(转)Deep Learning Research Review Week 1: Generative Adversarial Nets

Deep Learning Research Review Week 1: Generative Adversarial Nets
Starting this week, I’ll be doing a new series called Deep Learning Research Review. Every couple weeks or so, I’ll be summarizing and explaining research papers in specific subfields of deep learning. This week I’ll begin with Generative Adversarial Networks.
Introduction
According to Yann LeCun, “adversarial training is the coolest thing since sliced bread”. I’m inclined to believe so because I don’t think sliced bread ever created this much buzz and excitement within the deep learning community. In this post, we’ll be looking at 3 papers that built on the pioneering work of Ian Goodfellow in 2014.
Quick Summary of GANs
I briefly mentioned Ian Goodfellow’s Generative Adversarial Network paper in one of my prior blog posts, 9 Deep Learning Papers You Should Know About. The basic idea of these networks is that you have 2 models, a generative model and a discriminative model. The discriminative model has the task of determining whether a given image looks natural (an image from the dataset) or looks like it has been artificially created. The task of the generator is to create natural looking images that are similar to the original data distribution. This can be thought of as a zero-sum or minimax two player game. The analogy used in the paper is that the generative model is like “a team of counterfeiters, trying to produce and use fake currency” while the discriminative model is like “the police, trying to detect the counterfeit currency”. The generator is trying to fool the discriminator while the discriminator is trying to not get fooled by the generator. As the models train through alternating optimization, both methods are improved until a point where the “counterfeits are indistinguishable from the genuine articles”.
Laplacian Pyramid of Adversarial Networks
Introduction
So, one of the most important uses of adversarial networks is the ability to create natural looking images after training the generator for a sufficient amount of time. These are some samples of what the generator outputted in Goodfellow’s 2014 paper.

As you can see, the generator worked well with digits and faces, but it created very fuzzy and vague images when using the CIFAR-10 dataset.
In order to fix this problem, Emily Denton, Soumith Chintala, Arthur Szlam, and Rob Fergus published the paper titled “Deep Generative Image Models using Lapalacian Pyramid of Adversarial Networks”. The main contribution of the paper is a type of network architecture that produces high-quality generated images that are mistaken for real images almost 40% of the time when assessed by human evaluators.
Approach
Before getting into the paper, let’s think about the job of the generator in a GAN. It has to produce a large, complex, and natural image that is good enough to convince a trained discriminator. Not such an easy task in one shot. The way the authors combat this is by using multiple CNN models to sequentially generate images in increasing scales. As Emily Denton said in hertalk on LAPGANs,
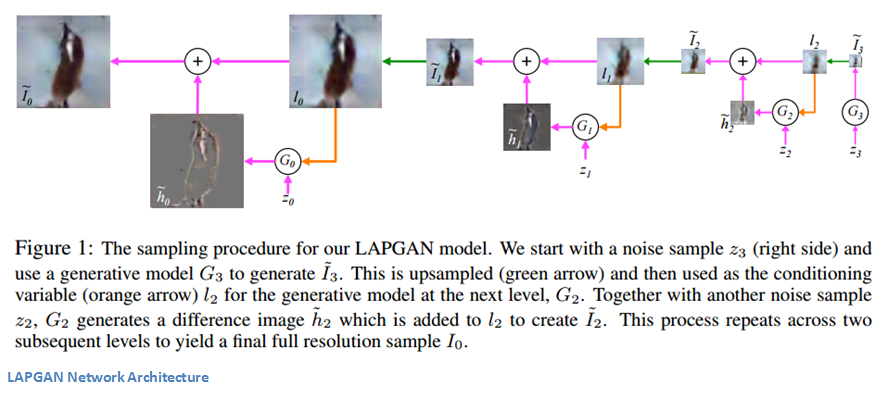
The approach of this paper is to build a Laplacian Pyramid of generative models. For those that aren’t familiar, a Laplacian pyramid is basically an image representation that consists of a series of filtered images at successively sparser densities (more info for those interested). The idea is that each level of this pyramid representation contains information about the image at a particular scale. It is a sort of decomposition of the original image.
Let’s review what the inputs and outputs are of a simple GAN. The generator takes in an input noise vector from a distribution and outputs an image. The discriminator takes in this image (or a real image from the training data) and outputs a scalar describing how “real” the image is. Now, let’s look at a conditional GAN (CGAN). Everything remains the same, except that both the discriminator and the generator receive another piece of information as an input. This information is likely in the form of some sort of class label or another image.
Network Architecture
The authors propose a set of convnet models and that each layer of the pyramid will have a convnet associated with it. The change is the traditional GAN structure is that instead of having just one generator CNN that creates the whole image, we have a series of CNNs that create the image sequentially by slowly increasing the resolution (aka going along the pyramid) and refining images in a coarse to fine fashion. Each level has its own CNN and is trained on two components. One is a low resolution image and the other is a noise vector (which was the only input in traditional GANs). This is where the idea of CGANs come into play as there are multiple inputs. The output will be a generated image that is then upsampled and used as input to the next level of the pyramid. This method is effective because the generators in each level are able to utilize information from different resolutions in order to create more finely grained outputs in the successive layers.

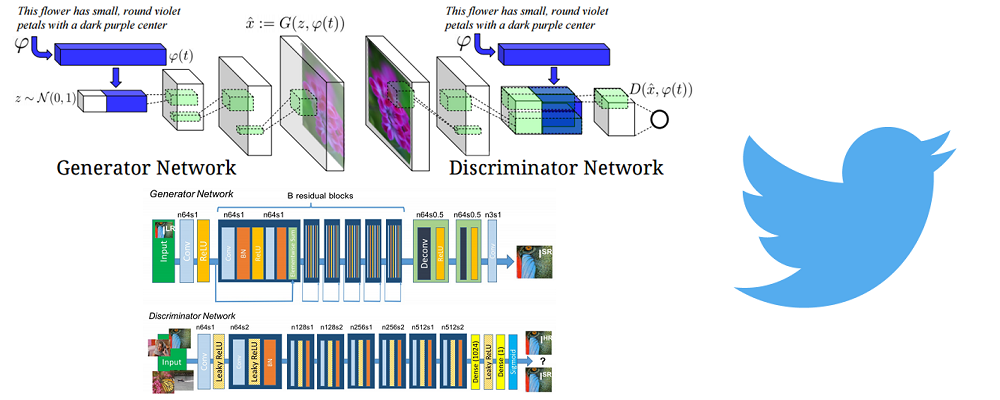
Generative Adversarial Text to Image Synthesis
Introduction
This paper was released just this past June and looks into the task of converting text descriptions into images. For example, the input to the network could be “a flower with pink petals” and the output is a generated image that contains those characteristics. So this task involves two main components. One is utilizing forms of natural language processing to understand the input description and the other is a generative network that is able to output an accurate and natural image representation. One note that the authors make is that the task of going from text to image is actually a lot harder than that of going from image to text (remember Karpathy’s paper). This is because of the incredible amount of pixel configurations and because we can’t really decompose the task into just predicting the next word (the way that image to text works).
Approach
The approach the authors take is training a GAN that is conditioned on text features created by a recurrent text encoder (won't go too much into this, but here's the paper for those interested). Both the generator and the discriminator use these features at points in their respective network architectures. This is what enables the GAN to make the correlation between the input description and the generated image.
Network Architecture
Let’s look at the generator first. We have our noise vector z along with a text encoding as the inputs to the network. Basically, this text encoding is a way of encapsulating information about the input description in a way that it can then be concatenated to the noise vector (see image below for a visualization). Deconv layers are then used to transform the input vector into the synthetic image.
The discriminator takes in an image, passes it through a series of conv layers (with BatchNorm and leaky ReLUs). When the spatial dimensions finally get to 4x4, the network performs a depth concatenation with that text encoding we were talking about earlier. After this, there are 2 more conv layers and the output is (as always) a score for the realness of the image.
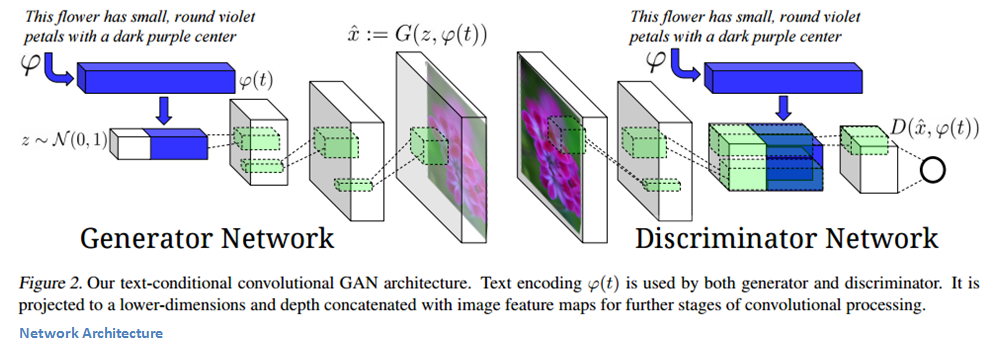
Training
One of the interesting things about this model is the way that it has to be trained. If you think closely about the task at hand, the generator has to get two jobs right. One is that it has to generate natural and plausible looking images. The other is that the images must correlate to the given text description. The discriminator, thus, must also keep these two things into account, making sure that “fake” or unnatural images are rejected as well as images that mismatch the text. In order to create these versatile models, the authors train with three types of data: {real image, right text}, {fake image, right text}, and {real image, wrong text}. With that last training data type, the discriminator must learn to reject mismatched images (even if they look very natural).

Super Resolution using GANs
Introduction
As a testament to the type of rapid innovation that takes place in this field, the team at Twitter Cortex released this paper only a couple weeks ago. The model being proposed in this paper is a super-resolution generative adversarial network, or SRGAN (Will we ever run out of these acronyms?). The main contribution is a brand new loss function (better than plain old MSE) that enables the network to recover realistic textures and fine grained details from images that have been heavilydownsampled.
Approach
Let’s first take a look at this new perceptual loss function that was introduced. This loss function can be divided into two parts, the adversarial loss and the content loss. From a high level, the adversarial loss encourages images that look natural (look like they’re from the distribution) and the content loss makes sure that the new resolution image has similar features to the original low res image.
Network Architecture
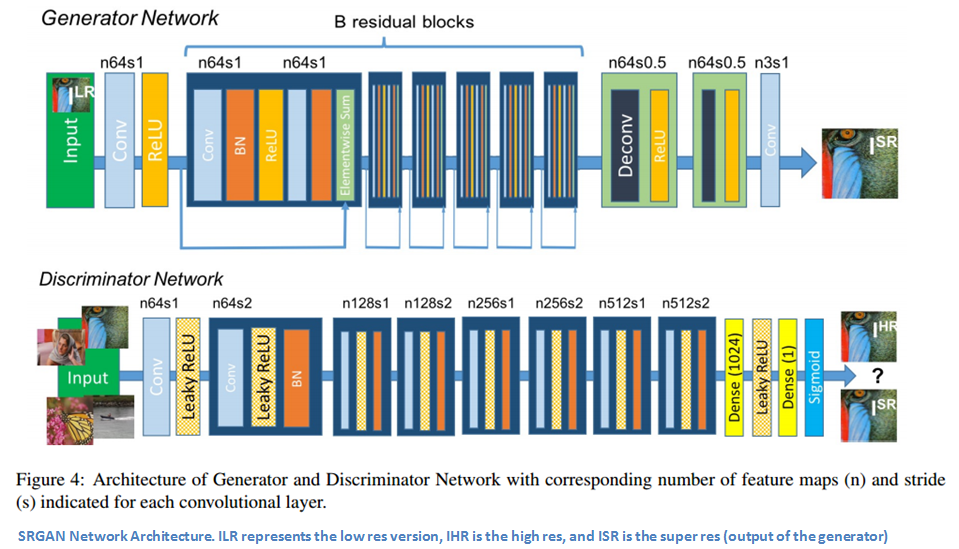
Okay, now let’s get into the specifics. Let’s start off with a high resolution version of a given image and then a lower resolution version. We want to train our generator so that given the low resolution image, we can have an output that’s as close to the high res version as possible. This output is called a super-resolved image. The discriminator will then be trained to distinguish between these images. Same old same old, right? The generator network architecture uses a set of B residual blocks that contain ReLUs and BatchNorm and conv layers. Once the low res image passes through those blocks, there are two deconv layers that enable the increase of the resolution. Then, looking at the discriminator, we have eight convolutional layers that lead into a sigmoid activation function which outputs the probabilities of whether the image is real (high res) or artificial (super res).
Loss Function
Now let’s look at that new loss function. It is actually a weighted sum of individual loss functions. The first is called a content loss. Basically, it is a Euclidean distance loss between the feature maps (in a pretrained VGG network) of the new reconstructed image (output of the network) and the actual high res training image. From what I understand, the main goal is to ensure that the content of the two images are similar by looking at their respective feature activations after feeding them into a trained convnet (Comment below if anyone has other ideas!). The other major loss function the authors defined is the adversarial loss. This one is similar to what you normally expect from GANs. It encourages outputs that are similar to the original data distribution through negative log likelihood. A regularization loss caps off the trio of functions. With this novel loss function, the generator makes sure to output larger res images that look natural and still retain a similar pixel space when compared to the low res version.

Quick general side note: GANs use a largely unsupervised training process (all you need to have is a dataset of real images, no labels or anything). This means that we can take advantage of a lot of the unstructured image data that is available today. After training, we can use the output or intermediate layers as feature extractors that can be used for other classifiers, which now won’t need as much training data to achieve good accuracy.
Paper that I couldn’t get to, but still insanely cool: DCGANs. The authors didn’t do anything crazy. They just trained a really really large convnet, but the trick is that they had the right hyperparameters to really make the training work (aka BatchNorm, Adam, Leaky ReLUs).
GANs that could change the fashion industry: https://www.youtube.com/watch?v=9c4z6YsBGQ0
Dueces.
(转)Deep Learning Research Review Week 1: Generative Adversarial Nets的更多相关文章
- (转) Deep Learning Research Review Week 2: Reinforcement Learning
Deep Learning Research Review Week 2: Reinforcement Learning 转载自: https://adeshpande3.github.io/ad ...
- Conditional Generative Adversarial Nets
目录 引 主要内容 代码 Mirza M, Osindero S. Conditional Generative Adversarial Nets.[J]. arXiv: Learning, 2014 ...
- Why are very few schools involved in deep learning research? Why are they still hooked on to Bayesian methods?
Why are very few schools involved in deep learning research? Why are they still hooked on to Bayesia ...
- 深度学习研究组Deep Learning Research Groups
Deep Learning Research Groups Some labs and research groups that are actively working on deep learni ...
- Generative Adversarial Nets[CycleGAN]
本文来自<Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks>,时间线为2017 ...
- Generative Adversarial Nets[CAAE]
本文来自<Age Progression/Regression by Conditional Adversarial Autoencoder>,时间线为2017年2月. 该文很有意思,是如 ...
- Generative Adversarial Nets[Wasserstein GAN]
本文来自<Wasserstein GAN>,时间线为2017年1月,本文可以算得上是GAN发展的一个里程碑文献了,其解决了以往GAN训练困难,结果不稳定等问题. 1 引言 本文主要思考的是 ...
- 论文笔记之:Generative Adversarial Nets
Generative Adversarial Nets NIPS 2014 摘要:本文通过对抗过程,提出了一种新的框架来预测产生式模型,我们同时训练两个模型:一个产生式模型 G,该模型可以抓住数据分 ...
- Generative Adversarial Nets[BEGAN]
本文来自<BEGAN: Boundary Equilibrium Generative Adversarial Networks>,时间线为2017年3月.是google的工作. 作者提出 ...
随机推荐
- [转载]Eclipse提示No java virtual machine
第一次运行Eclipse,经常会提示下面的问题:... No java virtual machine was found after searching the follwing location ...
- 浏览器html页面乱码问题分析
直接访问某html文件,浏览器显示编码是正常的,页面通过<meta charset="UTF-8">指定了编码方式,该文件存储编码也是utf8. 通过配置的org.sp ...
- Ubuntu 16.04 更新源
1/ 在修改source.list前,最好先备份一份 执行备份命令 sudo cp /etc/apt/sources.list /etc/apt/sources.list.old 2/ 执行命令打开s ...
- 工作中使用的html5和css3 新特性
1.placeholder <input type="text" placeholder="请输入手机号码" class="phone" ...
- Spring 事务管理 01 ——
目录: 参考: 1.Spring 事务管理高级应用难点剖析: 第 1 部分
- [转]Jenkins Xcode打包ipa
本地打包. 如果Mac 上没有安装brew.先安装:ruby -e "$(curl -fsSL https://raw.github.com/Homebrew/homebrew/go/ins ...
- mac os 中类似于Linux的yum工具,或ubuntu的apt-get工具Homebrew
Linux下的yum用着真省心! mac下的相类似的软件是Homebrew 使用前需要先安装它, ruby -e "$(curl -fsSL https://raw.githubuserco ...
- WCF初探-1:认识WCF
1.WCF是什么? WindowsCommunication Foundation(WCF)是由微软发展的一组数据通信的应用程序开发接口,它是.NET框架的一部分,由.NET Framework 3. ...
- Citrix 虚拟化笔记
利用win7 x64/Vmware workstation 10练习Citrix虚拟化 [安装Xenserver 6.2] 1)硬盘空间不足:要求最小8G 2)不支持硬件虚拟化:找到建立的XENSER ...
- 基础php链接SQL数据库
要连接到你的数据库必须添加以下几条数据: $conn = @mysql_connect("localhost","root","root") ...