversarial Nets(原生GAN学习)
学习总结于国立台湾大学 :李宏毅老师 Author: Ian Goodfellow • Paper: https://arxiv.org/abs/1701.00160 • Video: https:/ ...
- GAN(Generative Adversarial Nets)的发展
GAN(Generative Adversarial Nets),产生式对抗网络 存在问题: 1.无法表示数据分布 2.速度慢 3.resolution太小,大了无语义信息 4.无reference ...
- (转)Deep Learning Research Review Week 1: Generative Adversarial Nets
Adit Deshpande CS Undergrad at UCLA ('19) Blog About Resume Deep Learning Research Review Week 1: Ge ...
- Generative Adversarial Nets[BEGAN]
本文来自<BEGAN: Boundary Equilibrium Generative Adversarial Networks>,时间线为2017年3月.是google的工作. 作者提出 ...
- Generative Adversarial Nets[content]
0. Introduction 基于纳什平衡,零和游戏,最大最小策略等角度来作为GAN的引言 1. GAN GAN开山之作 图1.1 GAN的判别器和生成器的结构图及loss 2. Condition ...
- Generative Adversarial Nets[CycleGAN]
本文来自<Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks>,时间线为2017 ...
随机推荐
- 转 Android中Activity的启动模式(LaunchMode)和使用场景
转载请注明出处:http://blog.csdn.net/sinat_14849739/article/details/78072401本文出自Shawpoo的专栏我的简书:简书 一.为什么需要启动模 ...
- SQL count和sum
count(1).count(*)与count(列名)的执行区别 count(1) and count(字段) 两者的主要区别是 (1) count(1) 会统计表中的所有的记录数,包含字段为null ...
- CSS3新增特性\HTML标签类型
RGBA:透明度 作用: 设置透明度(R G B A) opacity:不透明度 文字也会被设置不透明度 圆角 border-radius:圆角{左上角,右上角.. ...
- weak和拷贝
weak/拷贝 1. weak 只要没有strong指针指向对象,该对象就会被销毁 2. 拷贝 NSString和block用copy copy语法的作用 产生一个副本 修改了副本(源对象)并不会影响 ...
- 【Linux】【Services】【SaaS】Docker+kubernetes(6. 安装和配置ceph)
1. 简介 1.1. 这个在生产中没用上,生产上用的是nfs,不过为了显示咱会,也要写出来 1.2. 官方网站:http://ceph.com/ 1.3. 中文网站:http://docs.ceph. ...
- 【Python】【Module】hashlib
用于加密相关的操作,代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法 import hashlib # ######## ...
- Redis缓存穿透、缓存击穿以及缓存雪崩
作为一个内存数据库,redis也总是免不了有各种各样的问题,这篇文章主要是针对其中三个问题进行讲解:缓存穿透.缓存击穿和缓存雪崩.并给出一些解决方案.这三个问题是基本问题也是面试常问问题. 这篇文章我 ...
- VectorCAST - 通过确保测试的完整性控制产品质量
软件测试面临的问题有一句格言是这样说的,"如果没有事先做好准备,就意味着做好了 失败的准备."如果把这个隐喻应用在软件测试方面,就可以这样说"没有测试到,就意味着测试失败 ...
- Excel如何使用vlookup
一.vlookup的语法 VLOOKUP (lookup_value, table_array, col_index_num, [range_lookup]) ①Lookup_value为需要在数据表 ...
- 小迪安全 Web安全 基础入门 第六天 - 信息打点-Web架构篇&域名&语言&中间件&数据库&系统&源码获取
一 . Web架构 语言.常用的Web开发语言有PHP,Java,Python,JavaScript,.net等.具体可参考w3school的介绍. 中间件. (1)常见的Web服务器中间件:IIS. ...