008 在大数据中,关于native包的编译步骤
一。问题的由来:

二。解决问题的方法(所有的操作在root下完成):
1.前期需要的环境,下面的已经在伪分布式中配置好,不再重复
配置好jdk
配置好hadoop
2.上传还需要包

apache-maven-3.0.5-bin.tar.gz和protobuf-2.5.0.tar.gz
maven是项目管理与项目构建自动化工具,在这之前必须保证安装jdk。
protobuf是一种数据化方式。用于通信和存储的序列化,结构化的协议。
3.解压maven到指定的目录
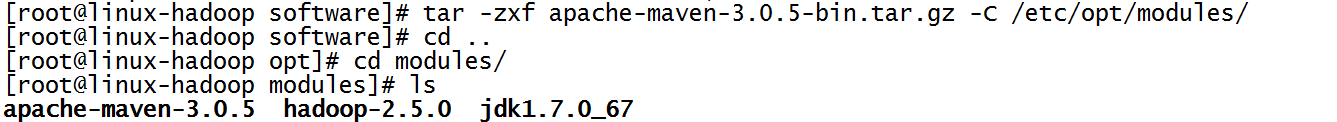
4.配置maven的环境变量和路径(需要在root下)

5.source一下,使环境变量尽快生效

6.退出

7.重新登录,检验mvn

8.安装gcc/gcc-c++

9.make
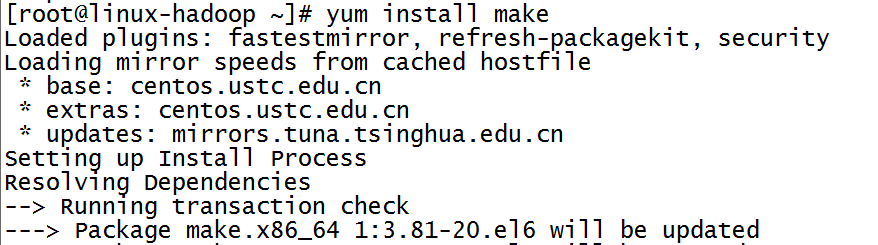
make是Linux下的一款程序自动维护工具,配合makefile的使用,就能够根据程序中模块的修改情况,自动判断应该对那些模块重新编译,从而保证软件是由最新的模 块构成。
10.解压安装protobuf
关于什么是protobuf:http://blog.csdn.net/caisini_vc/article/details/5599468

11.指定protobuf安装的位置

12.make
大量的编译后的结果太多。。。。。

13.make install

14. 配置环境变量

15.source一下,使配置环境尽快的生效

16.exit后,重新登录,然后检验protoc是否可以使用

17.下载安装cmake ,openssl-devel ,ncurses-devel
CMake是一个跨平台的安装(编译)工具,可以用简单的语句来描述所有平台的安装(编译过程)。
openssl-devel包是第三方软件开发时使用的Lib包,是用于编译的时候连接的库之类的文件。

18.在编译源码包前,首先进入hadoop-2.5.0-src目录,即是需要解压安装hadoop-2.5.0-src

19.编译

20.剩下就是等待即可。
008 在大数据中,关于native包的编译步骤的更多相关文章
- 在大数据中,关于native包的编译步骤
一.问题的由来: 二.解决问题的方法(所有的操作在root下完成): 1.前期需要的环境,下面的已经在伪分布式中配置好,不再重复 配置好jdk 配置好hadoop 2.上传还需要包 apache-ma ...
- 基于简单sql语句的sql解析原理及在大数据中的应用
基于简单sql语句的sql解析原理及在大数据中的应用 李万鸿 老百姓呼吁打土豪分田地.共同富裕,总有一天会实现. 全面了解你所不知道的外星人和宇宙真想:http://pan.baidu.com/s/1 ...
- H2O是开源基于大数据的机器学习库包
H2O是开源基于大数据的机器学习库包 H2O能够让Hadoop做数学,H2O是基于大数据的 统计分析 机器学习和数学库包,让用户基于核心的数学积木搭建应用块代码,采取类似R语言 Excel或JSON等 ...
- NoSQL在大数据中的应用
一.序言 NoSQL是Not Only SQL的缩写,而不是Not SQL,指的是非关系型的数据库,它不一定遵循传统数据库的一些基本要求,比如说遵循SQL标准.ACID属性.表结构等等.相比传统数据库 ...
- Apache Hudi在医疗大数据中的应用
本篇文章主要介绍Hudi在医疗大数据中的应用,主要分为5个部分进行介绍:1. 建设背景,2. 为什么选择Hudi,3. Hudi数据同步,4. 存储类型选择及查询优化,5. 未来发展与思考. 1. 建 ...
- 大数据中必须要掌握的 Flink SQL 详细剖析
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言. 自 2015 年开始,阿里巴巴开始调研开源流计算引擎,最终决定基于 ...
- 大数据中HBase的Java接口封装
该文前提为已经搭建好的HBase集群环境,参见 HBase集群搭建与配置 ,本文主要是用Java编写一个Servlet接口,部署在Tomcat服务器上,用于提供http的接口供其他地方调用,接口中集成 ...
- 002 在大数据中基础的llinux基本命令
一:基本命令 1.显示当前的目录 2.长格式显示目录自身的信息 3.创建文件 4.创建目录 创建多层目录,使用-p. 5.删除目录或者文件 -f:不提示,强制删除 -i:删除前,提示 -r:删除目录以 ...
- 大数据中Hadoop集群搭建与配置
前提环境是之前搭建的4台Linux虚拟机,详情参见 Linux集群搭建 该环境对应4台服务器,192.168.1.60.61.62.63,其中60为主机,其余为从机 软件版本选择: Java:JDK1 ...
随机推荐
- C# pdf转word
引用组件 Spire.Pdf,去官网下载安装,在bin目录里面有需要的dll文件. static void Main(string[] args) { #region Pdf转word PdfDocu ...
- 驳2B文 "我为什么放弃Go语言"
此篇文章流传甚广, 其实里面没啥干货, 而且里面很多观点是有问题的. 这个文章在 golang-china 很早就讨论过了. 最近因为 Rust 1.0 和 1.1 的发布, 导致这个文章又出来毒 ...
- Confluence 6 安装 Oracle
如果你还没有在安装可以连接的 Oracle 数据库,请先下载后进行安装.请参考 Oracle 文档 来获取有关安装的指南. 当你设置你的 Oracle 服务器的时候: 字符集 必须使用 AL32UTF ...
- vivado 下安装modelsim
安装modelsim 下载链接:http://pan.baidu.com/s/1i4vHDbR 密码:dksy 1.运行modelsim-win64-10.4-se.exe,安装软件: 注意事项:安装 ...
- Python之函数(自定义函数,内置函数,装饰器,迭代器,生成器)
Python之函数(自定义函数,内置函数,装饰器,迭代器,生成器) 1.初始函数 2.函数嵌套及作用域 3.装饰器 4.迭代器和生成器 6.内置函数 7.递归函数 8.匿名函数
- 字符串为空的比较 ==与equals() 区别(キ`゚Д゚´)!!基础很重要 !!!
情况描述:我提交的代码,让老大审批了一次,讲真的,对于我来说受益匪浅,其中有一个印象很深的内容:一个字符串是否为空的判断,我以前敲代码一直都是这样写的,可是从来都没有意识到这个东西. 代码: if(s ...
- 【kafka】生产者速度测试
非常有用的参考博客:http://blog.csdn.net/qq_33160722/article/details/52903380 pykafka文档:http://pykafka.readthe ...
- Python基础之继承与派生
一.什么是继承: 继承是一种创建新的类的方式,新建的类可以继承一个或过个父类,原始类成为基类或超类,新建的类则称为派生类 或子类. 其中,继承又分为:单继承和多继承. class parent_cla ...
- JavaScript实现的抛物线运动效果
css88 技术文档地址: http://www.css88.com/archives/5355 张鑫旭 技术文档地址: https://www.zhangxinxu.com 使用示例: 使用时直接引 ...
- MySQL5.7.20安装过程报错CMake Error at cmake/boost.cmake:81 (MESSAGE):
MySQL在5.7版本及以后,都需要boots 库,所以需要先安装boots 步骤: 1.在/usr/local下创建 名为boots的目录 mkdir -p /usr/local/boots 2.进 ...