Spark学习笔记--Linux安装Spark集群详解
本文主要讲解如何在Linux环境下安装Spark集群,安装之前我们需要Linux已经安装了JDK和Scala,因为Spark集群依赖这些。下面就如何安装Spark进行讲解说明。
一、安装环境
操作系统:Red Hat Enterprise Linux 6 64 位(版本号6.6)
JDK版本:1.8
Scala版本:2.12.2
Spark版本:2.2.0
172.18.3.135 主节点
172.18.3.136 从节点
172.18.3.137 从节点
之后的操作如果是用普通用户操作的话也必须知道root用户的密码,因为有些操作是得用root用户操作。如果是用root用户操作的话就不存在以上问题。我是用root用户操作的。
说明:本文是通过Xshell5工具远程连接Linux操作,如果是直接在Linux可视化界面操作那就更方便了,原理一样。
二、修改hosts文件(前期准备工作)
修改三台服务器的hosts文件。
vi /etc/hosts
在原文件的基础最后面加上:
172.18.3.135 Master
172.18.3.136 Slave1
172.18.3.137 Slave2
修改完成后保存执行如下命令。
source /etc/hosts
三、配置ssh无密码验证(前期准备工作)
为什么需要ssh无密码验证呢,是为了确保主从机无需密码就能进行通信访问
可以参考笔者的另一篇文章《Ubuntu下SSH无密码验证配置》,这里我只文字阐述下。
3.1安装和启动ssh协议
我们需要两个服务:ssh和rsync。
可以通过下面命令查看是否已经安装:
rpm -qa|grep openssh
rpm -qa|grep rsync
如果没有安装ssh和rsync,可以通过下面命令进行安装:
yum install ssh (安装ssh协议) yum install rsync (rsync是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件) service sshd restart (启动服务)
3.2 配置Master无密码登录所有Salve
配置Master节点,以下是在Master节点的配置操作
1)在Master节点上生成密码对,在Master节点上执行以下命令:
ssh-keygen -t rsa -P ''
生成的密钥对:id_rsa和id_rsa.pub,默认存储在"/root/.ssh"目录下。
2)接着在Master节点上做如下配置,把id_rsa.pub追加到授权的key里面去。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3)修改ssh配置文件"/etc/ssh/sshd_config"的下列内容,将以下内容的注释去掉:
RSAAuthentication yes # 启用 RSA 认证 PubkeyAuthentication yes # 启用公钥私钥配对认证方式 AuthorizedKeysFile .ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)
4)重启ssh服务,才能使刚才设置有效。
service sshd restart
5)验证无密码登录本机是否成功。
ssh localhost
6)接下来的就是把公钥复制到所有的Slave机器上。使用下面的命令进行复制公钥:
scp /root/.ssh/id_rsa.pub root@Slave1:/root/ scp /root/.ssh/id_rsa.pub root@Slave2:/root/
接着配置Slave节点,以下是在Slave1节点的配置操作。
1)在"/root/"下创建".ssh"文件夹,如果已经存在就不需要创建了。
mkdir /root/.ssh
2)将Master的公钥追加到Slave1的授权文件"authorized_keys"中去。
cat /root/id_rsa.pub >> /root/.ssh/authorized_keys
3)修改"/etc/ssh/sshd_config",具体步骤参考前面Master设置的第3步和第4步。
4)用Master使用ssh无密码登录Slave1
ssh 172.18.3.135
5)把"/root/"目录下的"id_rsa.pub"文件删除掉。
rm –r /root/id_rsa.pub
重复上面的5个步骤把Slave2服务器进行相同的配置。
3.3 配置所有Slave无密码登录Master
以下是在Slave1节点的配置操作。
1)创建"Slave1"自己的公钥和私钥,并把自己的公钥追加到"authorized_keys"文件中,执行下面命令:
ssh-keygen -t rsa -P '' cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
2)将Slave1节点的公钥"id_rsa.pub"复制到Master节点的"/root/"目录下。
scp /root/.ssh/id_rsa.pub root@Master:/root/
以下是在Master节点的配置操作。
1)将Slave1的公钥追加到Master的授权文件"authorized_keys"中去。
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
2)删除Slave1复制过来的"id_rsa.pub"文件。
rm –r /root/id_rsa.pub
配置完成后测试从Slave1到Master无密码登录。
ssh 114.55.246.88
按照上面的步骤把Slave2和Master之间建立起无密码登录。这样,Master能无密码验证登录每个Slave,每个Slave也能无密码验证登录到Master。
四、安装JDK
JDK的安装我们这就不做讲解,请参考笔者另一篇文章《Linux 下安装JDK1.8》
五、安装Scala
因为Spark依赖scala,所以在安装Spark之前,这里要先安装scala。在每个节点上都需要进行安装。
5.1、下载和解压Scala
我们从官网:http://www.scala-lang.org/ 下载Scala,最新的版本为2.12.2,如图所示

我们直接下载https://downloads.lightbend.com/scala/2.12.2/scala-2.12.2.tgz

我们在Linux服务器的opt目录下新建一个Scala的文件夹(这个根据自己自定义新建文件夹,没有要求),通过xftp5将压缩包上传到这个目录当中,如图所示

进入到该目录下,执行解压命令:
$ cd /home/cmfchina/opt/scala
$ tar -zxvf scala-2.12..tgz
如图所示:

5.2、配置Scala环境变量
通过命令编辑/etc/profile这个文件
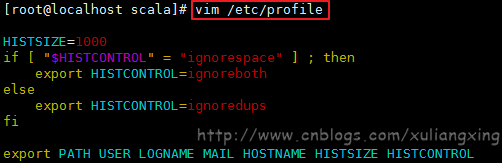
vim /etc/profile //备注vim编辑器按“i”是进行插入操作
如果所示:
在文件中增加一行配置:
export SCALA_HOME=/home/cmfchina/opt/scala/scala-2.12.
在该文件的PATH变量中增加下面的内容(没有PATH就新建一个export):
${SCALA_HOME}/bin
如图所示:

说明:你可以只关注开头说的JDK SCALA Spark的环境变量,其余的都不用管,那是其他程序的环境变量配置。
然后,保存并退出(按:wq!)
保存完之后,我们还需要让这个环境变量配置信息里面生效,要不然只能重启电脑生效了。
通过命令source /etc/profile让profile文件立即生效
source /etc/profile
如图所示

5.3、验证Scala
通过命令查看Scala版本信息
scala -version
如图所示:

说明Scala已经安装成功了。
六、安装Spark
6.1、下载Spark压缩包
我们到Spark官网进行下载:http://spark.apache.org/ ,我们选择带有Hadoop版本的Spark,如图所示:

下载后得到了大约200M的文件: spark-2.2.0-bin-hadoop2.7
6.2、解压Spark
下载完成后,在Linux服务器的opt目录下新建一个名为spark的文件夹,把刚才下载的Spark压缩包,上传上去,和前面的Scala讲解的一样。
如图所示:
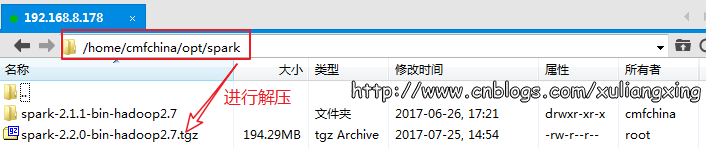
进入到该目录下,执行解压命令:
cd /home/cmfchina/opt/spark
tar -zxvf spark-2.2.-bin-hadoop2..tgz
如图所示:

七、Spark相关配置设置
说明:因为我们搭建的是基于hadoop集群的Spark集群,所以每个hadoop节点上我都安装了Spark,都需要按照下面的步骤做配置,启动的话只需要在Spark集群的Master机器上启动即可
7.1、Spark环境变量配置
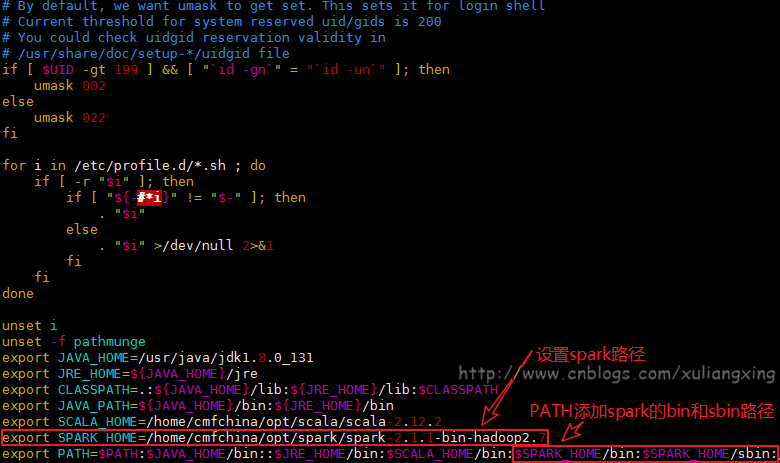
编辑/etc/profile文件(和前面讲的Scala一样),增加下面一行
export SPARK_HOME=/home/cmfchina/opt/spark/spark-2.1.-bin-hadoop2.
该文件中的PATH变量,添加下面两行
${SPARK_HOME}/bin和${SPARK_HOME}/sbin
如图所示:
保存并退出(按:wq!),通过命令source /etc/profile让profile文件立即生效
7.2、配置Spark的conf目录文件
7.2.1、配置spark-env.sh文件
对/opt/spark/spark-2.1.1-bin-hadoop2.7/conf目录下的文件进行配置。
以spark为我们创建好的模板创建一个spark-env.h文件,命令是:
cd /home/cmfchina/opt/spark/spark-2.1.-bin-hadoop2./conf
cp spark-env.sh.template spark-env.sh //备注spark-env.sh.template是spark的一个自带模板
如图所示:

执行上面命令,我们会发现conf目录下就会新建了spark-env.sh文件,编辑spark-env.h文件,在里面加入配置(配置的具体路径以自己的为准):
export JAVA_HOME=/usr/java/jdk1..0_131 //JDK安装路径
export SCALA_HOME=/home/cmfchina/opt/scala/scala-2.12. //SCALA安装路径
export SPARK_HOME=/home/cmfchina/spark/spark-2.1.-bin-hadoop2. //spark安装路径
export HADOOP_CONF_DIR=/home/cmfchina/opt/spark/spark-2.1.-bin-hadoop2./conf //指定hadoop的配置文件目录
export SPARK_LOG_DIR=/home/cmfchina/opt/spark/spark-2.1.-bin-hadoop2./logs
export SPARK_PID_DIR=/home/cmfchina/opt/spark/spark-2.1.-bin-hadoop2./pid
export SPARK_MASTER_IP=172.18.3.135 //主节点的IP地址
export SPARK_MASTER_HOST=172.18.3.135
export SPARK_LOCAL_IP=172.18.3.135 //本机的IP地址
export SPARK_WORKER_MEMORY=2G //分配的内存大小,作业可使用的内存容量,默认格式1000M 或者 2G,注意内存设置必须是整数
export MASTER=spark://172.18.3.135:7077 //默认端口为7077

具体spark-env.sh设置可以参考网上其他文献,这里设置完保存关闭就行了。
7.2.1、配置slaves文件(Master配置这个Salve文件就行,其他Slave机不需要配置)
执行命令,进入到/opt/spark/spark-2.1.1-bin-hadoop2.7/conf目录内,以spark为我们创建好的模板创建一个slaves文件,命令是:
cd /home/cmfchina/opt/spark/spark-2.1.-bin-hadoop2./conf
cp slaves.template slaves
slaves这个文件是指定子节点的主机,将slaves内的localhost删去,直接添加master主机名和子节点主机名即可
//这些是masterIP和其他Salve的IP地址
//因为我们配置了host,也可以直接用master和slave1,slave2进行配置,不需要IP地址 master的IP //例如 xx.xx.xx.xx(172.18.3.135)
slave1的IP1 //例如 172.18.3.
slave2的IP2 //例如 172.18.3. //即master 既是 Master 节点又是 Worker 节点。如果只有一个master的,没有其他slave,那这个就是我们常说的伪分布(单机点)

到此为止,前面所有的安装配置动作,在你的另一个机器上(所有的slave机器)同样的做一遍
备注:其他的Slave机不需要配置slave文件,只需要配置spark-env.sh就行,将export SPARK_LOCAL_IP=172.18.3.135改成Slave1和Slave2对应节点的IP,其他基本不变。
八、启动Spark集群
8.1、运行sbin/start-all.sh(Master和Slave都启动要启动,如果想要关闭,使用命令stop-all.sh)
进入spark-2.1.1-bin-hadoop2.7/sbin/目录
执行:./start-all.sh
如果没有设置ssh免密码登陆,会要求输入密码,这时候jps查看多了个master和worker,如图所示:

8.2、运行spark-shell(Master和Slave都启动要启动)
在bin目录下执行:
./spark-shell
这时候就可以看到运行的Spark了,如图所示:
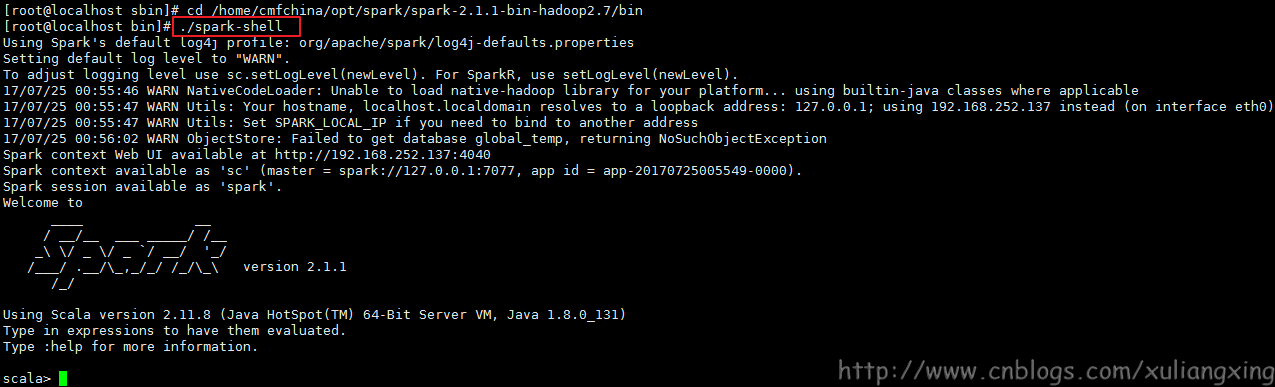
追加说明:start-all.sh和spark-shell启动如果显示以上界面,说明是成功的,如果出现报错或者Waring的话,则需要查看配置是否正确(很多时候会有莫名其妙的错误)
8.3、浏览器查看集群信息(master地址+8080端口)
在浏览器里访问Mster机器,我的生产环境的Spark集群里Master的IP地址是192.168.226.129(本机测试,根据实际情况而定),访问8080端口
如图所示:

PS:如有问题,请留言,未经允许不得私自转载,转载请注明出处:http://www.cnblogs.com/xuliangxing/p/7234014.html


Spark学习笔记--Linux安装Spark集群详解的更多相关文章
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Linux防火墙iptables学习笔记(三)iptables命令详解和举例[转载]
Linux防火墙iptables学习笔记(三)iptables命令详解和举例 2008-10-16 23:45:46 转载 网上看到这个配置讲解得还比较易懂,就转过来了,大家一起看下,希望对您工作能 ...
- (转)live555学习笔记10-h264 RTP传输详解(2)
参考: 1,live555学习笔记10-h264 RTP传输详解(2) http://blog.csdn.net/niu_gao/article/details/6936108 2,H264 sps ...
- Spark学习笔记5:Spark集群架构
Spark的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展计算能力.Spark可以在各种各样的集群管理器(Hadoop YARN , Apache Mesos , 还有Spark自带的独立 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:安装zookeeper集群
实验目的 了解zookeeper的概念和原理 学会安装zookeeper集群并验证 掌握zookeeper命令使用 实验原理 1.Zookeeper介绍 ZooKeeper是一个分布式的,开放源码的分 ...
- spark学习7(spark2.0集群搭建)
第一步:安装spark 将官网下载好的spark-2.0.0-bin-hadoop2.6.tgz上传到/usr/spark目录下.这里需注意的是spark和hadoop有对应版本关系 [root@sp ...
- spark学习4(zookeeper3.4集群搭建)
第一步:zookeeper安装 通过WinSCP软件将zookeeper-3.4.8.tar.gz软件传送到/usr/zookeeper/目录下 [root@spark1 zookeeper]# ch ...
- 王雅超的学习笔记-大数据hadoop集群部署(十)
Spark集群安装部署
- DOCKER 学习笔记8 Docker Swarm 集群搭建
前言 在前面的文章中,已经介绍如何在本地通过Docker Machine 创建虚拟Docker 主机,以及也可以在本地Windows 创建虚拟主机,也是可以使用的.这一节,我们将继续学习 Docker ...
随机推荐
- C# 中base和this关键字
base: 用于在派生类中实现对基类公有或者受保护成员的访问,但是只局限在构造函数.实例方法和实例属性访问器中. MSDN中小结的具体功能包括: ()调用基类上已被其他方法重写的方法. ()指定创建派 ...
- 精挑细选 8款HTML5/jQuery应用助网站走向高上大
在WEB3.0的时代,我们的网站不仅要实现实用价值,更要为用户设计优秀的用户体验.jQuery是一个不错的JS框架,结合目前最新的HTML5技术,我们可以将自己的网站脱胎换骨,立马走向高上大,至少在前 ...
- Windows7下安装cpu版的Tensorflow
windows7下安装python3.5 1.下载python-3.5.2-amd64.whl https://www.python.org/downloads/release/python-352/ ...
- u3d外部资源 打包与加载的问题
被坑了一下午,调bug,u3d外部加载资源一会可以,一会不行,始终找不到问题,最后快下班的时候,重新试了一下,原来是资源打包之前的文件名,和之后的加载资源名必须一样 [MenuItem("C ...
- CocoaPods:说点关于它的
CocoaPods安装和使用教程 安装及使用方法,这里有现成的,很细致,不再赘述(发音:zhuìshù,敲半天ao'shu,找不到这个词 =.=) 记录一下遇到的问题 1.CocoaPods 版本 ...
- Throwable vs Exception
Throwable中的Error是不需要程序处理的. Exception是需要处理的.
- hive 配置元数据以mysql 存储
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="confi ...
- Android四大组件之——ContentProvider(二)
Content Resolver介绍: 开发者文档中这么定义的: This class provides applications access to the content model. 这个类为应 ...
- SQL2005数据库置疑处理
2005中遇到置疑.丢失日志时按照网上常见的MSSQL2000修复方法来做, 结果发现行不通,甚至连一步都做不下去.其实,在MSSQL2005在处理置疑问题的思 路与MSSQL2000是一致的,但具体 ...
- hive 表优化
一.外部表和内部表的区别 (1)创建表时指定external关键字,就是外部表,不指定external就是内部表 (2)内部表删除后把元数据和数据都删除了,外部表删除后只是删除了元数据,不会删除hdf ...