《Enhanced LSTM for Natural Language Inference》(自然语言推理)
解决的问题
自然语言推理,判断a是否可以推理出b。简单讲就是判断2个句子ab是否有相同的含义。
方法
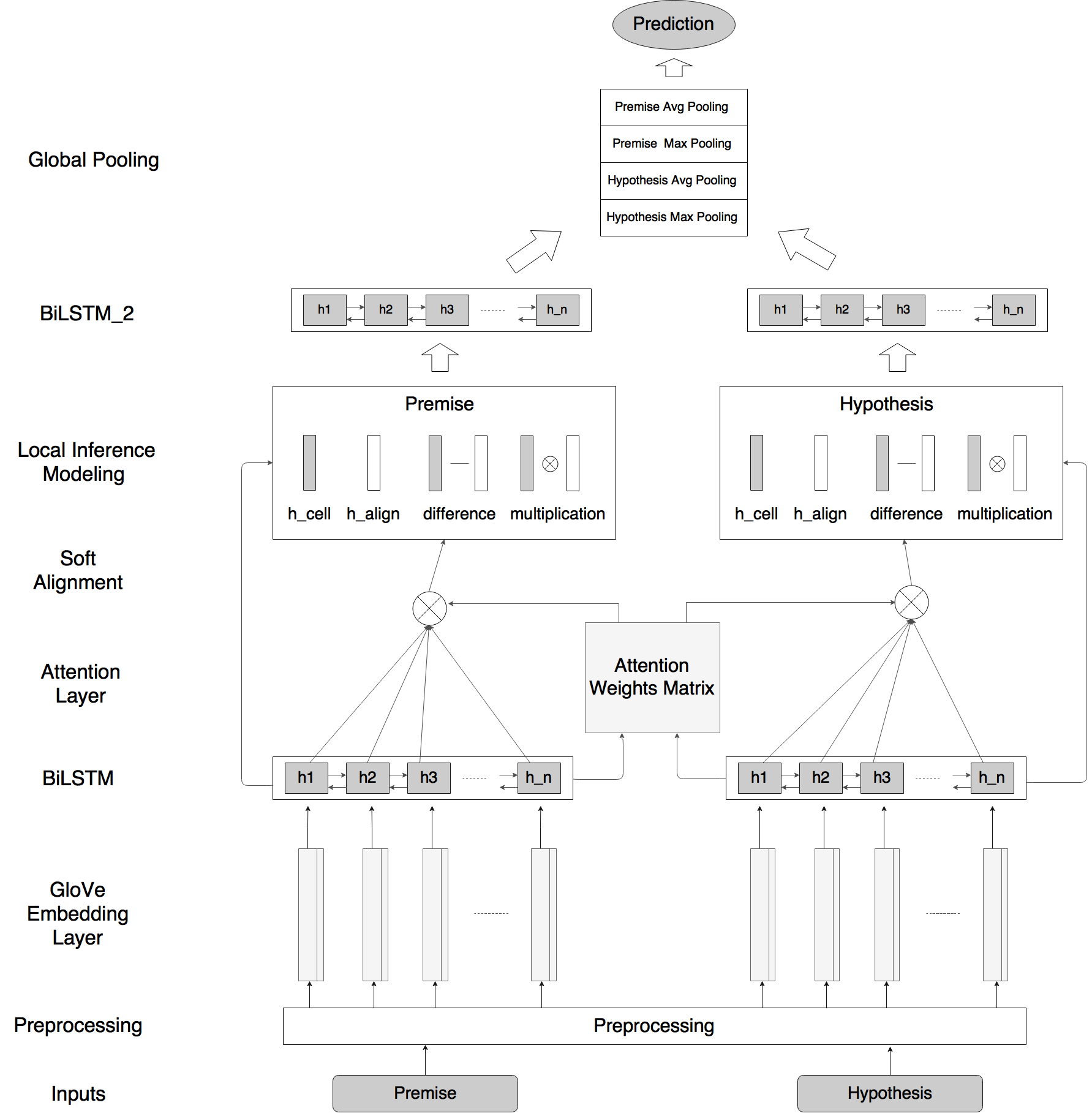
我们的自然语言推理网络由以下部分组成:输入编码(Input Encoding ),局部推理模型(Local Inference Modeling ),和推理合成(inference composition)。结构图如下所示:
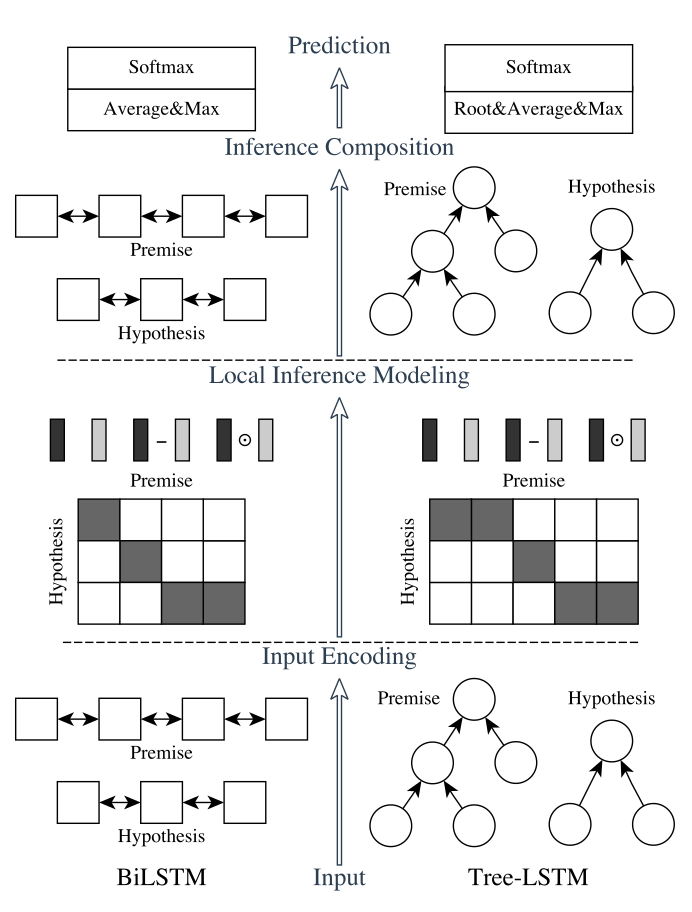
垂直来看,上图显示了系统的三个主要组成部分;水平来看,左边代表称为ESIM的序列NLI模型,右边代表包含了句法解析信息的树形LSTM网络。
输入编码
# Based on arXiv:1609.06038
q1 = Input(name='q1', shape=(maxlen,))
q2 = Input(name='q2', shape=(maxlen,)) # Embedding
embedding = create_pretrained_embedding(
pretrained_embedding, mask_zero=False)
bn = BatchNormalization(axis=2)
q1_embed = bn(embedding(q1))
q2_embed = bn(embedding(q2)) # Encode
encode = Bidirectional(LSTM(lstm_dim, return_sequences=True))
q1_encoded = encode(q1_embed)
q2_encoded = encode(q2_embed)
有2种lstm:
A: sequential model 的做法
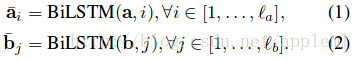
句子中的每个词都有了包含周围信息的 word representation
B: Tree-LSTM model的做法
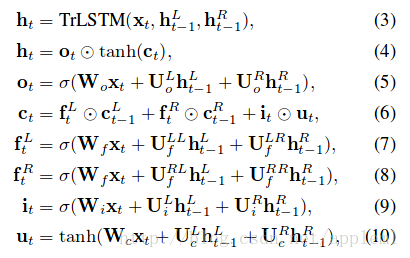
树中的每个节点(短语或字句)有了向量表示 htt
关于tree-LSTM 的介绍需要看文章:
[1] Improved semantic representations from tree-structured long short-term memory networks
[2] Natural Language inference by tree-based convolution and heuristic matching
[3] Long short-term memory over recursive structures
局部推理(Local Inference Modeling )
个人感觉就是一个attention的过程,取了个名字叫局部推理。
A: sequential model
def soft_attention_alignment(input_1, input_2):
"Align text representation with neural soft attention"
attention = Dot(axes=-1)([input_1, input_2]) #计算两个tensor中样本的张量乘积。例如,如果两个张量a和b的shape都为(batch_size, n),
#则输出为形如(batch_size,1)的张量,结果张量每个batch的数据都是a[i,:]和b[i,:]的矩阵(向量)点积。 w_att_1 = Lambda(lambda x: softmax(x, axis=1),
output_shape=unchanged_shape)(attention)
w_att_2 = Permute((2, 1))(Lambda(lambda x: softmax(x, axis=2),
output_shape=unchanged_shape)(attention))
#Permute层将输入的维度按照给定模式进行重排,例如,当需要将RNN和CNN网络连接时,可能会用到该层。
#dims:整数tuple,指定重排的模式,不包含样本数的维度。重拍模式的下标从1开始。
#例如(2,1)代表将输入的第二个维度重拍到输出的第一个维度,而将输入的第一个维度重排到第二个维度 in1_aligned = Dot(axes=1)([w_att_1, input_1])
in2_aligned = Dot(axes=1)([w_att_2, input_2])
return in1_aligned, in2_aligned
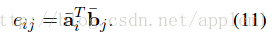
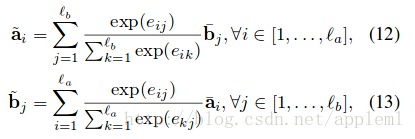
两句话相似或相反的对应
B: Tree-LSTM model
待续
推理合成(inference composition)
a是上层局部推理得到的。

ma 输入LSTM

对 lstm 每个time step 的结果进行pooling.

# Compare
q1_combined = Concatenate()(
[q1_encoded, q2_aligned, submult(q1_encoded, q2_aligned)])
q2_combined = Concatenate()(
[q2_encoded, q1_aligned, submult(q2_encoded, q1_aligned)])
compare_layers = [
Dense(compare_dim, activation=activation),
Dropout(compare_dropout),
Dense(compare_dim, activation=activation),
Dropout(compare_dropout),
]
q1_compare = time_distributed(q1_combined, compare_layers)
q2_compare = time_distributed(q2_combined, compare_layers) # Aggregate
q1_rep = apply_multiple(q1_compare, [GlobalAvgPool1D(), GlobalMaxPool1D()])
q2_rep = apply_multiple(q2_compare, [GlobalAvgPool1D(), GlobalMaxPool1D()])
《Enhanced LSTM for Natural Language Inference》(自然语言推理)的更多相关文章
- <A Decomposable Attention Model for Natural Language Inference>(自然语言推理)
http://www.xue63.com/toutiaojy/20180327G0DXP000.html 本文提出一种简单的自然语言推理任务下的神经网络结构,利用注意力机制(Attention Mec ...
- 论文阅读笔记: Natural Language Inference over Interaction Space
这篇文章提出了DIIN(DENSELY INTERACTIVE INFERENCE NETWORK)模型. 是解决NLI(NATURAL LANGUAGE INFERENCE)问题的很好的一种方法. ...
- <<Natural Language Inference over Interaction Space >> 句子匹配
模型结构 code :https://github.com/YichenGong/Densely-Interactive-Inference-Network 首先是模型图: Embedding Lay ...
- 第四篇:NLP(Natural Language Processing)自然语言处理
NLP自然语言处理: 百度AI的 NLP自然语言处理python语言--pythonSDK文档: https://ai.baidu.com/docs#/NLP-Python-SDK/top 第三方模块 ...
- 《Bilateral Multi-Perspective Matching for Natural Language Sentences》(句子匹配)
问题: Natural language sentence matching (NLSM),自然语言句子匹配,是指比较两个句子并判断句子间关系,是许多任务的一项基本技术.针对NLSM任务,目前有两种流 ...
- Bilateral Multi-Perspective Matching for Natural Language Sentences---读书笔记
自然语言句子的双向.多角度匹配,是来自IBM 2017 年的一篇文章.代码github地址:https://github.com/zhiguowang/BiMPM 摘要 这篇论文主要 ...
- 论文笔记:Tracking by Natural Language Specification
Tracking by Natural Language Specification 2018-04-27 15:16:13 Paper: http://openaccess.thecvf.com/ ...
- 【翻译】Knowledge-Aware Natural Language Understanding(摘要及目录)
翻译Pradeep Dasigi的一篇长文 Knowledge-Aware Natural Language Understanding 基于知识感知的自然语言理解 摘要 Natural Langua ...
- BiMPM:Bilateral Multi-Perspctive Matching for Natural Language Sentences
导言 本论文的工作主要是在 'matching-aggregation'的sentence matching的框架下,通过增加模型的特征(实现P与Q的双向匹配和多视角匹配),来增加NLSM(Natur ...
随机推荐
- 2-5 vue基础语法
一.vue基础语法 语法: {{msg}} html赋值: v-html="" 绑定属性: v-bind:id="" 使用表达式: {{ok? "ye ...
- 关于电信宽带wan口地址变成100.64网段的问题解决
由于之前笔者一直在使用动态域名连接公司vpn.今天在连接vpn的时候总是失败,因动态域名及vpn配置都从未更改过. 于是首先排查动态域名,是否已更新为公司宽带对外的IP.这里笔者先通过nslookup ...
- jmeter函数助手之time函数实操
在一个接口测试中,需要提交的请求中要带时间,在看完jmeter帮忙文档,正好总结一下 1.需求 在一个XML请求中请求数据要带有时间,如下 "><ID>/lte/pdeta ...
- Thinkphp框架下(同服务器下)不同二级域名之间session互通共享设置
在Thinkphp框架下根目录打开index.php 在头部加入如下代码即可: //入口文件 define('DOMAIN','abc.com');//abc.com换成自己的跟域名 //以下两行是为 ...
- intellij idea如何快速格式化代码
选中代码,一键格式化代碼: Ctrl+Alt+L
- Spark2 oneHot编码--标准化--主成分--聚类
1.导入包 import org.apache.spark.sql.SparkSession import org.apache.spark.sql.Dataset import org.apache ...
- 9.5Django
2018-9-5 15:23:00 配置数据库信息 setting MySQLdb 不支持python3 创建表 pycharm 连接数据库 好强大的赶脚
- 一个半径R质量m的均匀圆盘,绕其边缘且垂直的轴摆动,求摆动周期
- Ubuntu:编译Linux内核源代码和内核模块
1. 目的 内核模块需要运行在Linux 3.8.13内核中,因此需要为此内核重新编译内核模块源代码. 2. 步骤 1.在Ubuntu 14.04 64位(内核3.13.0-24-generic)上, ...
- It is not based on WSGI, and it is typically run with only one thread per process.
Tornado Web Server — Tornado 5.1.1 documentation http://www.tornadoweb.org/en/stable/