『科学计算_理论』优化算法:梯度下降法&牛顿法
梯度下降法
梯度下降法用来求解目标函数的极值。这个极值是给定模型给定数据之后在参数空间中搜索找到的。迭代过程为:

可以看出,梯度下降法更新参数的方式为目标函数在当前参数取值下的梯度值,前面再加上一个步长控制参数alpha。梯度下降法通常用一个三维图来展示,迭代过程就好像在不断地下坡,最终到达坡底。为了更形象地理解,也为了和牛顿法比较,这里我用一个二维图来表示:

懒得画图了直接用这个展示一下。在二维图中,梯度就相当于凸函数切线的斜率,横坐标就是每次迭代的参数,纵坐标是目标函数的取值。每次迭代的过程是这样:
- 首先计算目标函数在当前参数值的斜率(梯度),然后乘以步长因子后带入更新公式,如图点所在位置(极值点右边),此时斜率为正,那么更新参数后参数减小,更接近极小值对应的参数。
- 如果更新参数后,当前参数值仍然在极值点右边,那么继续上面更新,效果一样。
- 如果更新参数后,当前参数值到了极值点的左边,然后计算斜率会发现是负的,这样经过再一次更新后就会又向着极值点的方向更新。
根据这个过程我们发现,每一步走的距离在极值点附近非常重要,如果走的步子过大,容易在极值点附近震荡而无法收敛。解决办法:将alpha设定为随着迭代次数而不断减小的变量,但是也不能完全减为零。
梯度下降法实战

我们来求解Ax=b,程序如下:
%matplotlib inline
import copy
import numpy as np
import matplotlib.pyplot as plt A = np.array([[4,2],[1,3]])
b = np.array([[3],[2]]) loss = []
x0 = [copy.deepcopy([]), copy.deepcopy([])]
step = 0.01
x = [[0.],[4]] while (A.dot(x)-b).T.dot(A.dot(x)-b) > 0.1:
dx = 2*A.T.dot(A).dot(x) - 2*A.T.dot(b)
x = x - step*dx
x0[0].append(x[0])
x0[1].append(x[1])
loss.append(np.squeeze((A.dot(x)-b).T.dot(A.dot(x)-b))) line = np.linspace(0,len(x0[0])-1,len(x0[0])) fig,(ax0,ax1)=plt.subplots(2,1, figsize=(9,6))
ax1.plot(line, x0[0])
ax1.plot(line, x0[1])
ax0.plot(line, loss)
ax1.plot(line, np.ones(len(x0[0]))*0.5)
plt.show
上图表示loss函数的降低趋势,下图反映了解的收敛趋势:

牛顿法
首先得明确,牛顿法是为了求解函数值为零的时候变量的取值问题的,具体地,
一阶方法:
当要求解 f(θ)=0时,如果 f可导,那么可以通过迭代公式

来迭代求得最小值。通过一组图来说明这个过程。

二阶方法:
当应用于求解最大似然估计的值时,变成ℓ′(θ)=0的问题。这个与梯度下降不同,梯度下降的目的是直接求解目标函数极小值,而牛顿法则变相地通过求解目标函数一阶导为零的参数值,进而求得目标函数最小值。那么迭代公式写作:

当θ是向量时,牛顿法可以使用下面式子表示:

其中H叫做海森矩阵,其实就是目标函数对参数θ的二阶导数。
通过比较牛顿法和梯度下降法的迭代公式,可以发现两者及其相似。海森矩阵的逆就好比梯度下降法的学习率参数alpha。牛顿法收敛速度相比梯度下降法很快,而且由于海森矩阵的的逆在迭代中不断减小,起到逐渐缩小步长的效果。
牛顿法的缺点就是计算海森矩阵的逆比较困难,消耗时间和计算资源。因此有了拟牛顿法。

实践练习

%matplotlib inline
import copy
import numpy as np
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D A = np.array([[4,2],[1,3]])
b = np.array([[3],[2]]) X, Y = np.meshgrid(np.linspace(-10, 10, 200),np.linspace(-10, 10, 200)) def get_loss(X,Y):
Z = (A[0,0]**2+A[1,0]**2)*X**2 + (A[0,1]**2+A[1,1]**2)*Y**2 - 2*(A[0,0]*A[0,1]+A[1,0]*A[1,1])*X*Y - 2*(A[0,0]*b[0]+A[1,0]*b[1])*X \
- 2*(A[0,1]*b[0]+A[1,1]*b[1])*Y
return Z Z = get_loss(X,Y)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(X,Y,Z,rstride=5, cstride=5, alpha=0.3)
ax.contour(X,Y,Z, alpha=0.3)
cset = ax.contour3D(X, Y, Z, 10, zdir='z', offset=-100, cmap=cm.coolwarm) # 梯度下降法
step = 0.01
x_g = np.array([[0],[-4]])
for i in range(100):
dx_g = 2*A.T.dot(A).dot(x_g[:,-1].reshape(2,1)) - 2*A.T.dot(b)
x_g = np.concatenate((x_g,x_g[:,-1].reshape(2,1) - step*dx_g),axis=1)
z_g = get_loss(x_g[0],x_g[1])
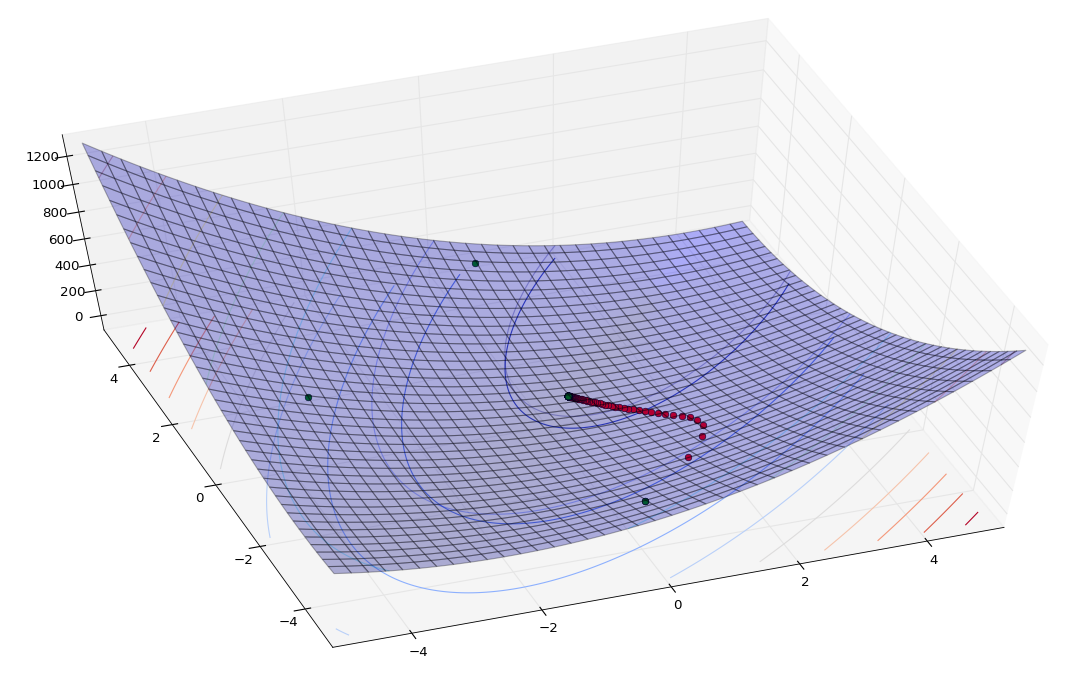
ax.plot(x_g[0],x_g[1],z_g,'ro') # 牛顿法
# 黑塞矩阵
H = np.matrix([[A[0,0]**2+A[1,0]**2, A[0,0]*A[0,1]+A[1,0]*A[1,1]],
[A[0,0]*A[0,1]+A[1,0]*A[1,1], A[0,1]**2+A[1,1]**2]],dtype='float64') * 2
x_n = np.array([[0.],[-4.]])
for i in range(100):
dx_n = 2*A.T.dot(A).dot(x_n[:,-1].reshape(2,1)) - 2*A.T.dot(b)
x_n = np.concatenate((x_n, x_n[:,-1] - np.linalg.inv(H).dot(dx_n)),axis=1)
z_n = get_loss(np.squeeze(np.asarray(x_n[0])),np.squeeze(np.asarray(x_n[1])))
ax.plot(np.squeeze(np.asarray(x_n[0])),np.squeeze(np.asarray(x_n[1])),z_n,'go') f, (ax1, ax2) = plt.subplots(1, 2)
ax1.plot(np.linspace(0,len(z_g)-1,len(z_g)),z_g,'b',label='grad')
ax1.plot(np.linspace(0,len(z_n)-1,len(z_n)),z_n,'r',label='Newton')
ax1.legend() cs = ax2.contour(X,Y,Z)
ax2.clabel(cs, inline=1, fontsize=5)
ax2.plot(np.squeeze(np.asarray(x_n[0])),np.squeeze(np.asarray(x_n[1])),'b')
ax2.plot(x_g[0],x_g[1],'r')
程序学习:
尝试了平面等高线图和线标注的绘制,
cs = ax2.contour(X,Y,Z)
ax2.clabel(cs, inline=1, fontsize=5)
注意到数组拼接方法都是不破坏原数组,单纯返回新数组的,且axis=0是行拼接(行数增加),axis=1是列拼接(列数增加),
x_n = np.concatenate((x_n, x_n[:,-1] - np.linalg.inv(H).dot(dx_n)),axis=1)
学习了numpy中的矩阵类型:np.matrix(),在牛顿法中我用的是matrix,在梯度下降法中我用的是array:
matrix是array的子类,特点是有且必须只是2维,matrix.I()可以求逆,和线代的求逆方法一致,所以绘图时我不得不才用np.sequeeze(np.asarray())操作来降维,而由于x[:, -1]这种操作对array会自动降维(由两行变为一行),所以要么使用matrix,要么切片后reshape(2,1),总之不消停。
结果分析:
从两张角度截一下图,红色是梯度下降蓝色是牛顿法,可以看到,牛顿法收敛速度很快(外围只有3个点),不过这是建立在黑塞矩阵的基础上(需要求解目标函数的二阶偏导数),这是牛顿法快速收敛的原因,也是牛顿法的瓶颈,而且这个瓶颈很直观:我计算黑塞矩阵的numpy矩阵表达方法时的确费了挺大劲(其实原因更多是我渣... ...)



『科学计算_理论』优化算法:梯度下降法&牛顿法的更多相关文章
- 『科学计算_理论』PCA主成分分析
数据降维 为了说明什么是数据的主成分,先从数据降维说起.数据降维是怎么回事儿?假设三维空间中有一系列点,这些点分布在一个过原点的斜面上,如果你用自然坐标系x,y,z这三个轴来表示这组数据的话,需要使用 ...
- 『科学计算_理论』SVD奇异值分解
转载请声明出处 SVD奇异值分解概述 SVD不仅是一个数学问题,在工程应用中的很多地方都有它的身影,比如前面讲的PCA,掌握了SVD原理后再去看PCA那是相当简单的,在推荐系统方面,SVD更是名声大噪 ...
- 『科学计算』可视化二元正态分布&3D科学可视化实战
二元正态分布可视化本体 由于近来一直再看kaggle的入门书(sklearn入门手册的感觉233),感觉对机器学习的理解加深了不少(实际上就只是调包能力加强了),联想到假期在python科学计算上也算 ...
- 『科学计算』通过代码理解SoftMax多分类
SoftMax实际上是Logistic的推广,当分类数为2的时候会退化为Logistic分类 其计算公式和损失函数如下, 梯度如下, 1{条件} 表示True为1,False为0,在下图中亦即对于每个 ...
- python科学计算_scipy_常数与优化
scipy在numpy的基础上提供了众多的数学.科学以及工程计算中常用的模块:是强大的数值计算库: 1. 常数和特殊函数 scipy的constants模块包含了众多的物理常数: import sci ...
- 分布式_理论_06_ 一致性算法 Raft
一.前言 五.参考资料 1.分布式理论(六)—— Raft 算法 2.分布式理论(六) - 一致性协议Raft
- 分布式_理论_05_ 一致性算法 Paxos
一.前言 二.参考资料 1.分布式理论(五)—— 一致性算法 Paxos 2.分布式理论(五) - 一致性算法Paxos
- 『科学计算』L0、L1与L2范数_理解
『教程』L0.L1与L2范数 一.L0范数.L1范数.参数稀疏 L0范数是指向量中非0的元素的个数.如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0,换句话说,让参数W是稀 ...
- 『算法设计_伪代码』贪心算法_最短路径Dijkstra算法
Dijkstra算法实际上是一个贪婪算法(Greedy algorithm).因为该算法总是试图优先访问每一步循环中距离起始点最近的下一个结点.Dijkstra算法的过程如下图所示. 初始化 给定图中 ...
随机推荐
- JSP禁用缓存常用方法
内容主要转自:http://www.cnblogs.com/linjiqin/archive/2011/07/20/2111627.html jsp页面禁止缓存设置 1.客户端缓存要在<head ...
- web前端----css属性
一.文本 1.文本颜色:color 颜色属性被用来设置文字的颜色. 颜色是通过CSS最经常的指定: 十六进制值 - 如: #FF0000 一个RGB值 - 如: RGB(255,0,0) 颜色的名称 ...
- 计算概论(A)/基础编程练习2(8题)/2:计算书费
#include<stdio.h> int main() { // 声明与初始化 ; // k组测试数据的总费用 double s[k]; // 单价表 double price[]= { ...
- SNMP学习笔记之SNMPv3报文认证和加密
下面主要的内容就是SNMPv3的加密和认证过程! USM的定义为实现以下功能: 鉴别 数据加密 密钥管理 时钟同步化 避免延时和重播攻击 1.UsmSecurityParameters(安全参数) 安 ...
- Eclipse中把Java工程修改成web工程
Eclipse中把Java工程修改成web工程 点击项目:右击:选择properties--输入project facets,将“Dynamic Web Module”打勾即可:
- c/c++的typedef/using类型别名
久而久之,发现c/c++的typedef给类型自定义别名的语法糖就保证设计的一致性而言,确实是个相当不错的特性,跟oracle pl/sql的rowtype或type一样,可惜java.mysql均不 ...
- mysql与oracle常用函数及数据类型对比00持续补充
最近在转一个原来使用oracle,改为mysql的系统,有些常用的oracle函数的mysql实现顺便整理了下,主要是系统中涉及到的(其实原来是专门整理过一个详细doc的,只是每次找word麻烦). ...
- 七个月学习Python大计
仅以此篇纪念学习Python征程的开始
- Tempter of the Bone(dfs+奇偶剪枝)题解
Tempter of the Bone Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Othe ...
- 改变checkbox样式问题
选择1 选择2 选择3 选择4 选择5 <form action=""> <label for="test">选择1 <inp ...