基于python3在nose测试框架的基础上添加测试数据驱动工具
[本文出自天外归云的博客园]
Python3下一些nose插件经过2to3的转换后失效了
Python的nose测试框架是通过python2编写的,通过pip3install的方式安装的nose和相关生成报表的插件,执行测试时会报错。原因多是因为涉及到的插件或相关代码是用python2编写的。我们通过python2自带的工具2to3.py文件就可以完成从python2到python3的自动转换。
拿nose_html_reporting插件的转换举例:
将2to3.py文件(Python27/Tools/Scripts路径下可以找到)复制粘贴到nose_html_reporting路径下,执行2to3的转换命令:
python 2to3.py -w __init__.py
执行命令后会在当前路径下自动生成一个__init__.py的备份(bk)文件,和一份已经自动转换成python3的__init__.py文件。
类似要做修改的还有在其他的nose相关的文件夹路径(nose、nose_html_reporting、nose_ittr):

分别cd到以上三个路径下,然后对其中的py文件分别执行2to3的转换命令。或者直接在上级目录对该目录的路径执行2to3的命令,这会让该目录下所有的py文件都完成2to3的转换。
之后就可以让一些nose的插件支持在python3下运行了。
2to3转换的同时也带来了坑
这个转换过程中我也发现了一个坑,2to3以后,原来的ittr_multiplier.py文件中dct.items()会被转成list(dct.items()),而python3中map的含义比较python2也发生了变化。我在执行需要ittr插件支持的测试时发现代码转换后功能并没有生效。经过我在网上查,发现python3中的items和python2中的iteritems方法是有区别的,包括map的定义也会发生变化等等。经我测试,将nose_ittr文件夹中的文件2to3以后,nose_ittr的功能是可以使用的,但是不能传列表值,如果ittr传参传入的是字符串值还好,如果传入的是含有多个字符串值的列表就会有问题,执行测试会报错,要自己再处理列表中的数据。
所以我决定避开插件2to3转换后出现的坑。
我的思路是做一个专门的工具类,用来读取存放在csv文件中的测试数据,联合nose_parameterized一起发挥与java测试框架TestNG中dataprovider类似的功能。
首先封装一个取测试数据的工具类叫“test_data_tool.py”,代码如下:
import csv class T_data_reader(object):
def __init__(self, file_path):
setattr(self, 'file_content_lines', [])
csv_reader = csv.reader(open(file_path, encoding='utf-8'))
for row in csv_reader:
self.file_content_lines.append(row)
fields = self.file_content_lines[0]
setattr(self, 't_data_count', len(self.file_content_lines)-1)
# Traverse t data.
for i in range(len(self.file_content_lines)-1):
t_data = {}
for j in range(len(fields)):
t_data[fields[j]] = self.file_content_lines[i+1][j]
setattr(self, 't_data_'+str(i+1), t_data) def get_t_data_count(self):
return self.t_data_count def get_t_data(file_path):
t_data_reader = T_data_reader(file_path)
t_data_count = t_data_reader.get_t_data_count()
t_data = []
for i in range(t_data_count):
t_data.append(getattr(t_data_reader,"t_data_"+str(i+1)))
return t_data
然后修改测试用例py文件模样如下:
# -*- coding: utf-8 -*-
from nose.tools import *
from test_data_tool import *
from parameterized import parameterized @istest
class Test():
file_path = "QueryTradeInfoTester.csv" @parameterized.expand([
(file_path, 1),
(file_path, 2),
(file_path, 3),
])
def test_1(self, file_path, t_data_number):
t_data = get_t_data(file_path)
setattr(self, 't_data', t_data[t_data_number-1])
assert_equal(self.t_data['retCode'],"")
以上就达到了与java中TestNG框架dataprovider所能达到的类似作用。
其中setattr方法将自身的测试数据分别指向测试数据文件的第一、二、三行。
测试
现在在待测目录下执行nosetests命令就不会报错了,通过执行以下命令可以在测试结束后自动生成测试结果报告的html文件,还可以显示print内容进行程序调试:
nosetests -v -s --with-html-output --html-out-file=result1.html --with-setup-ittr
运行效果如下:
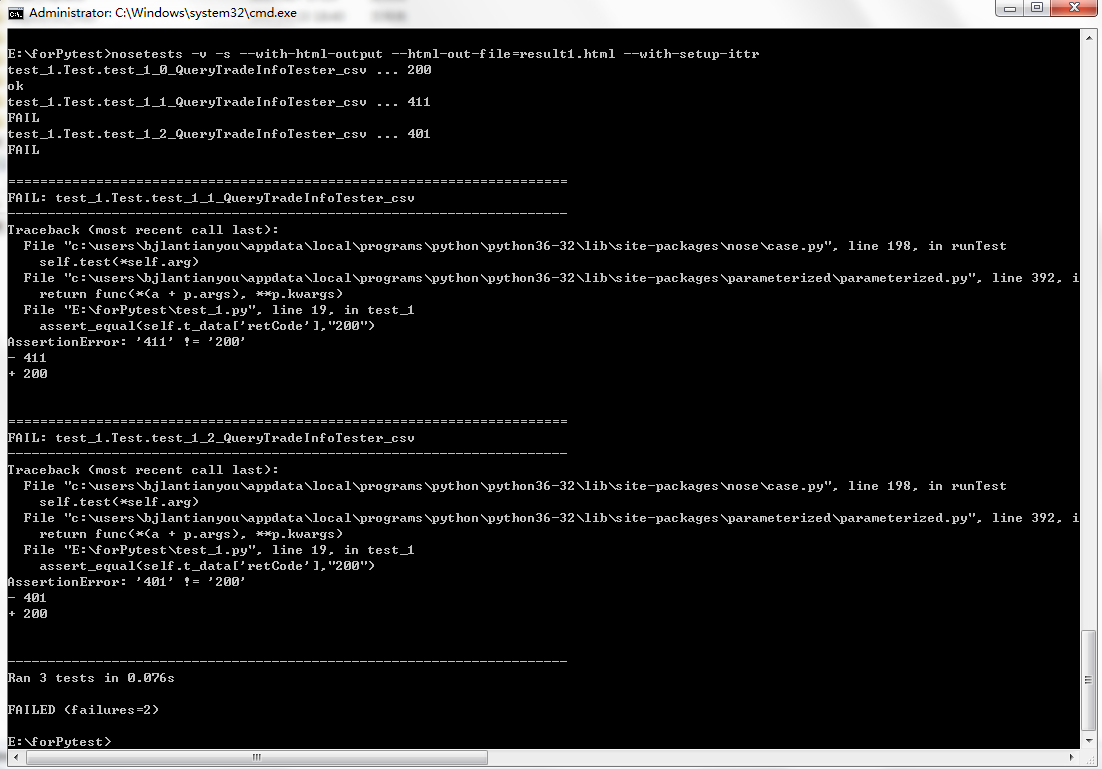
生成的报表文件如下:
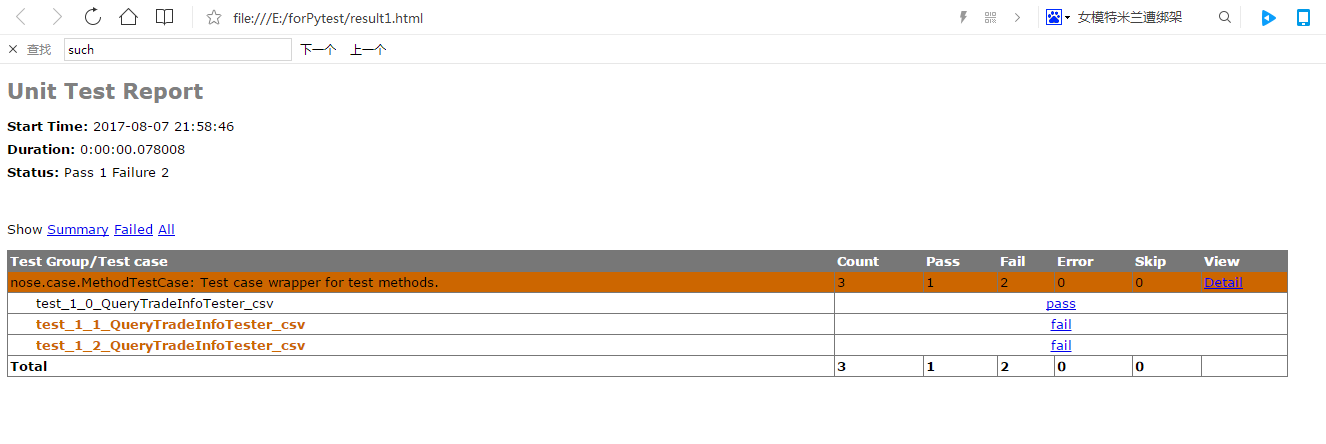
至此nose就完成了到python3的过度,我避开了使用nose_ittr,而是借鉴nose_ittr插件的做法自己写了一个专门用来取测试数据的工具类,配合nose_parameterized一起发挥数据驱动的作用。通过命令行就可以执行nose测试,所以也会很方便与jenkins进行整合构建以达到持续集成的目的。
基于python3在nose测试框架的基础上添加测试数据驱动工具的更多相关文章
- 前端测试框架Jest系列教程 -- Asynchronous(测试异步代码)
写在前面: 在JavaScript代码中,异步运行是很常见的.当你有异步运行的代码时,Jest需要知道它测试的代码何时完成,然后才能继续进行另一个测试.Jest提供了几种方法来处理这个问题. 测试异步 ...
- Spring MVC测试框架详解——服务端测试
随着RESTful Web Service的流行,测试对外的Service是否满足期望也变的必要的.从Spring 3.2开始Spring了Spring Web测试框架,如果版本低于3.2,请使用sp ...
- SpringMvc测试框架详解----服务端测试
随着RESTful Web Service的流行,测试对外的Service是否满足期望也变的必要的.从Spring 3.2开始Spring了Spring Web测试框架,如果版本低于3.2,请使用sp ...
- 一种安全云存储方案设计(下)——基于Lucene的云端搜索与密文基础上的模糊查询
一种安全的云存储方案设计(未完整理中) 一篇老文了,现在看看错漏颇多,提到的一些技术已经跟不上了.仅对部分内容重新做了一些修正,增加了一些机器学习的内容,然并卵. 这几年来,云产品层出不穷,但其安全性 ...
- #测试框架推荐# test4j,数据库测试
# 背景 后端都是操作DB的,这块的自动化测试校验的话,是需要数据库操作的,当然可以直接封装方法来操作数据,那么有没有开源框架支持数据操作,让我们关注写sql语句?或者帮我们做mysql的断言呢? # ...
- [python 测试框架学习篇] 分享 uiautomator测试框架
uiautomator测试框架 :https://testerhome.com/topics/4194
- 基于Python3.6使用Django框架连接mysql数据库的驱动模块安装解决办法
解决办法1 使用PyMySQL模块,直接使用pip install pymysql即可. 参考文章:https://www.cnblogs.com/wcwnina/p/8719482.html 原文内 ...
- ubuntu16.04 源码安装Python3.7 (可以在此基础上安装Tensorflow) (确保Tensorflow计算框架与系统的彻底隔离)
Python3.7 源码下载: https://www.python.org/downloads/release/python-370/ 解压源码: tar -zxvf Python-3.7.0.tg ...
- 【selenium】Selenium基于Python3的Web自动化测试脚本在IE上运行慢的解决方法
阐述问题: 执行自动化脚本时,发现文本输入在IE浏览器上特别慢,这样大大降低了自动化效率 解决办法:原因是原先下载的IEDriverServer.exe为64位系统的IE,换为32位的IEDriver ...
随机推荐
- TensorFlow 基本概念
一.概述 使用图(graph)来表示计算任务 在会话(Session)的上下文(context)中执行图(graph) 使用tensor表示数据 通过 变量(Variable)维护状态 使用 feed ...
- 使用itext直接替换PDF中的文本
直接说问题,itext没有直接提供替换PDF中文本的接口(查看资料得到的结论是PDF不支持这种操作),不过存在解决思路:在需要替换的文本上覆盖新的文本.按照这个思路我们需要解决以下几个问题: itex ...
- Linux/Unix 新手和专家教程
你正在找一些高质量的Linux 和 UNIX 的教程吗?如果是,这篇文章会告诉你到哪去找到这些教程.这里我们将给出超过30个相当的不错的 Linux 和 UNIX 在线的教程. 需要大家注意的是,他们 ...
- Canvas文本操作
Canvas的画图环境提供三个方法如:绘制填充文本:fillText();绘制描边文本:strokeText();绘制文本并返回一个对象:measure();measure()方法返回的对象中包括一个 ...
- vc2010 属性值无效 灾难性故障 解决方法
原文链接: http://blog.csdn.net/enterlly/article/details/8739281 说明: 我遇到这个问题是这样的,在为某个类添加消息时出现的.因为该类不在此工程的 ...
- Facade 设计模式
目的 在一个子系统的一组接口上提供一个统一的接口.Facade 设计模式定义了一个更高级别的接口,使子系统更容易使用. 通过一个更加简洁的接口来包装一个复杂的子系统. 解决的问题 客户端需要一个简化的 ...
- android中碰撞屏幕边界反弹问题
其实碰撞问题只是涉及到一点小算法而已,但在实际应用,尤其游戏中有可能会遇到,下面给出一个小示例,代码如下: MainActivity: package com.lovo; import android ...
- nginx 443 https mark
#user nobody; worker_processes 4; #error_log logs/error.log; #error_log logs/error.log notice; ...
- iphone5刷机教程
如果不想麻烦可以在越狱之后添加源,cydia.china3gpp.com打ios7的补丁就可以了 机器为iphone5 美国sprint有锁版 1. 首先备份需要的程序和数据(把各种缓存的影片删掉再备 ...
- Scala语言开发入门
在本系列的第一篇文章 <使用递归的方式去思考>中,作者并没有首先介绍 Scala 的语法,这样做有两个原因:一是由于过多的陷入语法的细节其中,会分散读者的注意力.反而忽略了对于基本概念,基 ...