大数据中Hadoop集群搭建与配置
前提环境是之前搭建的4台Linux虚拟机,详情参见 Linux集群搭建
该环境对应4台服务器,192.168.1.60、61、62、63,其中60为主机,其余为从机
软件版本选择:
Java:JDK1.8.0_191(jdk-8u191-linux-x64.tar.gz)
Hadoop:Hadoop-2.9.2(hadoop-2.9.2.tar.gz)
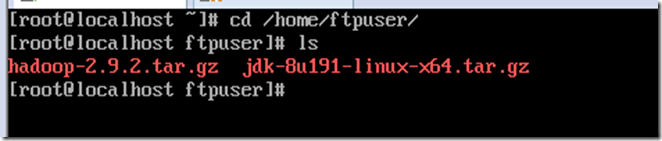
上传hadoop与java到服务器并查看
cd /home/ftpuser/
ls
安装Java
解压Java
mkdir /usr/java
tar -zxvf jdk-8u191-linux-x64.tar.gz -C /usr/java/
配置Java环境变量
vi /etc/profile
添加Java配置
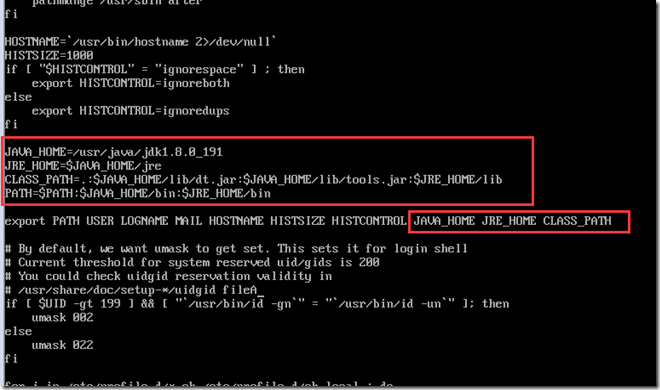
启用配置
source /etc/profile
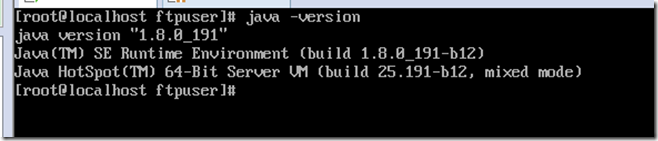
查看是否配置成功
java -version
配置Hadoop主体环境
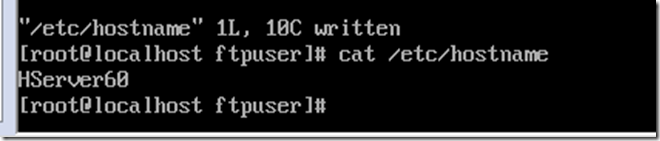
修改hostname,方便认识,这里设置为对应IP的4台服务器HServer60,HServer61,HServer62,HServer63,配置后重启(reboot)生效
vi /etc/hostname
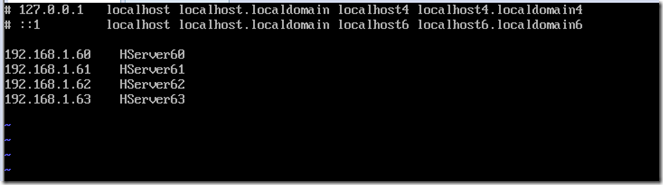
配置hosts文件,对应IP于主机名
vi /etc/hosts
解压hadoop
mkdir /cloud
cd /home/ftpuser/
tar -zxvf hadoop-2.9.2.tar.gz -C /cloud/
一共有5个文件需要配置
hadoop-env.sh
core-site.xml
hdfs-site.xml
yarn-site.xml
yarn-env.sh
mapred-site.xml
slaves
cd /cloud/hadoop-2.9.2/etc/hadoop/
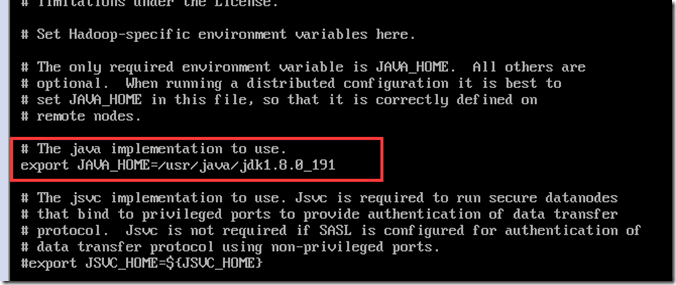
配置hadoop-env.sh
vi hadoop-env.sh
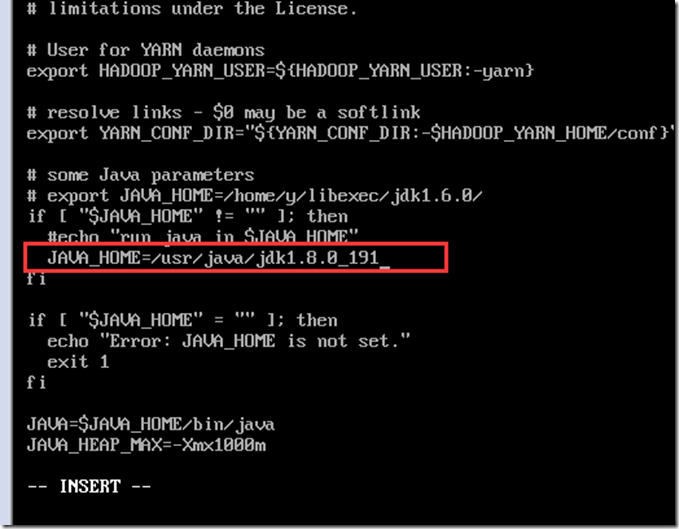
配置yarn-env.sh
vi yarn-env.sh
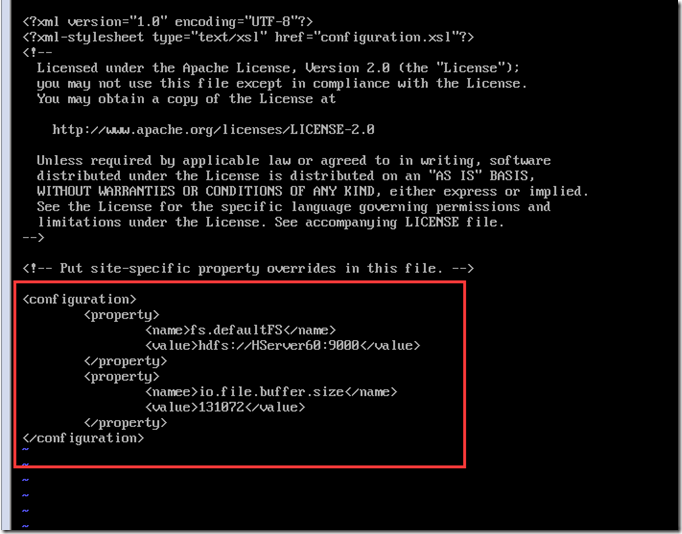
配置core-site.xml
vi core-site.xml
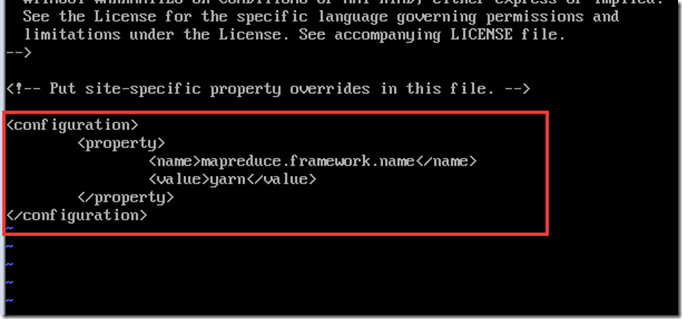
配置mapred-site.xml,先从模板复制一份配置出来,并修改
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
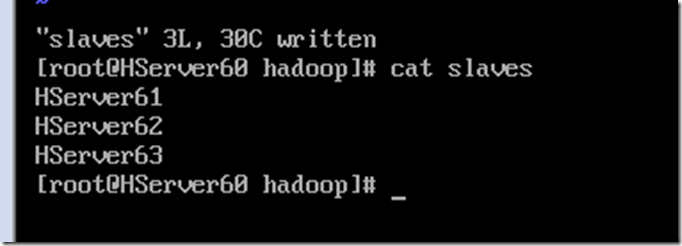
配置slaves,写入从机名称
vi slaves
剩下的2个文件hdfs-site.xml与yarn-site.xml需要区分主机NameNode与从机DataNode的配置
主机NameNode的hdfs-site.xml配置
vi hdfs-site.xml
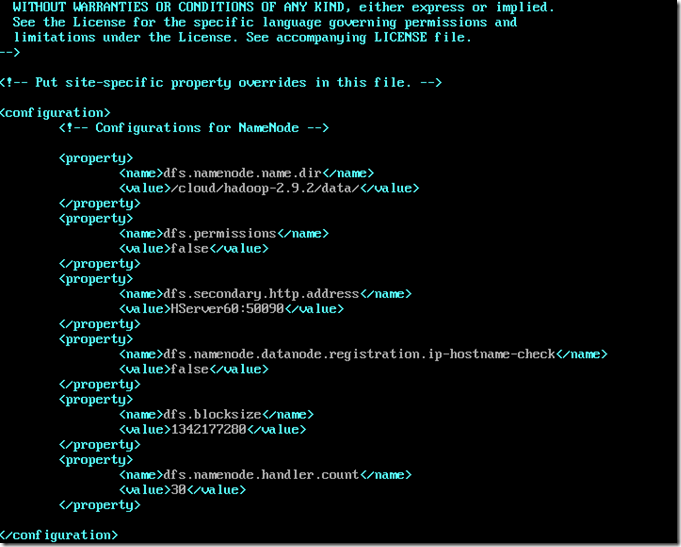
其中blocksize可以根据情况自行调整,是数据块的大小,handler.cout一般几台小集群10都足够了
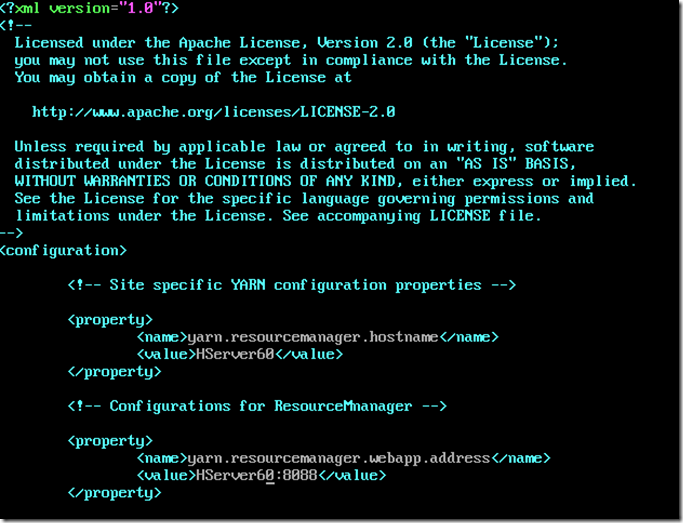
主机NameNode的yarn-site.xml配置
vi yarn-site.xml
从机DataNode的hdfs-site.xml配置
vi hdfs-site.xml
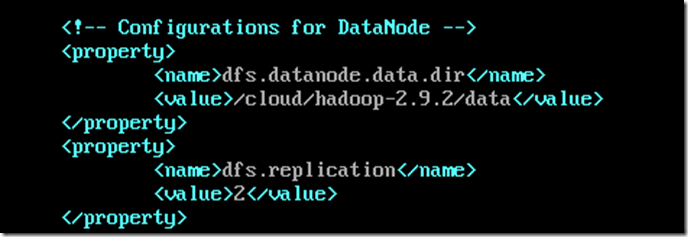
其中replication为备份数
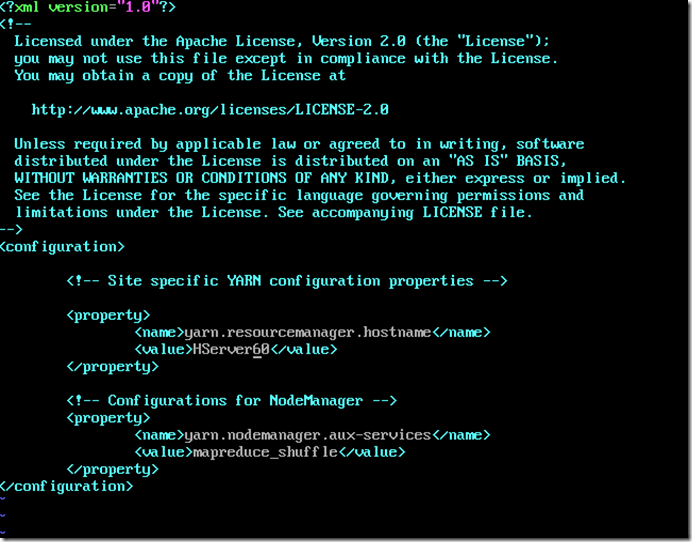
从机DataNode的yarn-site.xml配置
vi yarn-site.xml
设置NameNode免密登录,在主机上操作
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.1.61
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.1.62
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.1.63
可以将配置好的东西通过scp命令复制到远程服务器上
scp -rp /cloud/hadoop-2.9.2 root@192.168.1.62:/cloud/
整个Hadoop集群配置完毕,可以启动试试看,这里换到我已经搭建好的4台服务器,50、51、52、53
启动命令在hadoop目录的sbin文件夹中,也可以在/etc/profile文件中配置环境变量,类似java配置,将该目录加入path路径
启动hadoop集群,通过jps查看是否启动了
start-all.sh
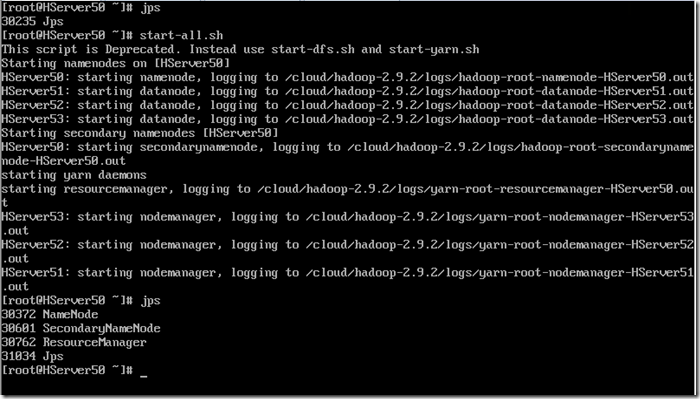
主机jps上会有NameNode,ResourceManager,SecondaryNameNode
从机jps上会有NodeManager,DataNode
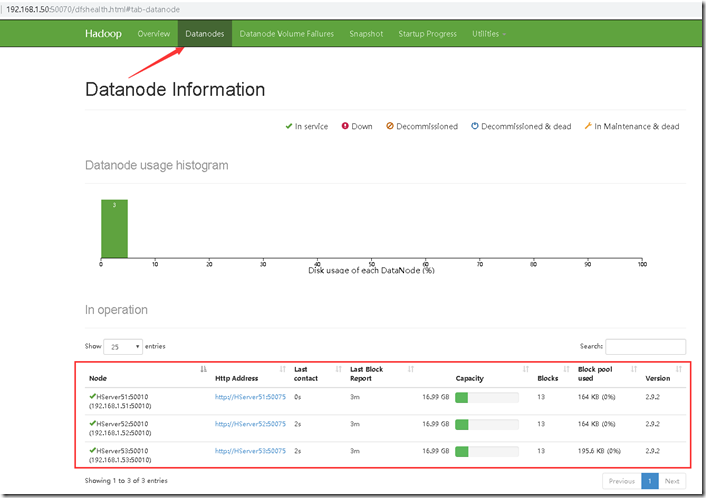
这样就成功的启动了,访问主机IP:50070的URL访问
大数据中Hadoop集群搭建与配置的更多相关文章
- 大数据中HBase集群搭建与配置
hbase是分布式列式存储数据库,前提条件是需要搭建hadoop集群,需要Zookeeper集群提供znode锁机制,hadoop集群已经搭建,参考 Hadoop集群搭建 ,该文主要介绍Zookeep ...
- 大数据中Linux集群搭建与配置
因测试需要,一共安装4台linux系统,在windows上用vm搭建. 对应4个IP为192.168.1.60.61.62.63,这里记录其中一台的搭建过程,其余的可以直接复制虚拟机,并修改相关配置即 ...
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据平台Hadoop集群搭建
一.概念 Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce.HDFS是一个分布式文件系统,类似mogilef ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- Java+大数据开发——Hadoop集群环境搭建(一)
1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 NameNode / DataN ...
- Java+大数据开发——Hadoop集群环境搭建(二)
1. MAPREDUCE使用 mapreduce是hadoop中的分布式运算编程框架,只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现一个强大的海量数据并发处理程序 2. Demo开发--wo ...
- 大数据-HBase HA集群搭建
1.下载对应版本的Hbase,在我们搭建的集群环境中选用的是hbase-1.4.6 将下载完成的hbase压缩包放到对应的目录下,此处我们的目录为/opt/workspace/ 2.对已经有的压缩包进 ...
随机推荐
- Log4net 使用之 日期字段格式化
Log4net 是.Net下一个非常优秀的开源日志记录组件.log4net记录日志的功能非常强大.它可以将日志分不同的等级,以不同的格式,输出到不同的媒介. 之前Log4net的日期字段Data一直采 ...
- codeforces 1007B Pave the Parallelepiped
codeforces 1007B Pave the Parallelepiped 题意 题解 代码 #include<bits/stdc++.h> using namespace std; ...
- JQuery $.axaj的基本格式
总是忘了,保存以备后用. $.ajax({ url: '', //请求的url地址 dataType: "json", //返回的格式为json async: true, //请求 ...
- mac下git安装和使用
1.下载git客户端,下载地址为:https://git-scm.com/download/mac 2.打开安装包,可以看到此时的界面为: 我们需要把.pkg的安装包安装到系统当中.我双击了安装包 ...
- RAC配置笔记
Iscsi常用命令(我通过openfiler实现iscsi存储) # iscsiadm -m discovery -t st -p IP:port //发现iSCSI存储 # iscsiadm ...
- Linux虚拟机下安装Oracle 11G教程
1.安装环境 操作系统:Red hat 6.5 内存:内存最低要求256M (使用:grep MemTotal /proc/meminfo 命令查看) 交换空间:SWAP交换空间大小根据内存大小决定( ...
- 使用JS与jQuery实现文字逐渐出现特效
该需求出现原因:想要实现一个在一开始加载页面时就出现一行文字逐渐出现的效果,且需要实现的是一种逐渐的过渡出现效果为不是一种生硬的突然间歇性出现.于是便开始尝试利用最近正在学习的jQuery技术和JS实 ...
- jQuery----each()方法
jquery中有隐式迭代,不需要我们再次对某些元素进行操作.但是如果涉及到不同元素有不同操作,需要进行each遍历.本文利用10个li设置不同的透明度的案例,对each方法进行说明. 语法: $(元素 ...
- Dynamics 365 可编辑子网格的字段禁用不可编辑
在365中引入了subgrid的行可编辑,那随之带来的一个问题就是,在主表单禁用的状态下,如何禁用行编辑呢,这里就用到了subgrid的OnRecordSelect方法. 代码很简单, 我这里是禁 ...
- 简单的firebird插入速度测试
Firebird3.0 插入1万条Guid,不带事务:5500ms 插入1万条Guid,带事务:2300ms mssql2008 插入1万条Guid,不带事务:1400ms 插入1万条Guid,带事务 ...