python 爬虫得到网页的图片
import urllib.request,os
import re # 获取html 中的内容
def getHtml(url):
page=urllib.request.urlopen(url)
html=page.read()
return html path='本地存储位置' # 保存路径
def saveFile(x):
if not os.path.isdir(path):
os.makedirs(path)
t = os.path.join(path,'%s.jpg'%x)
return t html=getHtml('https://。。。') # 获取网页的图片
def getImg(html):
# 正则表达式
reg=r'src="(https://imgsa[^>]+\.(?:jpeg|jpg))"'
# 编译正则表达式
imgre=re.compile(reg)
imglist=re.findall(imgre,html.decode('utf-8'))
x=0
for imgurl in imglist:
# 下载图片
urllib.request.urlretrieve(imgurl,saveFile(x))
print(imgurl)
x+=1
if x==23:
break
print(x)
return imglist getImg(html)
print('end')
正则表达式:
^ : 字符串的开始,
$: 字符串的末尾
. : 匹配任意字符,除换行符
* : 任意多的字符
+: 任意大于1 的字符
?: 匹配0或1个, home-?brew : homebrew, 或home-brew
[]: 指定一个字符类别,可以单独列出,也可以使用- 表示一个区间。[abc]匹配a,b,c 中的任意一个字符,也可以表示[a-c]的字符集
[^]: ^ 作为类别的首个字符,[^5]将匹配除5之外的任意字符
\ : 转义字符
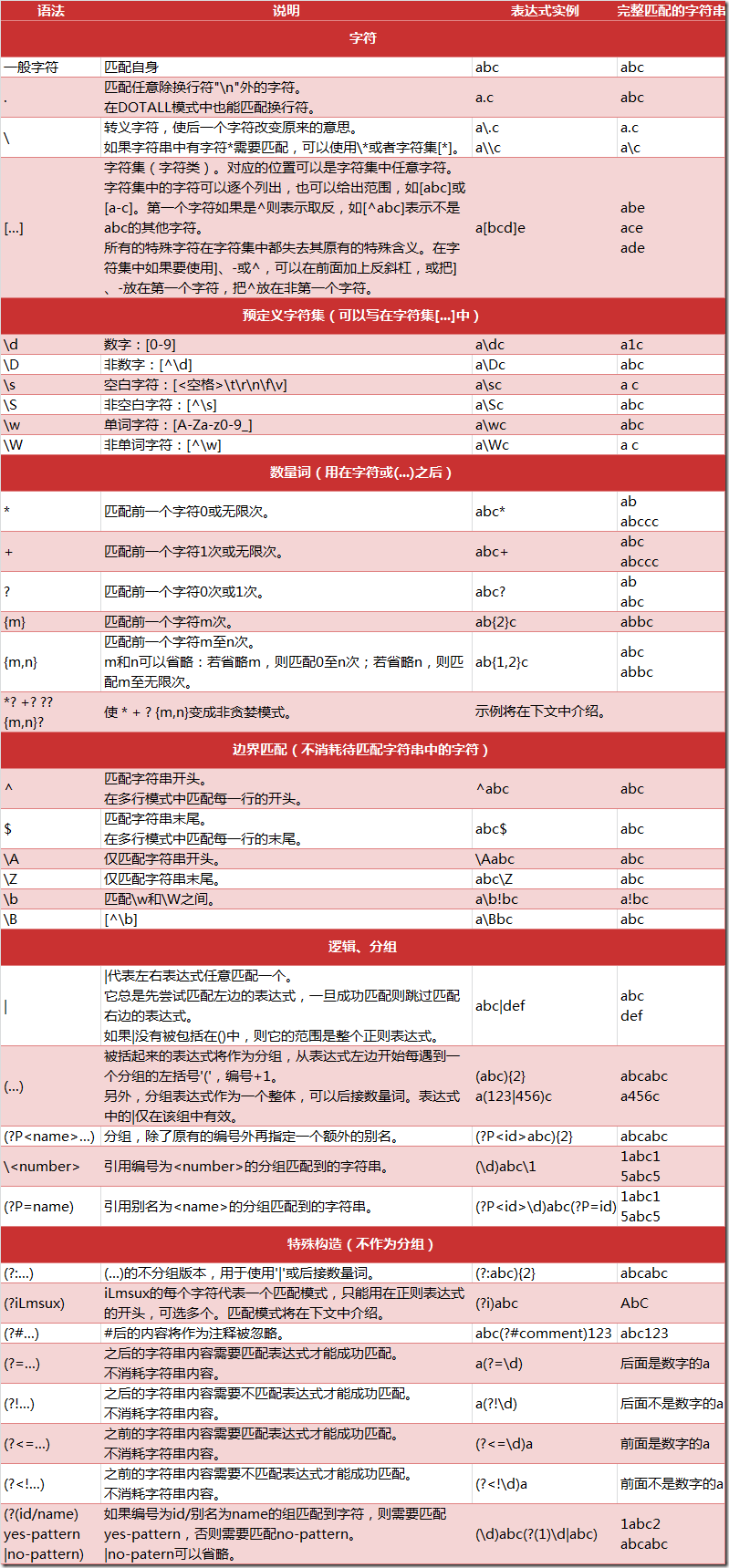
加反斜杠取消特殊性。\ section, 为了匹配反斜杠,就得写为\\, 但是\\ 又有别的意思。。大量反斜杠。。。 使用raw字符串表示,在字符串前加r,反斜杠就不会当做特殊处理,\n 表示两个字符\ 和n,而不是换行。
如: https://imgsa[^>]+\.(?:jpeg|jpg) 表示 https://imgsa(不匹配>的多余1个的字符串).
| 方法/属性 | 作用 |
| match() | 决定 RE 是否在字符串刚开始的位置匹配 |
| search() | 扫描字符串,找到这个 RE 匹配的位置 |
| findall() | 找到 RE 匹配的所有子串,并把它们作为一个列表返回 |
| finditer() | 找到 RE 匹配的所有子串,并把它们作为一个迭代器返回 |
| 方法/属性 | 作用 |
| group() | 返回被 RE 匹配的字符串 |
| start() | 返回匹配开始的位置 |
| end() | 返回匹配结束的位置 |
| span() | 返回一个元组包含匹配 (开始,结束) 的位置 |
实现: 在一个文档中找到system('***'); 并且在后面加上print('***')
文档为:
aba
cdc
system('a');
cde;
system('d');
写入 system\([\s\S]*\) 查找(\s \t\n..空白字符,\S 非空白字符,[]表示选择匹配一个,* 表示0个或多个), 找到的为:
system('a');
cde;
system('d');
因为会匹配最长的一个,要匹配第一个匹配的字符串:system\([\s\S]*?\)。
要替换为:
aba
cdc
system('a');
'a'
cde;
system('d');
'd'
python 爬虫得到网页的图片的更多相关文章
- python爬虫抓网页的总结
python爬虫抓网页的总结 更多 python 爬虫 学用python也有3个多月了,用得最多的还是各类爬虫脚本:写过抓代理本机验证的脚本,写过在discuz论坛中自动登录自动发贴的脚本,写过自 ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- Python爬虫之网页图片抓取
一.引入 这段时间一直在学习Python的东西,以前就听说Python爬虫多厉害,正好现在学到这里,跟着小甲鱼的Python视频写了一个爬虫程序,能实现简单的网页图片下载. 二.代码 __author ...
- Python爬虫解析网页的4种方式 值得收藏
用Python写爬虫工具在现在是一种司空见惯的事情,每个人都希望能够写一段程序去互联网上扒一点资料下来,用于数据分析或者干点别的事情. 我们知道,爬虫的原理无非是把目标网址的内容下载下来存储到内存 ...
- python爬虫 前程无忧网页抓取
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- Python爬虫之简单的图片获取
简单的静态网页的图片获取: import urllib import re import os url = 'http://www.toutiao.com/a6467889113046450702/' ...
- Python 爬虫学习 网页图片下载
使用正则表达式匹配 # coding:utf-8 import re import urllib def get_content(url): """ Evilxr, &q ...
- [记录][python]python爬虫,下载某图片网站的所有图集
随笔仅用于学习交流,转载时请注明出处,http://www.cnblogs.com/CaDevil/p/5958770.html 该随笔是记录我的第一个python程序,一个爬去指定图片站点的所有图集 ...
- python爬虫中文网页cmd打印出错问题解决
问题描述 用python写爬虫,很多时候我们会先在cmd下先进行尝试. 运行爬虫之后,肯定的,我们想看看爬取的结果. 于是,我们print... 运气好的话,一切顺利.但这样的次数不多,更多地,我们会 ...
随机推荐
- Spring cloud config 使用gitHub或者gitee连接
1. 创建SpringCloud项目,引入对应的Spring-config-server对应的jar <dependency> <groupId>org.springframe ...
- Spring Mvc和Spring Boot配置Tomcat支持Https
SpringBoot配置支持https spring boot因为是使用内置的tomcat,所以只需要一些简单的配置即可. 1.首先打开命令行工具,比如cmd,输入以下命令 keytool -genk ...
- LOJ#2541 猎人杀
解:step1:猎人死了之后不下台,而是继续开枪,这样分母不变...... 然后容斥,枚举猎人集合s,钦定他们在1之后死.定义打到1的时候结束,枚举游戏在i轮时结束. 发现式子是一个1 + x + x ...
- A1013. Battle Over Cities
It is vitally important to have all the cities connected by highways in a war. If a city is occupied ...
- zabbix自动发现
zabbix3.4 Discovery自动发现教程 Zabbix 创建发现规则创建发现规则配置 ---- 自动发现 ---- 创建发现规则 看一个例子 这样发现规则就没有问题了,下面让主机自动加入到某 ...
- mysql视图和临时表的区别
视图 视图是由从数据库的基本表中选出来的数据组成的逻辑窗口,它与基本表不同的是,视图是一个虚表.数据库中只存放视图的定义,而不存放视图包含的数据,这些数据仍存放在原来的基表中.所以基表中的数据如果发生 ...
- JAVA概述 也许你会豁然开朗
1.JDK:Java Development Kit,java的开发和运行环境,java的开发工具和jre. 2.JRE:Java Runtime Environment,java程序的运行环境,ja ...
- 第十五篇-EditText做简单的登录框
TextView和EditText的简单应用. MainActivity.java package com.example.aimee.edittexttest; import android.sup ...
- python pip NameError:name 'pip' is not defined”
https://www.jianshu.com/p/f57f98ebcb21 问题: 如果直接在命令行里面输入pip或者pip3,提示:(如图1) “NameError:name 'pip' is n ...
- mongoDB-Explain
新版的MongoDB中的Explain已经变样了 Explain支持三种Mode queryPlanner Mode db.collection.explain() 默认mode是queryPlann ...