聚类和EM算法——K均值聚类
python大战机器学习——聚类和EM算法
注:本文中涉及到的公式一律省略(公式不好敲出来),若想了解公式的具体实现,请参考原著。
1、基本概念
(1)聚类的思想:
将数据集划分为若干个不想交的子集(称为一个簇cluster),每个簇潜在地对应于某一个概念。但是每个簇所具有现实意义由使用者自己决定,聚类算法仅仅会进行划分。
(2)聚类的作用:
1)可以作为一个单独的过程,用于寻找数据的一个分布规律
2)作为分类的预处理过程。首先对分类数据进行聚类处理,然后在聚类结果的每一个簇上执行分类过程。
(3)聚类的性能度量:
1)外部指标:该指标是由聚类结果与某个参考模型进行比较而获得的。这些外部指标性能度量的结果都在[0,1]之间,这些值越大,说明聚类的性能越好。
Jaccard系数:它刻画了所有属于同一类的样本对同时在C和C*中隶属于同一类的样本对的概率 JC=a/(a+b+c)
FM指数:它刻画了在C中属于同一类的样本对中,同时属于C*的样本对的比例为p1;在C*中属于同一类的样本对中,同时属于C的样本对比例为p2,FMI 就是p1和p2的几何平均 FMI=sqrt((a/(a+b))*(a/(a+c)))
Rand指数:它刻画的是同时隶属于C,C*的样本对于既不隶属于C,又不隶属于C*的样本对之和占所有样本对的比例 RI=2*(a+d)/(N*(N-1))
ARI指数:对于随机聚类,RI指数不保证接近0。而ARI指数就可通过利用个随机聚类情况下的RI(即E[RI])来解决这个问题。
2)内部指标:该指标直接由考察聚类结果而得到的,并不利用任何参考模型
DB指数:它刻画的是,给定两个簇,每个簇样本之间平均值之和比上两个簇的中心点之间的距离作为作为度量。然后考察该度量对所有簇的平均值。显 然DBI越小越好。如果每个簇样本之间的平均值越小(即簇内样本距离都很近),则DBI越小;如果簇间中心点的距离越大(即簇间样本距离相互越远),则 DBI越小
Dunn指数:它刻画的是任意两个簇之间最近的距离的最小值,除以任意一个簇内距离最远的两个点的距离的最大值。DI越大越好。
(4)距离度量:
1)闵可夫斯基距离
2)VDM距离:它刻画的是属性取值在各簇上的频率分布之间的差异(当属性取值为非数值类时)
通过高斯分布,随机生成聚类簇的样本数据,代码如下:
结果如下:

2、k均值算法
输入:样本集D,聚类簇数K
输出:簇划分C
算法步骤:
1)从D中随机选择K个样本作为初始簇均值向量u
2)重复迭代直到算法收敛(迭代内容参考书中内容)
注:K均值算法总能够收敛,但是其收敛情况高度依赖于初始化的均值,有可能收敛到局部极小值。因此通常都是用多组初始均值向量来计算若干次,选择其中最优的一次。而k-means++策略选择的初始均值向量可以在一定程度上解决这个问题。
实验代码一:
实验结果一:
其中ARI指标越大越好

实验代码二:
实验结果二:
该结果显示了聚类簇的数目对ARI和inertial_的影响
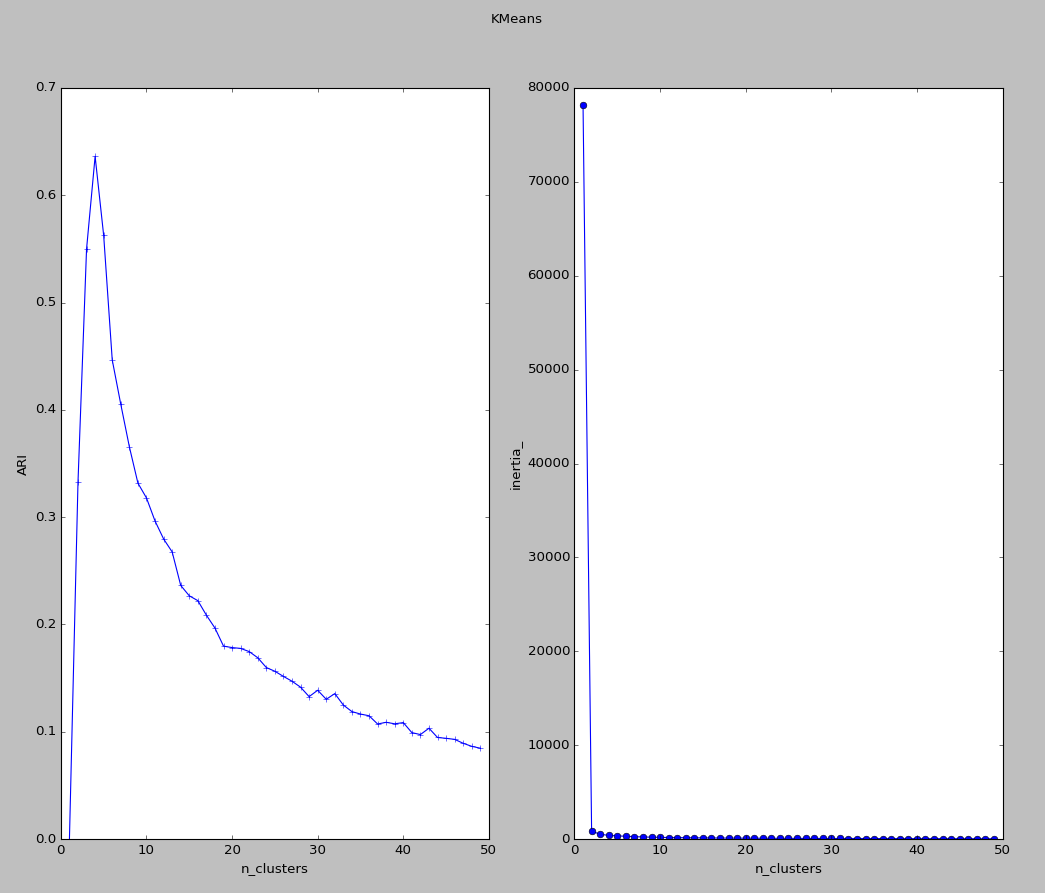
3、高斯混合聚类
其通过概率模型来表示聚类原型。若已知高斯混合分布,则高斯混合聚类的原理是:如果样本xi最优可能是Z=k产生的,则可将该样本划归到簇Ck。即通过最大后验概率确定样本所属的聚类。现在的问题是,如何学习高斯混合分布的参数。由于涉及隐变量Z,故可以采用EM算法求解。
输入:观察数据D,高斯混合成分个数K
输出:高斯混合模型参数
算法步骤:
1)取参数的初始值
2)迭代直至算法收敛。迭代过程如下:
E步:根据当前模型参数,计算分模型k对观测数据xj的响应度:Υjk
M步:计算新一轮迭代的模型参数:uk<i+1>,Σk<i+1>,αk<i+1>
实验代码:
实验结果:
奇怪的是这里所得到的结果与所想并不一致,和书中给的结果也不相同,但不知道原因在哪。
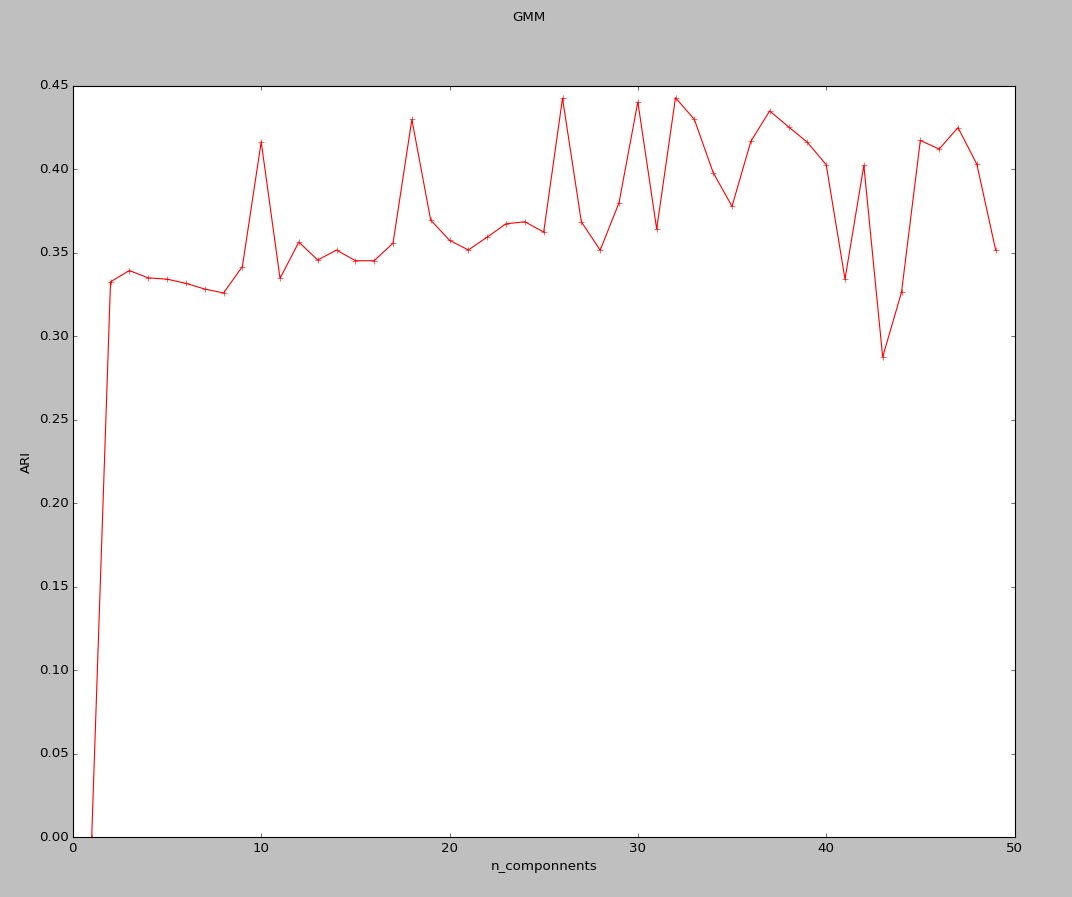
4、密度聚类
其假设聚类结构能够通过样本分布的紧密程度来确定。DBSCAN是常用的密度聚类算法
DBSCAN算法的定义:给定领域参数(ε,MinPts),一个簇C∈D是满足下列性质的非空样本子集:1)最大连接性 2)最大性 即一个簇是由密度可达关系导出的最大的密度相连样本集合
DBSCAN算法的思想:若x为核心对象,则x密度可达的所有样本组成的集合记作X,可以证明X就是满足连接性与最大性的簇。
输入:数据集D,领域参数(ε,MinPts)
输出:簇划分C
算法步骤:
1)初始化核心对象集合为空集
2)寻找核心对象
3)迭代:以任一未访问过的核心对象为出发点,找出有密度可达的样本生成的聚类簇,直到所有核心对象都被访问为止
实验代码:
实验结果:

5、层次聚类
其可在不用层上对数据集进行划分,形成树状的聚类结构。AGNES是一种常用的层次聚类算法
AGNES算法原理:AGNES首先将数据集中的每个样本看作一个初始的聚类簇,然后再不断地找出距离最近的两个聚类簇进行合并。就这样不断地合并直到达到预设的聚类簇的个数。
依据选择不同的距离计算方式,算法名不同。
输入:数据集D,聚类簇距离度量函数d,聚类簇数量K
输出:簇划分C
算法步骤:
1)初始化:每个样本都作为一个簇
2)迭代:终止条件为聚类簇的数量K(计算聚类簇之间的距离,找出距离最近的两个簇,将这两个簇合并)
代码如下:
实验结果:
可以看到,三种链接方式随分类簇的数量的总体趋势相差无几。但是单链接方式ward的峰值最大,且峰值最大的分类簇的数量刚好等于实际上生成样本的簇的数量
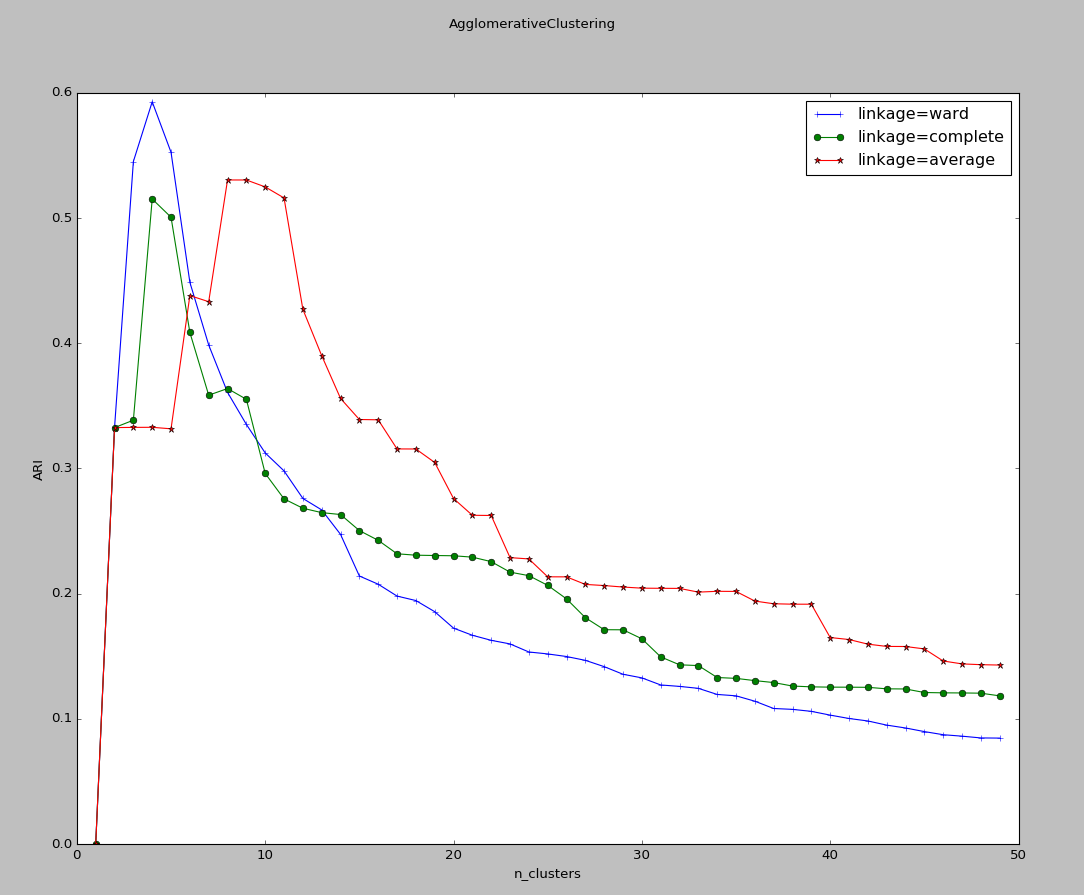
6、EM算法
也称为期望极大算法,它是一种迭代算法,用于含有隐变量的概率模型参数估计。
输入:观测变量数据Y,隐变量数据Z,联合分布P(Y,Z;θ),条件分布P(Z|Y;θ)
输出:模型参数θ
算法步骤:
1)选择参数的初值θ0
2)反复迭代直到收敛
注:1)EM算法的收敛性蕴含了两层意义:对数似然函数序列L(θi)收敛;参数估计序列θi收敛。前者并不蕴含后者。
2)EM算法的初值的选择非常重要,常用的办法是给出一批初值,然后分别从每个初值开始使用EM算法。最后对得到的各个估计值加以比较,从中选择对数似然函数最大的那个。
7、实际中的聚类要求
(1)可伸缩性
(2)不同类型属性的处理能力
(3)发现任意形状的类簇
(4)初始化参数
(5)算法的抗噪能力
(6)增量聚类和对输入次序的敏感度
(7)高维处理能力
(8)结果的可解释性和可用性
8、各种聚类算法的使用情况对比
| 模型 | 关键参数 | 使用场景 |
| K均值算法 | 簇的数量 |
通用聚类方法,用于均匀的簇的大小,簇的数量 不多的情况 |
| DBSCAN | ε,MinPts |
用于不均匀的簇大小,以及非平坦的集合结构 |
| AgglometativeClustering算法 | 簇的数量,链接类型 | 用于簇的数量较多,有链接约束等情况 |
| GMM算法 | 一些 | 用于平坦的集合结构,对密度估计很合适 |
在实际应用中,聚类簇的数量的选取通常结合性能度量指标和具体问题分析。
聚类和EM算法——K均值聚类的更多相关文章
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
- Sklearn K均值聚类
## 版权所有,转帖注明出处 章节 SciKit-Learn 加载数据集 SciKit-Learn 数据集基本信息 SciKit-Learn 使用matplotlib可视化数据 SciKit-Lear ...
- 【转】算法杂货铺——k均值聚类(K-means)
k均值聚类(K-means) 4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时 ...
- (ZT)算法杂货铺——k均值聚类(K-means)
https://www.cnblogs.com/leoo2sk/category/273456.html 4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先 ...
- 机器学习算法与Python实践之(六)二分k均值聚类
http://blog.csdn.net/zouxy09/article/details/17590137 机器学习算法与Python实践之(六)二分k均值聚类 zouxy09@qq.com http ...
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
随机推荐
- 【183】VMware + CentOS 安装教程等
目录: VMware 虚拟机安装 虚拟机上安装 CentOS VMware Tools 安装 为程序增加环境变量 其他 1. VMware 虚拟机安装 ※ 参考:VMware 虚拟机安装使用教程( ...
- 【插件开发】—— 8 IPreferenceStore,插件的键/值存储!
前文回顾: 1 插件学习篇 2 简单的建立插件工程以及模型文件分析 3 利用扩展点,开发透视图 4 SWT编程须知 5 SWT简单控件的使用与布局搭配 6 SWT复杂空间与布局搭配 7 SWT布局详解 ...
- spring boot+mybatis报错mapper无法注入
搭建spring boot项目时启动出现的问题,先来看异常片段: Error starting ApplicationContext. To display the conditions report ...
- js实现打字效果
<!DOCTYPE html> <html> <head> <meta charset='utf-8'> <title>js typing& ...
- _bzoj3224 Tyvj 1728 普通平衡树【Splay】
传送门:http://www.lydsy.com/JudgeOnline/problem.php?id=3224 保存splay模版 一刻不停写了一个小时多一点,幸好一遍过了!(其实带着freopen ...
- 数论+DP HDOJ 4345 Permutation
题目传送门 题意:一个置换群,经过最少k次置换后还原.问给一个N个元素,在所有的置换群里,有多少个不同的k. 分析:这道题可以转化成:N = Σ ai ,求LCM ( ai )有多少个不同的值.比如N ...
- 转 mysql oracle 指定rand随机数范围
若要在i ≤ R ≤ j 这个范围得到一个随机整数R ,需要用到表达式 FLOOR(i + RAND() * (j – i + 1)).例如, 若要在7 到 12 的范围(包括7和12)内得到一个随机 ...
- 1270 数组的最大代价 dp
http://www.51nod.com/onlineJudge/questionCode.html#!problemId=1270&judgeId=194704 一开始贪心,以为就两种情况, ...
- visual studio 2015 key vs2015密钥
Visual Studio Professional 2015简体中文版(专业版)KEY:HMGNV-WCYXV-X7G9W-YCX63-B98R2Visual Studio Enterprise 2 ...
- [BZOJ1008][HNOI2008]越狱 组合数学
http://www.lydsy.com/JudgeOnline/problem.php?id=1008 正着直接算有点难,我们考虑反着来,用全集减补集. 总的方案数为$m^n$.第一个人有$m$种可 ...