数据结构与算法之美学习笔记:B+树(第48讲)
一、解决问题的前提是定义清楚问题
通过对一些模糊需求进行假设,来限定要解决问题的范围
根据某个值查找数据,比如 select * from use where id=1234;
根据区间值来查询某些数据比如 select * from use where id > 1234 and id < 2345
性能方面的需求,我们主要考察时间和空间两方面,也就是执行效率和存储空间
执行效率:我么你希望通过索引,查询数据的效率尽可能的高;
存储空间方面:我们希望索引不需要消耗太多的内存空间
二、尝试用学过的数据结构解决这个问题
支持快速查询、插入等操作的动态数据结构,我们已经学过散列表、平衡二叉树、跳表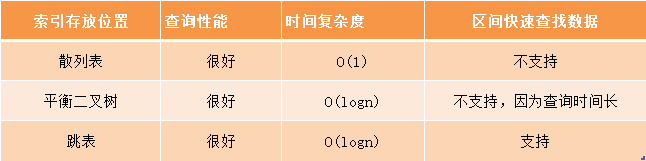

这样看来,跳表是可以解决这个问题,实际上,数据库索引所用到的数据结构跟跳表非常相似,叫做B+树
它是通过跳表演化雇来的,而非跳表
三、改造二叉查找树来解决这个问题
1、实现代码
/**
* 这是 B+ 树非叶子节点的定义。
*
* 假设 keywords=[3, 5, 8, 10]
* 4 个键值将数据分为 5 个区间:(-INF,3), [3,5), [5,8), [8,10), [10,INF)
* 5 个区间分别对应:children[0]...children[4]
*
* m 值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:
* PAGE_SIZE = (m-1)*4[keywordss 大小]+m*8[children 大小]
*/
public class BPlusTreeNode {
public static int m = 5; // 5 叉树
public int[] keywords = new int[m-1]; // 键值,用来划分数据区间
public BPlusTreeNode[] children = new BPlusTreeNode[m];// 保存子节点指针
} /**
* 这是 B+ 树中叶子节点的定义。
*
* B+ 树中的叶子节点跟内部结点是不一样的,
* 叶子节点存储的是值,而非区间。
* 这个定义里,每个叶子节点存储 3 个数据行的键值及地址信息。
*
* k 值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:
* PAGE_SIZE = k*4[keyw.. 大小]+k*8[dataAd.. 大小]+8[prev 大小]+8[next 大小]
*/
public class BPlusTreeLeafNode {
public static int k = 3;
public int[] keywords = new int[k]; // 数据的键值
public long[] dataAddress = new long[k]; // 数据地址 public BPlusTreeLeafNode prev; // 这个结点在链表中的前驱结点
public BPlusTreeLeafNode next; // 这个结点在链表中的后继结点
}
2、实现步骤

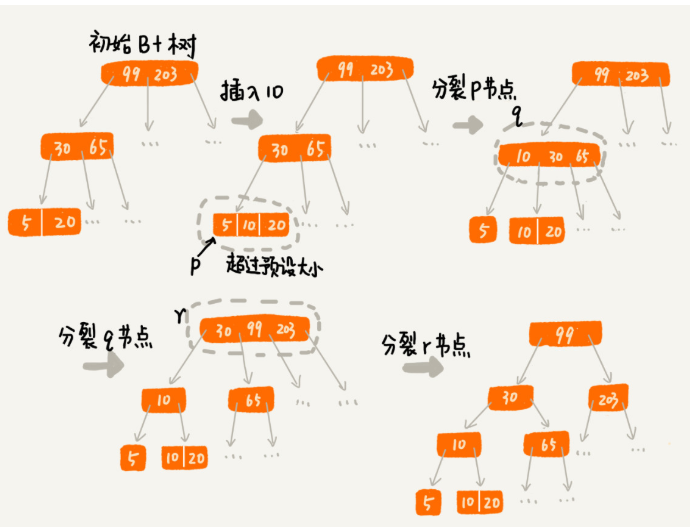
3、实现思路
分裂合并
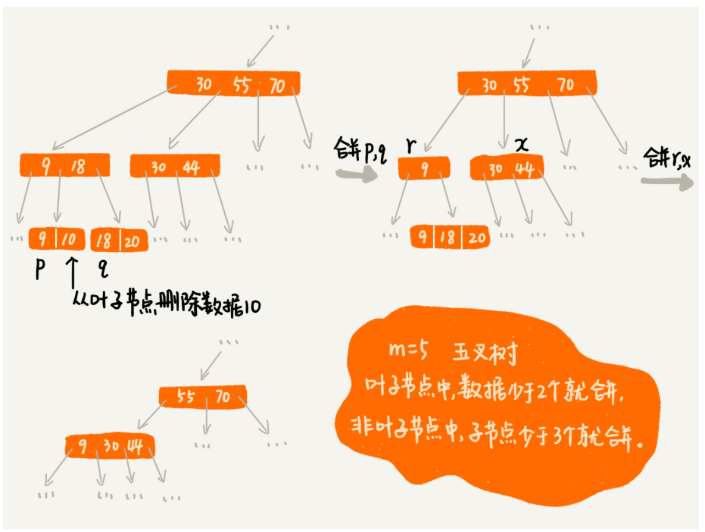
4、删除操作的例子
四、总结引申
1、每个节点中子节点的个数不能超过m,也不能小于m/2
2、根节点的子节点个数不可超过m/2,这是一个例外
3、M叉树只存储索引,并不真正存储数据,这个有点类似跳表
4、通过链表将叶子阶段串联在一次,这样可以方便区间查询
5、一般情况下,根节点会被存储在内存中,其他节点存储在磁盘中
数据结构与算法之美学习笔记:B+树(第48讲)的更多相关文章
- 【数据结构与算法Python版学习笔记】树——利用二叉堆实现优先级队列
概念 队列有一个重要的变体,叫作优先级队列. 和队列一样,优先级队列从头部移除元素,不过元素的逻辑顺序是由优先级决定的. 优先级最高的元素在最前,优先级最低的元素在最后. 实现优先级队列的经典方法是使 ...
- 【数据结构与算法Python版学习笔记】树——二叉树的应用:解析树
解析树(语法树) 将树用于表示语言中句子, 可以分析句子的各种语法成分, 对句子的各种成分进行处理 语法分析树 程序设计语言的编译 词法.语法检查 从语法树生成目标代码 自然语言处理 机器翻译 语义理 ...
- 【数据结构与算法Python版学习笔记】树——相关术语、定义、实现方法
概念 一种基本的"非线性"数据结构--树 根 枝 叶 广泛应用于计算机科学的多个领域 操作系统 图形学 数据库 计算机网络 特征 第一个属性是层次性,即树是按层级构建的,越笼统就越 ...
- 【数据结构与算法Python版学习笔记】树——平衡二叉搜索树(AVL树)
定义 能够在key插入时一直保持平衡的二叉查找树: AVL树 利用AVL树实现ADT Map, 基本上与BST的实现相同,不同之处仅在于二叉树的生成与维护过程 平衡因子 AVL树的实现中, 需要对每个 ...
- 【数据结构与算法Python版学习笔记】树——二叉查找树 Binary Search Tree
二叉搜索树,它是映射的另一种实现 映射抽象数据类型前面两种实现,它们分别是列表二分搜索和散列表. 操作 Map()新建一个空的映射. put(key, val)往映射中加入一个新的键-值对.如果键已经 ...
- 【数据结构与算法Python版学习笔记】树——树的遍历 Tree Traversals
遍历方式 前序遍历 在前序遍历中,先访问根节点,然后递归地前序遍历左子树,最后递归地前序遍历右子树. 中序遍历 在中序遍历中,先递归地中序遍历左子树,然后访问根节点,最后递归地中序遍历右子树. 后序遍 ...
- 数据结构与算法C++描述学习笔记1、辗转相除——欧几里得算法
前面学了一个星期的C++,以前阅读C++代码有些困难,现在好一些了.做了一些NOI的题目,这也是一个长期的目标中的一环.做到动态规划的相关题目时发现很多问题思考不通透,所以开始系统学习.学习的第一本是 ...
- 【数据结构与算法Python版学习笔记】引言
学习来源 北京大学-数据结构与算法Python版 目标 了解计算机科学.程序设计和问题解决的基本概念 计算机科学是对问题本身.问题的解决.以及问题求解过程中得出的解决方案的研究.面对一 个特定问题,计 ...
- 【数据结构与算法Python版学习笔记】查找与排序——散列、散列函数、区块链
散列 Hasing 前言 如果数据项之间是按照大小排好序的话,就可以利用二分查找来降低算法复杂度. 现在我们进一步来构造一个新的数据结构, 能使得查找算法的复杂度降到O(1), 这种概念称为" ...
随机推荐
- 智能ERP收银统计-优惠统计计算规则
1.报表统计->收银统计->优惠统计规则 第三方平台优惠:(堂食订单:支付宝口碑券优惠)+(外卖订单:商家承担优惠) 自平台优惠:(堂食订单:商家后台优 ...
- SQL ----post漏洞测试注入
使用工具sqlmap 输入账号密码进行bp截断,获取文本保存在sqlmap下面2.txt 爆数据库 爆表爆表 爆数据 最后把数据密码md5解析
- PYTHON定义函数制作简单登录程序(详细)
环境:python3.* 结构: dict_name = {} #定义一个字典,后面用到 def newuser(): #定义注册函数 prompt1='login desired:' while ...
- 开发环境---->服务器(数据库迁移Migration)
1.查找服务器环境迁移记录表的最近一次迁移名称 SELECT * FROM __efmigrationshistory; 最后一次:20190225075007_UpdateSocialApplyCo ...
- c++ 指针做为参数和返回值
指针参数 返回值是指针 一.指针作参数形式的函数 //计算x的平方 x*x void square(int *x) { int a=*x; *x=a*a; } 二.指针作返回值的函数 int *squ ...
- An interesting combinational problem
A question of details in the solution at the end of this post of the question is asked by me at MSE. ...
- iic接口介绍
最近遇到一个BUG,跟IIC通信有关,所以借这个机会总结一下IIC总线协议 1.引脚接口介绍 1.A0,A1,A2为24LC64的片选信号,IIC总线最多可以挂载8个IIC接口器件,通过对A0,A1, ...
- Docker部署脚本
实现 1.检查内核版本 2.检查docker是否已安装 3.安装docker,如因网络等原因失败循环安装至安装完成 #!/bin/bash #file:docker_install.sh #From: ...
- linux定时备份学习笔记
1.iterm2链接远程中文乱码 shh端vi ~/.bash_profile export LC_CTYPE=en_US.UTF-8 source ~/.bash_profile 2.WARNI ...
- 深度解读Tomcat中的NIO模型(转载)
转自https://www.jianshu.com/p/76ff17bc6dea 一.I/O复用模型解读 Tomcat的NIO是基于I/O复用来实现的.对这点一定要清楚,不然我们的讨论就不在一个逻辑线 ...