【Spark篇】---Spark中广播变量和累加器
一、前述
Spark中因为算子中的真正逻辑是发送到Executor中去运行的,所以当Executor中需要引用外部变量时,需要使用广播变量。
累机器相当于统筹大变量,常用于计数,统计。
二、具体原理
1、广播变量
- 广播变量理解图

- 注意事项
1、能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
2、 广播变量只能在Driver端定义,不能在Executor端定义。
3、 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
4、如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本。
5、如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本。
val conf = new SparkConf()
conf.setMaster("local").setAppName("brocast")
val sc = new SparkContext(conf)
val list = List("hello xasxt")
val broadCast = sc.broadcast(list)
val lineRDD = sc.textFile("./words.txt")
lineRDD.filter { x => broadCast.value.contains(x) }.foreach { println}
sc.stop()
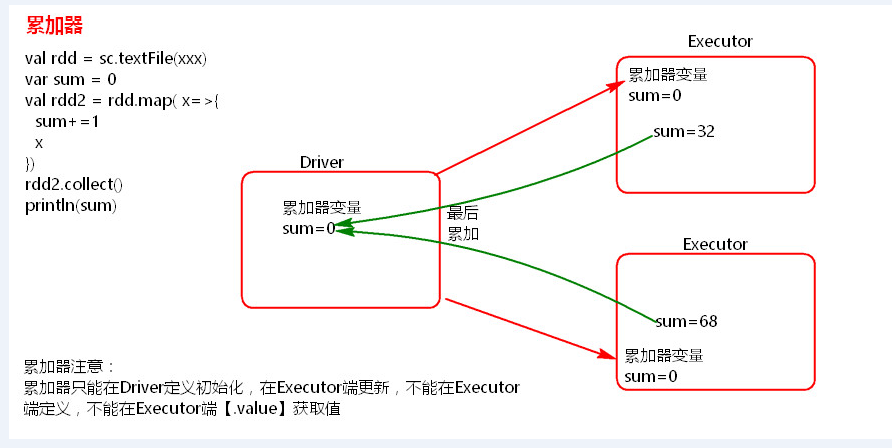
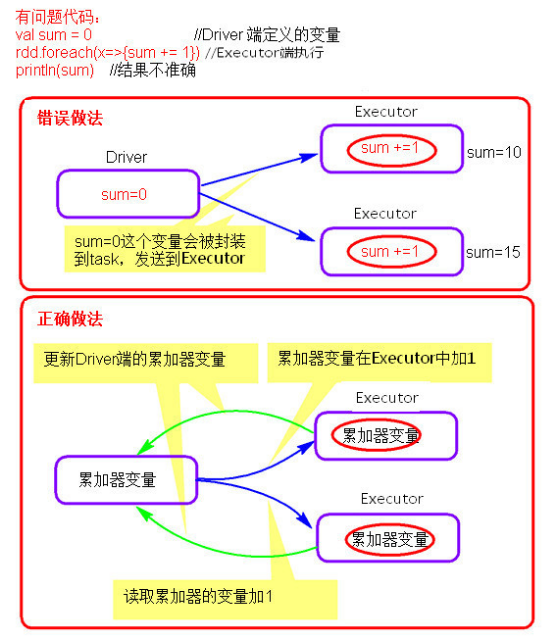
2、累加器
- 累加器理解图
Scala代码:
import org.apache.spark.{SparkConf, SparkContext}
object AccumulatorOperator {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("accumulator")
val sc = new SparkContext(conf)
val accumulator = sc.accumulator(0)
sc.textFile("./records.txt",2).foreach {//两个变量
x =>{accumulator.add(1)
println(accumulator)}}
println(accumulator.value)
sc.stop()
}
}
java代码:
package com.spark.spark.others; import org.apache.spark.Accumulator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
/**
* 累加器在Driver端定义赋初始值和读取,在Executor端累加。
* @author root
*
*/
public class AccumulatorOperator {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("accumulator");
JavaSparkContext sc = new JavaSparkContext(conf);
final Accumulator<Integer> accumulator = sc.accumulator(0);
// accumulator.setValue(1000);
sc.textFile("./words.txt",2).foreach(new VoidFunction<String>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public void call(String t) throws Exception {
accumulator.add(1);
// System.out.println(accumulator.value());
System.out.println(accumulator);
}
});
System.out.println(accumulator.value());
sc.stop(); }
}
结果:

- 注意事项
累加器在Driver端定义赋初始值,累加器只能在Driver端读取最后的值,在Excutor端更新。
【Spark篇】---Spark中广播变量和累加器的更多相关文章
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- Spark(三)RDD与广播变量、累加器
一.RDD的概述 1.1 什么是RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可 ...
- Spark——DataFrames,RDD,DataSets、广播变量与累加器
Spark--DataFrames,RDD,DataSets 一.弹性数据集(RDD) 创建RDD 1.1RDD的宽依赖和窄依赖 二.DataFrames 三.DataSets 四.什么时候使用Dat ...
- Spark 广播变量和累加器
Spark 的一个核心功能是创建两种特殊类型的变量:广播变量和累加器 广播变量(groadcast varible)为只读变量,它有运行SparkContext的驱动程序创建后发送给参与计算的节点.对 ...
- Spark(八)【广播变量和累加器】
目录 一. 广播变量 使用 二. 累加器 使用 使用场景 自定义累加器 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的 ...
- Spark性能优化(2)——广播变量、本地缓存目录、RDD操作、数据倾斜
广播变量 背景 一般Task大小超过10K时(Spark官方建议是20K),需要考虑使用广播变量进行优化.大表小表Join,小表使用广播的方式,减少Join操作. 参考:Spark广播变量与累加器 L ...
- 广播变量、累加器、collect
广播变量.累加器.collect spark集群由两类集群构成:一个驱动程序,多个执行程序. 1.广播变量 broadcast 广播变量为只读变量,它由运行sparkContext的驱动程序创建后发送 ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- Spark学习之路 (四)Spark的广播变量和累加器
一.概述 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本.这些变量会被复制到每台机器上 ...
随机推荐
- maven发布到tomcat报错: Publishing failed Could not publish to the server. java.lang.IndexOutOfBoundsException
eclipse中将maven项目发布到tomcat报错时: Publishing failed Could not publish to the server. java.lang.IndexOutO ...
- kvm虚拟机迁移
一.迁移简介 迁移: 系统的迁移是指把源主机上的操作系统和应用程序移动到目的主机,并且能够在目的主机上正常运行.在没有虚拟机的时代,物理机之间的迁移依靠的是系统备份和恢复技术.在源主机上实时备份操作系 ...
- sublime2 nodejs 执行编译无反应
这个问题困扰了我得一周了,好不容易解决了, 一.问题描述: 安装网上的一些教程在sublime text 2 里面安装Nodejs 的编译环境,但是安装完之后执行编译没有任何输出信息,编译没有反应,只 ...
- Exp3 免杀原理与实践 20164302 王一帆
1 实践内容 1.1 正确使用msf编码器(0.5分),msfvenom生成如jar之类的其他文件(0.5分),veil-evasion(0.5分),加壳工具(0.5分),使用shellcode编程( ...
- lua 文件编译相关工具
-- 编译一个代码文件 -- loadfile (lua_State *L, const char *filename); -- 将一个文件加载为lua代码块,仅编译不执行,返回值为编译后的 -- 代 ...
- ES6学习
一.ES6的特点 1.let(变量),const(常量) 2.在ES6中不能重复定义 3.块级作用域 普通作用域 if(true){ var test =1; } console.log(test); ...
- pta-树种统计
树种统计 (25 分) 随着卫星成像技术的应用,自然资源研究机构可以识别每一棵树的种类.请编写程序帮助研究人员统计每种树的数量,计算每种树占总数的百分比. 输入格式: 输入首先给出正整数N(≤105 ...
- Python 版本管理anaconda
下载安装 下载地址 :anaconda官网 下载后直接命令行安装,默认安装按enter 和yes bash Anaconda3-5.2.0-Linux-x86_64.sh 按照官网上下一步直接用con ...
- C语言表达式和语句
一.表达式 在C语言中,常量.变量.函数调用以及按C语言语法规则用运算符把运算数连接起来的式子都是合法的表达式 . 最后一类可以理解为运算符和运算对象的组合.例如: 算术表达式 = 算术运算符 + 运 ...
- DHCP工作原理简析
引言 DHCP是网络体系结构中应用层的一个重要协议,它可以帮助我们对要连接到互联网的计算机进行IP地址等信息的配置.本文从DHCP的原理出发,就DHCP的工作过程 进行详细的探讨. 主要报文 发现报文 ...