Disruptor分布式id生成策略


需要的pom文件:
<!-- 顺序UUID -->
<dependency>
<groupId>com.fasterxml.uuid</groupId>
<artifactId>java-uuid-generator</artifactId>
<version>3.1.4</version>
</dependency>
有时间顺序:
import com.fasterxml.uuid.EthernetAddress;
import com.fasterxml.uuid.Generators;
import com.fasterxml.uuid.impl.TimeBasedGenerator; public class KeyUtil { public static String generatorUUID(){
TimeBasedGenerator timeBasedGenerator = Generators.timeBasedGenerator(EthernetAddress.fromInterface());
return timeBasedGenerator.generate().toString();
} public static void main(String[] args) {
System.err.println(KeyUtil.generatorUUID());
System.err.println(KeyUtil.generatorUUID());
}
}













以下两种方式都不合适:


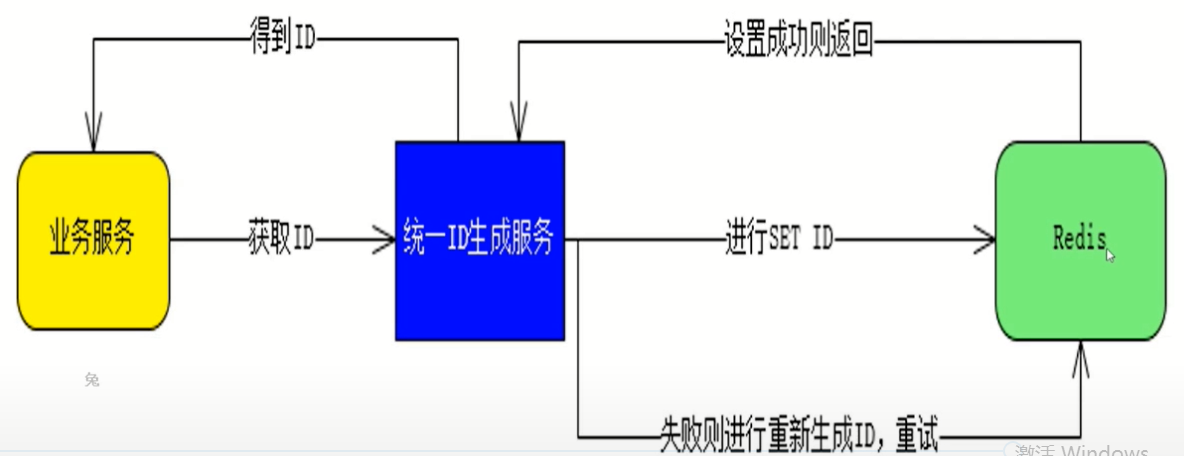














分布式生成ID架构图:
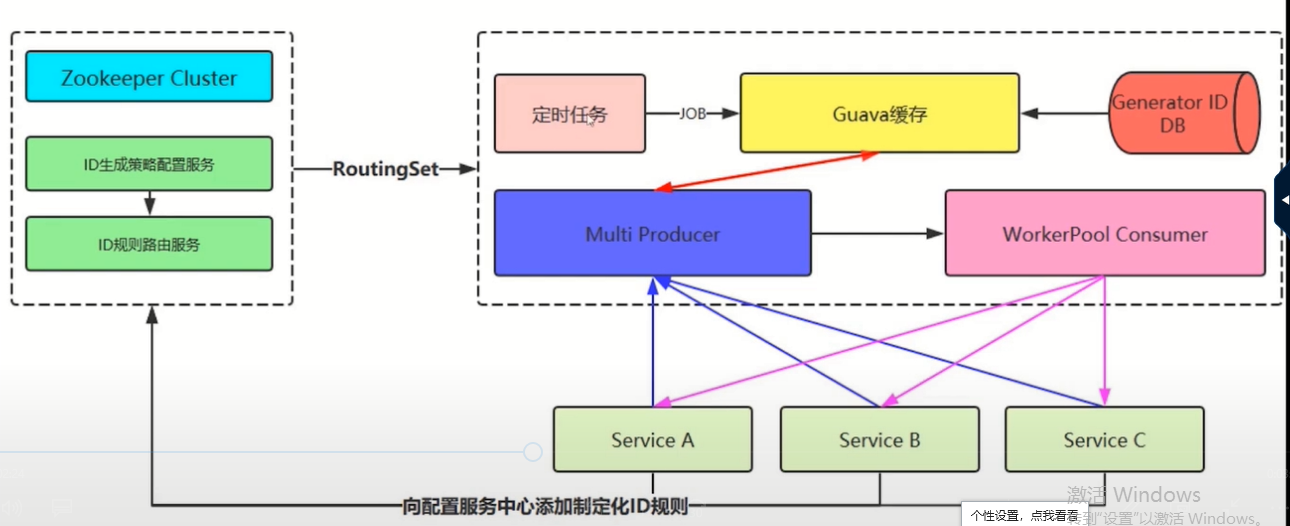
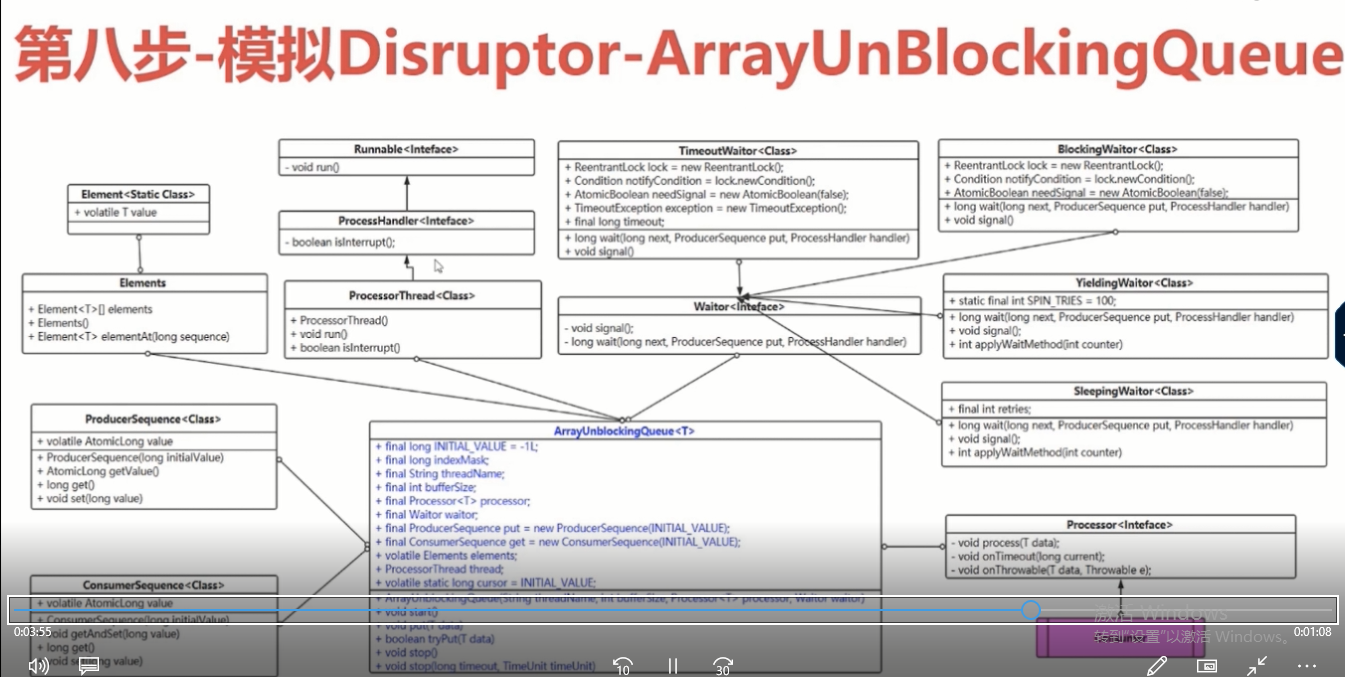
Disruptor分布式id生成策略的更多相关文章
- 分布式ID生成策略 · fossi
分布式环境下如何保证ID的不重复呢?一般我们可能会想到用UUID来实现嘛.但是UUID一般可以获取当前时间的毫秒数再加点随机数,但是在高并发下仍然可能重复.最重要的是,如果我要用这种UUID来生成分表 ...
- 图解Janusgraph系列-分布式id生成策略分析
JanusGraph - 分布式id的生成策略 大家好,我是洋仔,JanusGraph图解系列文章,实时更新~ 本次更新时间:2020-9-1 文章为作者跟踪源码和查看官方文档整理,如有任何问题,请联 ...
- 分布式ID生成策略之ZK
import org.apache.curator.framework.CuratorFramework; import org.apache.curator.framework.CuratorFra ...
- 分布式ID生成策略
策略一.UUID 策略二.数据库自增序列 策略三.snowflake算法 策略四.基于redis自增 思路:利用增长计数API,业务系统在自增长的基础上,配合其他信息组装成为一个唯一ID. redis ...
- 业务ID 生成策略
业务ID 生成策略,从技术上说,基本要借助一个集中式的引擎来帮忙实现. 为了扩大业务ID生成策略的并发问题,还有更为技巧性的提升. 先来介绍普遍的分布式ID生成策略: 1. 利用DB的自增主键 这里又 ...
- 数据库分库分表(一)常见分布式主键ID生成策略
主键生成策略 系统唯一ID是我们在设计一个系统的时候常常会遇见的问题,下面介绍一些常见的ID生成策略. Sequence ID UUID GUID COMB Snowflake 最开始的自增ID为了实 ...
- 常见分布式全局唯一ID生成策略
全局唯一的 ID 几乎是所有系统都会遇到的刚需.这个 id 在搜索, 存储数据, 加快检索速度 等等很多方面都有着重要的意义.工业上有多种策略来获取这个全局唯一的id,针对常见的几种场景,我在这里进行 ...
- 架构设计 | 分布式业务系统中,全局ID生成策略
本文源码:GitHub·点这里 || GitEE·点这里 一.全局ID简介 在实际的开发中,几乎所有的业务场景产生的数据,都需要一个唯一ID作为核心标识,用来流程化管理.比如常见的: 订单:order ...
- 常见分布式唯一ID生成策略
方法一: 用数据库的 auto_increment 来生成 优点: 此方法使用数据库原有的功能,所以相对简单 能够保证唯一性 能够保证递增性 id 之间的步长是固定且可自定义的 缺点: 可用性难以保证 ...
随机推荐
- JS和JQuery实现Button绑定键盘Enter事件实现提交
JavaScript实现方法 document.onkeydown = function(e) { if (!e) e = window.event;//火狐中是 window.event if (( ...
- Web前端开发规范之文件存储位置规范
文件存放位置规范 1 文件夹说明 flash存放flash文件 p_w_picpaths存放图片文件 inc存放include文件 library存放DW库文件 media存放多媒体文件 scri ...
- 创业小记:ALL IN才是迈出创业第一步的关键
对于创业而言,能卖出这创业第一步的,大多都经过了长期反复的心理拷问与折磨. 因为当你迈出创业的那一步,你可能需要面对的是毫无收入保障的生活,以及后果自负的结局. ALL IN才是迈出创业第一步的关键( ...
- NGINX心跳检测
NGINX心跳检测 upstream springboot { server 10.3.73.223:8080 max_fails=2 fail_timeout=30s; server 10.3.73 ...
- Python面向对象编程核心思想
原文地址https://blog.csdn.net/weixin_42134789/article/details/80194788 https://blog.csdn.net/happyjxt/ar ...
- [转]vscode 插件推荐 - 献给所有前端工程师(2019.8.7更新)
原文地址:https://segmentfault.com/a/1190000006697219 VScode现在已经越来越完善.性能远超Atom和webstorm,你有什么理由不用它?在这里,我会给 ...
- Android Studio打包没有Generate signed apk选项 解决方法
原文地址:https://www.jianshu.com/p/9e02e55f0ba8 1.点击build栏目-并没有Generate signed apk选项 2.点击file,选中如下图所示Syn ...
- jquery click 与原生 click 的区别
$.click() 触发的事件中没有 event.originalEvent , 不同触发 href="" 中的内容 $[0].click() 可以 <script type ...
- python初级(302) 3 easygui简单使用二
一.复习 1.easygui 信息提示对话框 2.easygui 是否对话框 二.easygui其它组件 1.选择对话框:choicebox(msg, title, choices) import e ...
- 利用Flex&b 开发一门语言
https://blog.csdn.net/CrazyHeroZK/article/details/87359818