分布式ID生成策略 · fossi
分布式环境下如何保证ID的不重复呢?一般我们可能会想到用UUID来实现嘛。但是UUID一般可以获取当前时间的毫秒数再加点随机数,但是在高并发下仍然可能重复。最重要的是,如果我要用这种UUID来生成分表的唯一ID的话,重复不谈,这种随机的字符串对于我们的innodb存储引擎的插入效率是很低的。所以我们生成的ID如果作为主键,最好有两种特性:分布式唯一和有序。
唯一性就不用说了,有序保证了对索引字段的插入的高效性。我们来具体看看ShardingJDBC的分布式ID生成策略是如何保证。
snowflake算法

sharding-jdbc的分布式ID采用twitter开源的snowflake算法,不需要依赖任何第三方组件,这样其扩展性和维护性得到最大的简化;但是snowflake算法的缺陷(强依赖时间,如果时钟回拨,就会生成重复的ID)。
雪花算法是由Twitter公布的分布式主键生成算法,它能够保证不同进程主键的不重复性,以及相同进程主键的有序性。
在同一个进程中,它首先是通过时间位保证不重复,如果时间相同则是通过序列位保证。 同时由于时间位是单调递增的,且各个服务器如果大体做了时间同步,那么生成的主键在分布式环境可以认为是总体有序的,这就保证了对索引字段的插入的高效性。例如MySQL的Innodb存储引擎的主键。
使用雪花算法生成的主键,二进制表示形式包含4部分,从高位到低位分表为:1bit符号位、41bit时间戳位、10bit工作进程位以及12bit序列号位。
雪花算法主键的详细结构见下图。
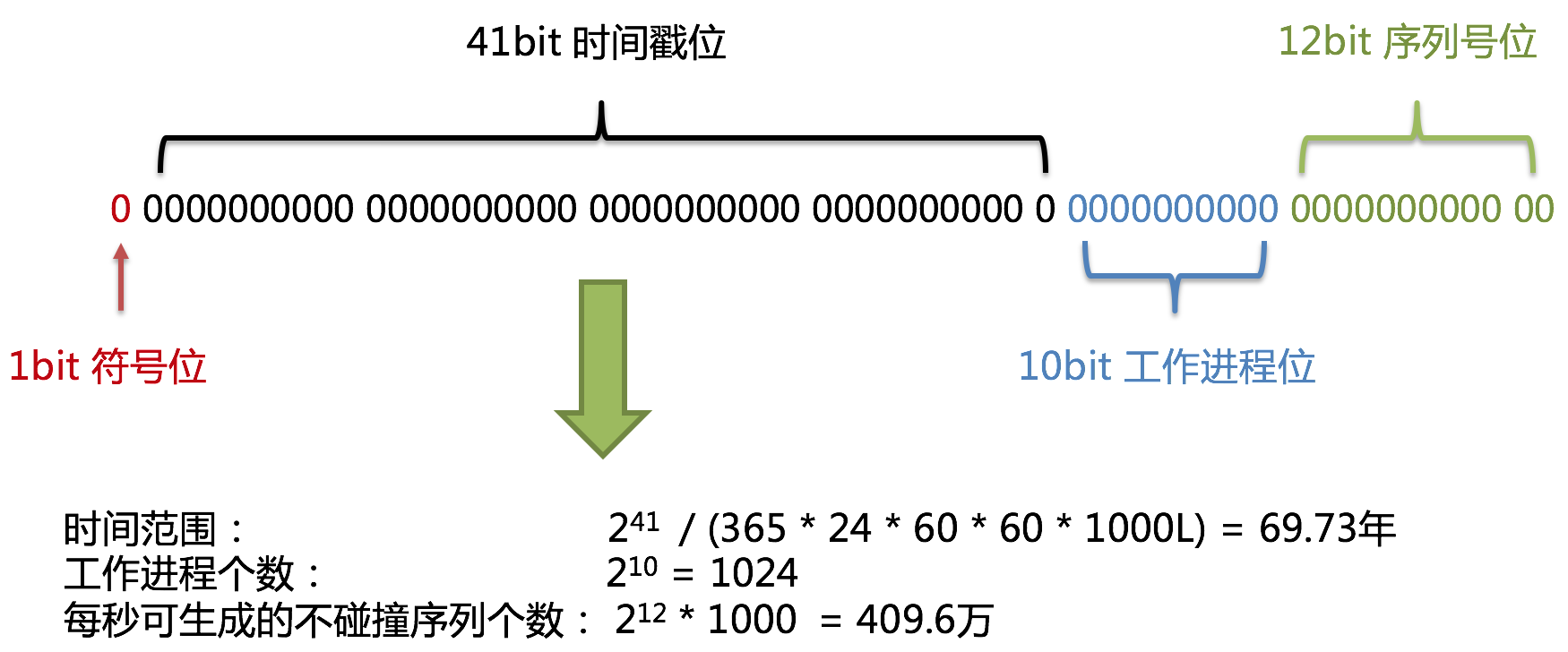
- 符号位(1bit)
预留的符号位,恒为零。
- 时间戳位(41bit)
41位的时间戳可以容纳的毫秒数是2的41次幂,一年所使用的毫秒数是:365 * 24 * 60 * 60 * 1000。通过计算可知:
1 |
Math.pow(2, 41) / (365 * 24 * 60 * 60 * 1000L); |
结果约等于69.73年。ShardingSphere的雪花算法的时间纪元从2016年11月1日零点开始,可以使用到2086年,相信能满足绝大部分系统的要求。
- 工作进程位(10bit)
该标志在Java进程内是唯一的,如果是分布式应用部署应保证每个工作进程的id是不同的。该值默认为0,可通过调用静态方法DefaultKeyGenerator.setWorkerId()设置。
- 序列号位(12bit)
该序列是用来在同一个毫秒内生成不同的ID。如果在这个毫秒内生成的数量超过4096(2的12次幂),那么生成器会等待到下个毫秒继续生成。
时钟回拨
服务器时钟回拨会导致产生重复序列,因此默认分布式主键生成器提供了一个最大容忍的时钟回拨毫秒数。 如果时钟回拨的时间超过最大容忍的毫秒数阈值,则程序报错;如果在可容忍的范围内,默认分布式主键生成器会等待时钟同步到最后一次主键生成的时间后再继续工作。 最大容忍的时钟回拨毫秒数的默认值为0,可通过调用静态方法DefaultKeyGenerator.setMaxTolerateTimeDifferenceMilliseconds()设置。
分布式ID生成策略 · fossi的更多相关文章
- 图解Janusgraph系列-分布式id生成策略分析
JanusGraph - 分布式id的生成策略 大家好,我是洋仔,JanusGraph图解系列文章,实时更新~ 本次更新时间:2020-9-1 文章为作者跟踪源码和查看官方文档整理,如有任何问题,请联 ...
- 分布式ID生成策略之ZK
import org.apache.curator.framework.CuratorFramework; import org.apache.curator.framework.CuratorFra ...
- Disruptor分布式id生成策略
需要的pom文件: <!-- 顺序UUID --> <dependency> <groupId>com.fasterxml.uuid</groupId> ...
- 分布式ID生成策略
策略一.UUID 策略二.数据库自增序列 策略三.snowflake算法 策略四.基于redis自增 思路:利用增长计数API,业务系统在自增长的基础上,配合其他信息组装成为一个唯一ID. redis ...
- 业务ID 生成策略
业务ID 生成策略,从技术上说,基本要借助一个集中式的引擎来帮忙实现. 为了扩大业务ID生成策略的并发问题,还有更为技巧性的提升. 先来介绍普遍的分布式ID生成策略: 1. 利用DB的自增主键 这里又 ...
- 数据库分库分表(一)常见分布式主键ID生成策略
主键生成策略 系统唯一ID是我们在设计一个系统的时候常常会遇见的问题,下面介绍一些常见的ID生成策略. Sequence ID UUID GUID COMB Snowflake 最开始的自增ID为了实 ...
- 常见分布式全局唯一ID生成策略
全局唯一的 ID 几乎是所有系统都会遇到的刚需.这个 id 在搜索, 存储数据, 加快检索速度 等等很多方面都有着重要的意义.工业上有多种策略来获取这个全局唯一的id,针对常见的几种场景,我在这里进行 ...
- 架构设计 | 分布式业务系统中,全局ID生成策略
本文源码:GitHub·点这里 || GitEE·点这里 一.全局ID简介 在实际的开发中,几乎所有的业务场景产生的数据,都需要一个唯一ID作为核心标识,用来流程化管理.比如常见的: 订单:order ...
- 常见分布式唯一ID生成策略
方法一: 用数据库的 auto_increment 来生成 优点: 此方法使用数据库原有的功能,所以相对简单 能够保证唯一性 能够保证递增性 id 之间的步长是固定且可自定义的 缺点: 可用性难以保证 ...
随机推荐
- Python 爬取腾讯招聘职位详情 2019/12/4有效
我爬取的是Python相关职位,先po上代码,(PS:本人小白,这是跟着B站教学视频学习后,老师留的作业,因为腾讯招聘的网站变动比较大,老师的代码已经无法运行,所以po上),一些想法和过程在后面. f ...
- Codeforces Round #624 (Div. 3)(题解)
A. Add Odd or Subtract Even 思路: 相同直接为0,如果两数相差为偶数就为2,奇数就为1 #include<iostream> #include<algor ...
- LeetCode——199. 二叉树的右视图
给定一棵二叉树,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值. 示例: 输入: [1,2,3,null,5,null,4] 输出: [1, 3, 4] 解释: 1 < ...
- 关于volatile关键字
来源:衡阳网站优化 在java核心卷1中对volatile关键字是这么描述的: volatile关键字为实例域的同步访问提供了一种免锁机制.如果声明一个域为volatile,那么编译器和虚拟机就知道该 ...
- 关于目录的操作|*|<>|opendir |readdir|unlink|find2perl|rename|readlink|oct()|utime
#!/usr/bin/perl use strict; use warnings; foreach my $arg(@ARGV) { print "one is $arg\n"; ...
- ZJNU 1133 - Subset sequence——中级
推出n=1到4时,An排列的种类数分别为1 4 15 64可得(1+1)*2=4(4+1)*3=15(15+1)*4=64...故用一数列r[n]记录An的种类总数当n=3时,列举出以下15种从大到小 ...
- 许家印67亿买下FF恒大是要雪中送炭吗?
从大环境来看,当下新能源汽车已经是备受投资者青睐的领域.据不完全统计,当下国内已经有300余家电动汽车企业.而蔚来.小鹏.威马等动辄都融资上百亿元,显现出火爆的发展趋势.甚至就连董明珠董大姐也有着自己 ...
- flash插件的安装——网页视频无法播放
1.从官网下载Adobe flash player 安装包.官方网址:https://get.adobe.com/cn/flashplayer/ 或者从我的网盘下载:链接:https://pan.ba ...
- 求Fibonacii数列的第40个数
public class Fibonacii{ public int m1(int n){ if(n == 1||n == 2){ return 1; } return m1(n-1) + m1(n- ...
- element ui 自定义异步验证
之前提到过,axios是一个异步请求,但是很多时候我们都需要同步请求,比如在element的表单验证中需要验证一个用户名是否存在的时候,异步请求好像就不太好用了.前边博客中提到过,这种情况可以用es6 ...