Chapter 15 Outcome Regression and Propensity Scores
这一章讲一种新的方法: propensity scores.
15.1 Outcome regression
在满足条件可交换性下,
\]
之前的模型都是对等式左端进行建模, 倘若我们对等式右端进行建模呢?
\]
15.2 Propensity scores
在IP weighting 和 g-estimation的使用过程中, 我们需要估计条件概率\(\mathrm{Pr}[A=1|L]\), 记为\(\pi (L)\).
\(\pi (L)\) 就是所谓的propensity scores, 其反应了特定\(L\)的一种倾向.
首先我们要证明,
\]
不妨假设\(\pi(L) = s \Leftrightarrow L \in \{l_i\}\), 则
\mathrm{Pr}[Y^a|\pi(L)=s]
&= \mathrm{Pr} [Y^a|L \in \{l_i\}] \\
&= \frac{\sum_i\mathrm{Pr}[Y^a,L=l_i]}{\sum_i \mathrm{Pr} [L=l_i]}\\
&= \frac{\sum_i\mathrm{Pr}[Y|A=a, L=l_i]\mathrm{Pr}[L=l_i]}{\sum_i \mathrm{Pr} [L=l_i]}\\
&= \frac{\mathrm{Pr}[A=a|L=l] \cdot \sum_i\mathrm{Pr}[Y|A=a, L=l_i]\mathrm{Pr}[L=l_i]}{\mathrm{Pr}[A=a|L=l]\sum_i \mathrm{Pr} [L=l_i]}\\
&= \frac{\cdot \sum_i\mathrm{Pr}[Y|A=a, L=l_i]\mathrm{Pr}[A=a, L=l_i]}{\sum_i \mathrm{Pr} [A=a, L=l_i]}\\
&= \frac{\cdot \sum_i\mathrm{Pr}[Y, A=a, L=l_i]}{\sum_i \mathrm{Pr} [A=a, L=l_i]}\\
&= \frac{\cdot \mathrm{Pr}[Y, A=a, \pi(L)=s]}{\mathrm{Pr} [A=a, \pi(L)]}\\
&= \mathrm{Pr} [Y|A=a, \pi(L)=s].
\end{array}
\]
注意: \(\pi(l_i) = \pi(l_j) = \pi(l) = s\).
注意到, 上面有很重要的一步, 我们上下同时乘以\(\mathrm{Pr}[A=a|L=l]\), 实际上只有当\(A \in \{0, 1\}\)的时候才能成立, 因为二元, 加之\(\pi(L)=s\), 所以
\]
也就是说当\(A\)不是二元的时候, 上面的推导就是错误的了.
怪不得书上说, propensity scores这个方法是很难推广的非二元treatments的情况的.
15.3 Propensity stratification and standardization
此时, 我们可以把\(\pi(L)\)看成一个新的中间变量\(L\)(confounder?), 如下图:
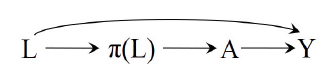
要知道, 原来的\(L\)可能是一个高维向量, 现在压缩为一维, 这意味着我们的可以将
\]
假设地更加精简.
估计或许更加牢靠(直接无参数模型?).
但是需要指出是, 不同个体的\(\pi(L)\)往往都是不同的, 这就导致我们想要估计
\]
几乎是不可能的.
一种比较好的做法是, 分成一段段区间, 考虑
\]
比如书上推荐的10分位.
当然这种做法会在一定程度上破化条件可交换性, 但是可以认为如果区间取得比较合适, 结果应该是比较合理的.
另外需要指出的, 我们往往会陷入一个误区, 觉得\(\pi(L)\), 即条件概率\(\mathrm{Pr}[A=1|L]\)的估计越准确越好, 实际上不是.
我们需要保证的仅仅是满足条件可交换性, 实际上准确度无关紧要.
有些时候过分追求准确度会适得其反, 因为这时我们往往会引入很多的变量, 导致我们的条件可交换性被大大破坏了.
所以不要仅仅当成是回归问题来看.
15.4 Propensity matching
看就是就是matching的翻版, 不过我matching也没搞懂哦.
15.5 Propensity models, structural models, predictive models
就主要是15.3里讲过的.
Fine Point
Nuisance parameters
Effect modification and the propensity score
Technical Point
Balancing scores and prognostic scores
Chapter 15 Outcome Regression and Propensity Scores的更多相关文章
- 零元学Expression Blend 4 - Chapter 15 用实例了解互动控制项「Button」I
原文:零元学Expression Blend 4 - Chapter 15 用实例了解互动控制项「Button」I 本章将教大家如何更改Button的预设Template,以及如何在Button内设置 ...
- Propensity Scores
目录 基本的概念 重要的结果 应用 Propensity Score Matching Stratification on the Propensity Score Inverse Probabili ...
- Thinking in Java from Chapter 15
From Thinking in Java 4th Edition. 泛型实现了:参数化类型的概念,使代码可以应用于多种类型.“泛型”这个术语的意思是:“适用于许多许多的类型”. 如果你了解其他语言( ...
- Think Python - Chapter 15 - Classes and objects
15.1 User-defined typesWe have used many of Python’s built-in types; now we are going to define a ne ...
- 《C++ Primer》 chapter 15 TextQuery
<C++ Primer>中第15章为了讲解面向对象编程,举了一个例子:设计一个小程序,能够处理查询给定word在文件中所在行的任务,并且能够处理“非”查询,“或”查询,“与”查询.例如执行 ...
- 【C++ Primer 5th】Chapter 15
摘要: 1. 面向对象程序设计的核心思想是数据抽象.继承和动态绑定.数据抽象将类的接口和实现分离:继承定义相似的类型并对齐相似关系建模:动态绑定,在一定程度上忽略相似类型的区别,而以统一的方式使用它们 ...
- 《算法导论》— Chapter 15 动态规划
序 算法导论一书的第四部分-高级设计和分析技术从本章开始讨论,主要分析高效算法的三种重要技术:动态规划.贪心算法以及平摊分析三种. 首先,本章讨论动态规划,它是通过组合子问题的解而解决整个问题的,通常 ...
- MySQL Crash Course #07# Chapter 15. 关系数据库. INNER JOIN. VS. nested subquery
索引 理解相关表. foreign key JOIN 与保持参照完整性 关于JOIN 的一些建议,子查询 VS. 联表查询 我发现MySQL 的官方文档里是有教程的. SQL Tutorial - W ...
- Chapter 6 — Improving ASP.NET Performance
https://msdn.microsoft.com/en-us/library/ff647787.aspx Retired Content This content is outdated and ...
随机推荐
- day05文件编辑命令
day05文件编辑命令 mv命令:移动文件 mv命令:mv命令用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中. 格式:mv [原来的文件路径] [现在的文件路径] mv命令后面既可以跟 ...
- Vue相关,diff算法。
1. 当数据发生变化时,vue是怎么更新节点的? 要知道渲染真实DOM的开销是很大的,比如有时候我们修改了某个数据,如果直接渲染到真实dom上会引起整个dom树的重绘和重排,有没有可能我们只更新我们修 ...
- IntentFilter,PendingIntent
1.当Intent在组件间传递时,组件如果想告知Android系统自己能够响应那些Intent,那么就需要用到IntentFilter对象. IntentFilter对象负责过滤掉组件无法响应和处理的 ...
- 访问网页全过程,用wireshark抓包分析
用wireshark抓包查看访问网站过程 打开wireshark,打开一个无痕浏览器,输入网址,到网页呈现这一过程,网络数据包传递的消息都会被放在wireshark里.针对这些包,我们可以逐一分析,摸 ...
- matplotlib画散点图和柱状图,等高线图,image图
一:散点图: scatter函数原型 其中散点的形状参数marker如下: 其中颜色参数c如下: n = 1024 # 均值是0, 方差是1, 取1024个数 x = np.rando ...
- linux系统下命令的学习
本博客是本人工作时做的笔记 ps aux |grep ^profile |grep A190200024 ^ 表示行首匹配 linux查看文件大小: 具体可查看:https://www.cnblogs ...
- 【科研工具】流程图软件Visio Pro 2019 详细安装破解教程
[更新区] 安装教程我下周会在bilibili上传视频,这周事情太多暂时先不弄. [注意] 安装Visio需要和自己的Word版本一样,这里因为我的Word是学校的正版2019(所以学校为什么正版没买 ...
- Libev——ev_timer 相对时间定时器
Libev中的超时监视器ev_timer,是简单的相对时间定时器,它会在给定的时间点触发超时事件,还可以在固定的时间间隔之后再次触发超时事件. 1.超时监视器ev_timer结构 typedef st ...
- numpy基础教程--对数组进行水平拼接和竖直拼接
在处理数组的时候经常要用到拼接,numpy中有两个非常实用的函数,可以快捷对数组进行拼接 1.hstack(tup)函数可以接收维度相同的数组,进行水平拼接. 2.vstack(tup)用来竖直拼接 ...
- [BUUCTF]PWN——ciscn_2019_es_7[详解]
ciscn_2019_es_7 附件 步骤: 例行检查,64位程序,开启了nx保护 本地试运行一下看看大概的情况 64位ida载入,关键函数很简单,两个系统调用,buf存在溢出 看到系统调用和溢出,想 ...