如何设计一个高性能 Elasticsearch mapping
前言
在关系型数据库设计当中,表的设计尤其重要,然而关系型数据库更关注的表与表之间的关系,以及表的划分是否合理,而 Elasticsearch 中却更加关注字段类型的设计,一个好的字段类型设计可以更好的利用 Elasticsearch 的搜索分析特性。
mapping
如果说我们想要用好 Elasticsearch,那么就必须要先了解 mapping 什么是 mapping。一句话:mapping是定义如何存储和索引文档及其包含的字段的过程。
mapping 能做什么
前面我们提到,在 Elasticsearch 中,mapping 类似于传统关系型数据库的表结构定义,主要做以下几件事:
- 定义字段名称和字段类型。
- 定义倒排索引相关的配置,比如是否被索引,是否可以被分词等。
mapping 可以分为两种:Dynamic mapping 和 Explicit mapping。
Dynamic mapping
Dynamic mapping 即:动态映射。动态映射顾名思义就是 mapping 会被动态创建,也就是说我们不需要定义 mapping 就可以往一个索引插入数据,插入索引数据之后,Elasticsearch 会根据插入的数据自动推测数据类型,进而动创建 mapping。
比如下面就是往一个不存在的索引 index_001 插入一条数据:
PUT index_001/_doc/1
{
"name":"lonely wolf",
"age": 18,
"create_date":"2021-05-19 20:45:11",
"update_date":"2021-05-23"
}
插入数据之后,执行 GET index_001 来查询一下索引信息:
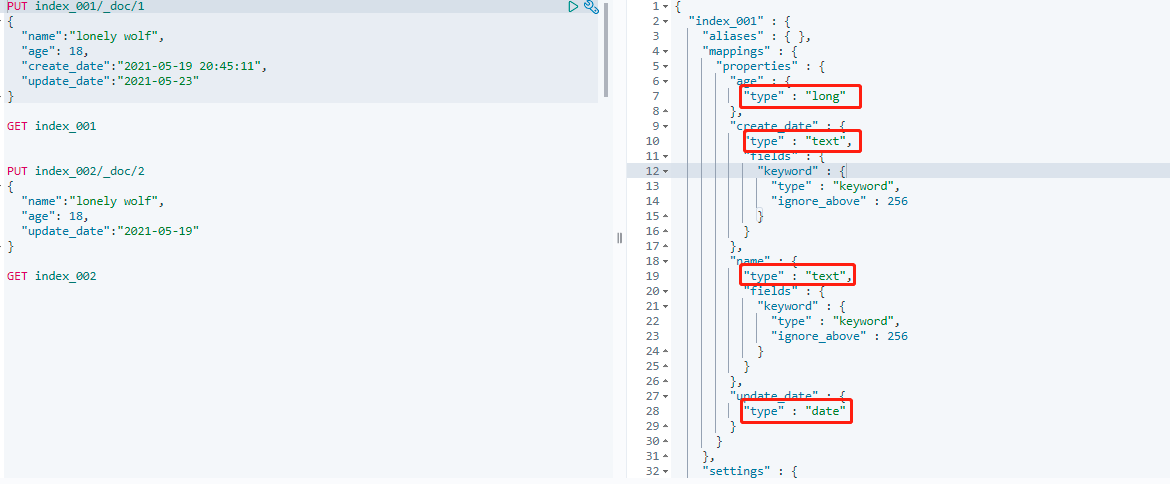
可以发现,这时候索引已经被自动创建了,而且 age 字段被 Elasticsearch 定义为 long 类型,update_date 被定义为 data 类型,其他两个字段则被推测为 text 类型。
Elasticsearch 中自动映射类型规则可以通过 dynamic 参数进行配置,dynamic 类型有 4 种:
dynamic=true
默认值。当设置为 true 时,一旦有新字段插入文档,则 mapping 会被同步更新。
我们在上面的文档中再插入一个新文档,新文档新增一个 address 字段:
PUT index_001/_doc/2
{
"name":"lonely wolf2",
"age": 20,
"create_date":"2021-05-23 11:37:11",
"update_date":"2021-05-23",
"address":"广东深圳"
}
然后再查看一下 mapping,可以看到 mapping 已经新增了一个 address 字段,mapping 字段被更新意味着该字段会加入索引:

dynamic=runtime
这个类型和 true 类型非常相似,但是有一个非常大的区别就是,虽然加入新字段也会更新 mapping,但是新加入的字段不会被索引,也就是不会使得索引变大,不过虽然不被索引,但是新加入的字段依然可以被查询,只是查询的代价会更大。所以这种类型一般不建议用在经常查询的条件字段上,而更适合用在一些不确定数据结构的日志类索引中。
修改 dynamic 类型:
PUT index_001/_mapping
{
"dynamic": "runtime"
}
新增一个文档,并加入一个新字段:
PUT index_001/_doc/3
{
"email":"123@qq.com"
}
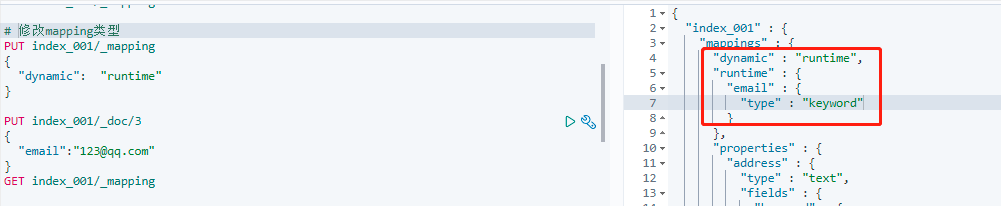
最后询一下 mapping,可以看到字段属性是 runtime,而且类型是 keyword:
下表就是自动创建 mapping 时,Elasticsearch 的映射关系:
| 插入数据类型 | dynamic=true | dynamic=runtime |
|---|---|---|
| null | 不会添加任何字段 | 不会添加任何字段 |
| true 或 false | boolean | boolean |
| double | float | double |
| integer | long | long |
| object | object | object |
| string(通过 date 校验) | date | date |
| string(通过 numreic 校验) | float 或 long | double 或 long |
| string(没有通过 date 或 numreic 校验) | text ,并且同时会创建一个 keyword 子域 | keyword |
| array | 取决于数组中第一个非 null 值 | 取决于数组中第一个非 null 值 |
PS:keyword 表示 不参与分词。
dynamic=false
当设置为 false 时,新加入的字段不会被更新到 mapping,也就是说新字段不会被索引,故以这个字段为条件进行搜索时,无法被搜索到(这一点要注意和 runtime 类型进行区分),不过虽然无法被索引,但是该字段会出现在 _source 中。也就是说该字段不能作为查询条件,但是能被查询出来。
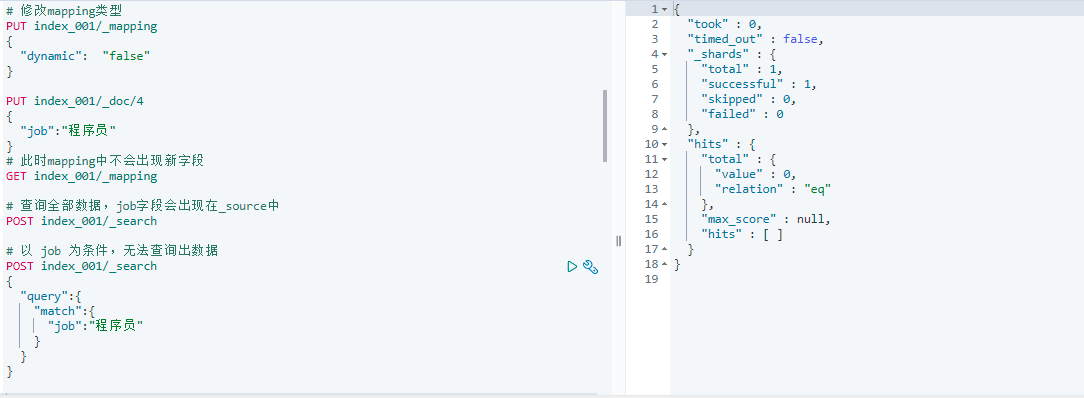
接下来我们将 dynamic 修改为 false,并新增一个字段来验证,可以发现新增的字段会出现在 _source 中,但是无法作为条件被查询出来:
dynamic=strict
这种类型最为严格,表示不允许新增一个不在 mapping 中的字段,一旦新增的字段不在 mapping 定义中,则直接报错:

是否可以修改 mapping 中的数据类型
在 Elasticsearch 中,一旦一个字段被定义在了 mapping 中,是无法被修改的,因为一旦字段被修改了,就会无法被索引(新增字段除外),所以一般我们需要修改索引的话,都会重建索引,并采用 reindex 操作来迁移数据。
关闭 dynamic mapping
可以通过以下两个配置来关闭 dynamic mapping,以下两个属性默认值均为 true,如果需要关闭,则需要修改为 false:
action.auto_create_index: true
index.mapper.dynamic: true
Explicit mapping
Explicit mapping 即:显式映射。也就是说这时候我们需要显示的定义字段类型。
Elasticsearch 中支持的字段类型很多,在这里就举一些比较常用的字段类型:
text 类型
这是最常用的一种类型,存储字符串,用于全文索引。当字段被定义为 text 类型时,默认不能用于聚合,排序等操作:
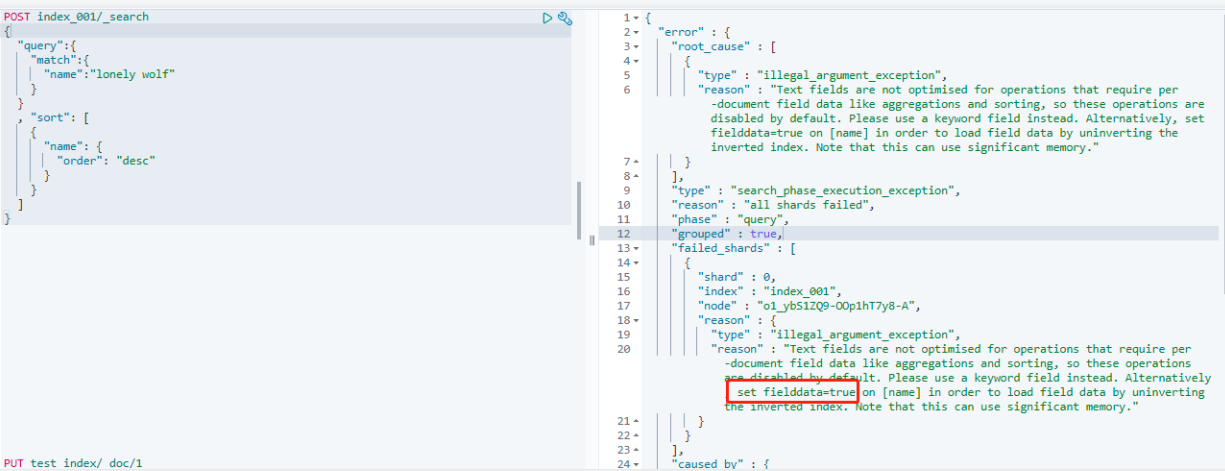
可以看到,用 text 类型字段排序汇报凑,如果想要允许这些操作,可以通过设置 fielddata=true,如下
PUT my-index-011/_mapping
{
"properties": {
"my_field": {
"type": "text",
"fielddata": true
}
}
}
field 字段存储在堆内存中,因为其涉及到的计算比较消耗性能,所以一般不建议设置 fielddata=true,而是通过建立一个 keyword 子域来实现(默认方式):
PUT index_111
{
"mappings": {
"properties": {
"my_field": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}
这种定义方式我们可以将一个字段同时作为 text 和 keyword 类型使用,如果要用于聚合或者排序等操作则可以使用 字段名.keyword 来作为字段名来进行操作:
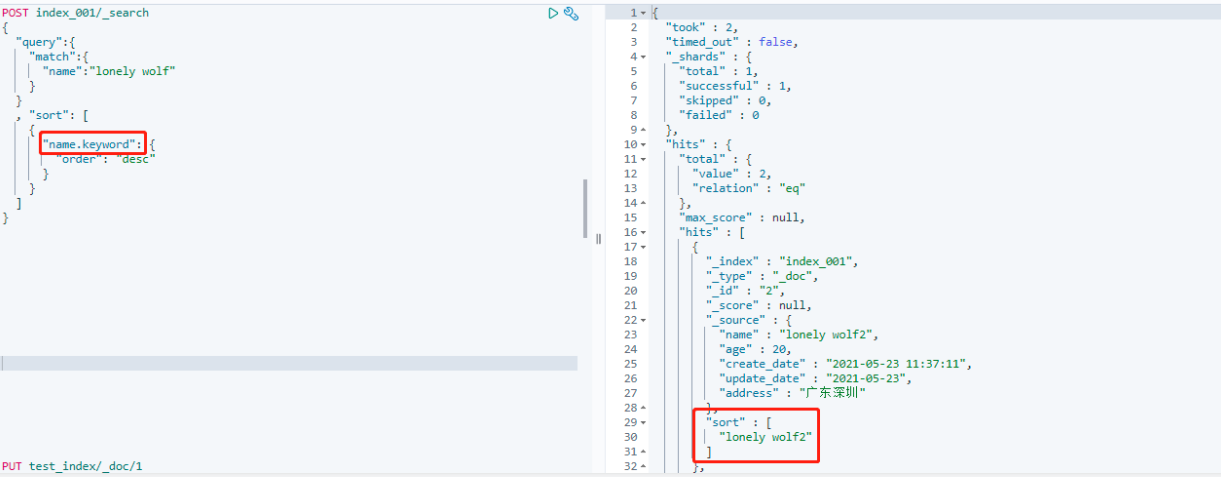
keyword 类型
这种类型也非常常用,该字段存储的数据表示一个整体,不可被分词,所以一般不会用来定义大本文的全文检索字段,而是用来存储一些结构化的字符串,比如:id,邮箱,标签等。
keyword 类型一般用于聚合,排序等操作。除此之外,该字段还有两种衍生类型:constant_keyword 和 wildcard。
constant_keyword:一般用于定义常量类型,比如一个索引中某一个字段全部为同一个值,可以定义为这种类型。wildcard:一般用于模糊匹配查询或者正则匹配查询。
如下就是一个模糊匹配查询的示例(可以配合通配符使用,类似于关系型数据库的 like 操作):
GET index_112/_search
{
"query": {
"wildcard": {
"my_wildcard": {
"value": "*quite*lengthy"
}
}
}
}
date 类型
用于定义日期类型,定义日期类型的同时,可以通过 format 来指定日期的格式:
PUT index_113
{
"mappings": {
"properties": {
"date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
numeric 类型
Elasticsearch 中提供了比较多的格式用来表示不同长度的数字类型:
| 数字类型 | 长度 |
|---|---|
| long | 64 位有符号整数。范围:-2 的 63 次方到 2 的 63 次方 -1 |
| integer | 32 位有符号整数。范围:-2 的 31 次方到 2 的 31 次方 -1 |
| short | 16 位有符号整数。范围:-32768 到 32767 |
| byte | 8 位有符号整数。范围:-128 到 127 |
| double | 64 位双精度小数 |
| float | 32 位单精度小数 |
| half_float | 16 位单精度小数 |
| scaled_float | 带有缩放因子的浮点数,一般适用于存放金额之类的数据。比如 18.88 元,缩放因子是 100,那么在索引时会被索引为 1888(即:原值 * 缩放因子) |
| unsigned_long | 64 位无符号整数。范围:0 到 2 的 64 次方减 1 |
定义方式如下所示:
PUT index_002
{
"mappings": {
"properties": {
"number_of_bytes": {
"type": "integer"
},
"time_in_seconds": {
"type": "float"
},
"price": {
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
boolean 类型
布尔类型比较简单,只有 true 和 false 两种:
PUT index_001
{
"mappings": {
"properties": {
"is_published": {
"type": "boolean"
}
}
}
}
其他类型
除了上面介绍的一些比较常用的数据类型,Elasticsearch 中还有一些高级数据类型:如 Nested(嵌套类型),地理数据类型,ip 类型等。
总结
Elasticsearch 中支持动态 mapping 和显示 mapping 两种,在使用中有时候可以先插入一条数据到临时索引,等自动生成 mapping 之后,在对现有 mapping 进行修改调整,在字段上尤其要考虑好 text 类型和 keyword 类型的设置,如果需要支持全文搜索和分词搜索,则需要使用 text 类型,需要支持关键字模糊搜索或者聚合排序等操作可以考虑使用 keyword 字段。
如何设计一个高性能 Elasticsearch mapping的更多相关文章
- 如何设计一个RPC系统
版权声明:本文由韩伟原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/162 来源:腾云阁 https://www.qclou ...
- 如何设计一个简单的C++ ORM
2016/11/15 "没有好的接口,用C++读写数据库和写图形界面一样痛苦" 阅读这篇文章前,你最好知道什么是 Object Relation Mapping (ORM) 阅读这 ...
- 一个高性能、轻量级的分布式内存队列系统--beanstalk
Beanstalk是一个高性能.轻量级的.分布式的.内存型的消息队列系统.最初设计的目的是想通过后台异步执行耗时的任务来降低高容量Web应用系统的页面访问延迟.其实Beanstalkd是典型的类Mem ...
- Beanstalkd 一个高性能分布式内存队列系统
需要一个分布式内存队列,能支持这些特性:任务不重不漏的分发给消费者(最基础的).分布式多点部署.任务持久化.批量处理.错误重试..... 转载:http://rdc.taobao.com/blog/c ...
- 如何设计一个 RPC 系统
本文由云+社区发表 RPC是一种方便的网络通信编程模型,由于和编程语言的高度结合,大大减少了处理网络数据的复杂度,让代码可读性也有可观的提高.但是RPC本身的构成却比较复杂,由于受到编程语言.网络模型 ...
- 用PHP打造一个高性能好用的网站
用PHP打造一个高性能好用的网站 1. 说到高可用的话要提一下redis,用过的都知道redis是一个具备数据库特征的nosql,正好弥补了PHP的瓶颈,个人认为PHP的 瓶颈在于数据库,像Apach ...
- Elasticsearch教程(五) elasticsearch Mapping的创建
一.Mapping介绍 在Elasticsearch中,Mapping是什么? mapping在Elasticsearch中的作用就是约束. 1.数据类型声明 它类似于静态语言中的数据类型声明,比如声 ...
- 高并发架构系列:如何从0到1设计一个类Dubbo的RPC框架
在过去持续分享的几十期阿里Java面试题中,几乎每次都会问到Dubbo相关问题,比如:“如何从0到1设计一个Dubbo的RPC框架”,这个问题主要考察以下几个方面: 你对RPC框架的底层原理掌握程度. ...
- 如何设计一个优秀的API
如何设计一个优秀的API - 文章 - 伯乐在线 http://blog.jobbole.com/42317/ 如何设计一个优秀的API - 标点符 https://www.biaodianfu.co ...
随机推荐
- JAVA 写一个方法,判断一个整数是否为素数
1 import java.util.Scanner; 2 3 public class Question3 { 4 public static void main(String[] args) { ...
- java例题_34 用指正对三个数排序
1 /*34 [程序 34 三个数排序] 2 题目:输入 3 个数 a,b,c,按大小顺序输出. 3 程序分析:利用指针方法. 4 */ 5 6 /*分析 7 * 指针方法的本质是按地址传值,将a,b ...
- 鸿蒙运行报错:Failure[INSTALL_PARSE_FAILED_USESDK_ERROR] Error while Deploying HAP
问题描述 近期,使用DevEco-Studio新建手机类型的工程,编译成功,发布到模拟器(鸿蒙P40)时出错,如下图: 原因分析 本地DevEco-Studio使用的SDK版本与设备(P40)不匹配导 ...
- vue 快速入门 系列
vue 快速入门(未完结,持续更新中...) 前言 为什么要学习 vue 现在主流的框架 vue.angular 和 react 都是声明式操作 DOM 的框架.所谓声明式,就是我们只需要描述状态与 ...
- ( ) 与 { } 差在哪?-- Shell十三问<第七问>
( ) 与 { } 差在哪?-- Shell十三问<第七问> 先说一下,为何要用 ( ) 或 { } 好了. 许多时候,我们在 shell 操作上,需要在一定条件下一次执行多个命令,也就是 ...
- [矩阵乘法]裴波拉契数列II
[ 矩 阵 乘 法 ] 裴 波 拉 契 数 列 I I [矩阵乘法]裴波拉契数列II [矩阵乘法]裴波拉契数列II Description 形如 1 1 2 3 5 8 13 21 34 55 89 ...
- ionic3+angular 倒计时效果
// 声明变量 applicationInterval: any; // 定时器 nextBtnText: String; nextBtnBool: Boolean; // 使用定时器,每秒执行一次 ...
- 【pytest系列】- assert断言的使用
unittest断言方式是用过框架自己实现的,即self.assertEqual()等,当我们使用pytest框架后,这种断言方式是不可用的,因为测试类不会再继承unittest.TestCase类, ...
- RE.从单链表开始的数据结构生活(bushi
单链表 单链表中节点的定义 typedef struct LNode{ int data;//数据域 struct LNode *next;//定义一个同类型的指针,指向该节点的后继节点 }LNode ...
- Seata搭建与分布式事务入门
在单体架构下,我们大多使用的是单体数据库,通过数据库的ACID特性支持,实现了本地事务.但是在微服务架构下复杂的业务关系中,分布式事务是不可避免的问题之一.Seata是Spring Cloud Ali ...