【NLP】Conditional Language Models
Language Model estimates the probs that the sequences of words can be a sentence said by a human. Training it, we can get the embeddings of the whole vocabulary.
UnConditional Language Model just assigns probs to sequences of words. That’s to say, given the first n-1 words and to predict the probs of the next word.(learn the prob distribution of next word).
Beacuse of the probs chain rule, we only train this:
Conditional LMs
A conditional language model assigns probabilities to sequences of words, W =(w1,w2,…,wt) , given some conditioning context x.
For example, in the translation task, we must given the orininal sentence and its translation. The orininal sentence is the conditioning context, and by using it, we predict the objection sentence.
Data for training conditional LMs:
To train conditional language models, we need paired samples.E.X.
Such task like:Translation, summarisation, caption generation, speech recognition
How to evaluate the conditional LMs?
- Traditional methods: use the cross-entropy or perplexity.(hard to interpret,easy to implement)
- Task-specific evaluation: Compare the model’s most likely output to human-generated expected output . Such as 【BLEU】、METEOR、ROUGE…(okay to interpret,easy to implement)
- Human evaluation: Hard to implement.
Algorithmic challenges:
Given the condition context x, to find the max-probs of the the predict sequence of words, we cannot use the gready search, which might cann’t generate a real sentence.
We use the 【Beam Search】.
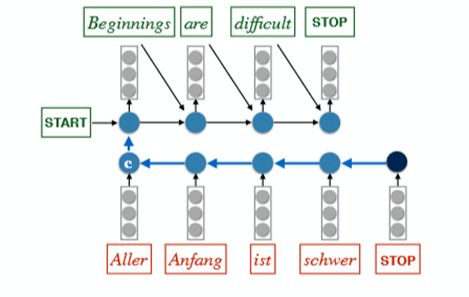
We draw attention to the “encoder-decoder” models that learn a function that maps x into a fixed-size vector and then uses a language model to “decode” that vector into a sequence of words,
Model: K&B2013
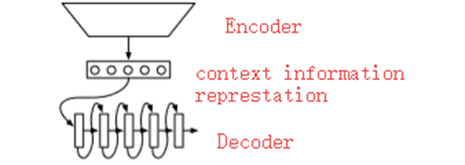
A simpal of Encoder – just cumsum(very easy)
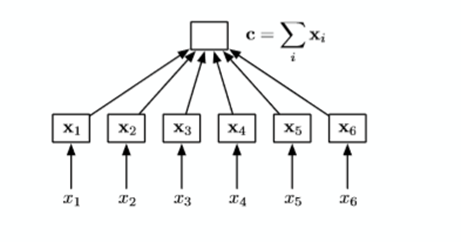
A simpal of Encoder – CSM Encoder:use CNN to encode
The Decoder – RNN Decoder
The cal graph is.
Sutskever et al. Model (2014):
- Important.Classic Model
Cal Graph:
Some Tricks to Sutskever et al. Model :
- Read the Input Sequence ‘backwards’: +4BLEU
- Use an ensemble of m 【independently trained】 models (at the decode period) :
- Ensemble of 2 models: +3 BLEU
- Ensemble of 5 models: +4.5 BLEU
For example:
- we want to find the most probable (MAP) output given the input,i,e.
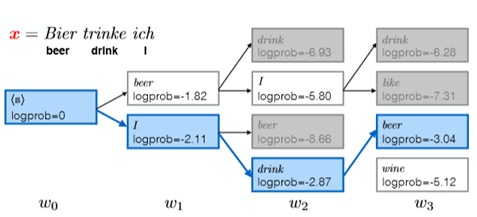
We use the beam search : +1BLEU
For example,the beam size is 2:
Example of A Application: Image caption generation
Encoder:CNN
Decoder:RNN or
conditional n-gram LM(different to the RNN but it is useful)
We must have some datasets already.
Kiros et al. Model has done this.
.

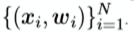






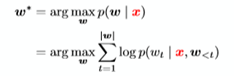
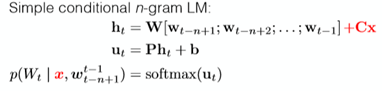
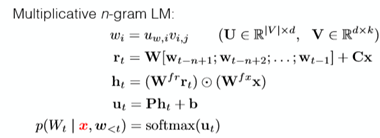
【NLP】Conditional Language Models的更多相关文章
- 【NLP】Conditional Language Modeling with Attention
Review: Conditional LMs Note that, in the Encoder part, we reverse the input to the ‘RNN’ and it per ...
- [转]【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理 阅读目录
[NLP]干货!Python NLTK结合stanford NLP工具包进行文本处理 原贴: https://www.cnblogs.com/baiboy/p/nltk1.html 阅读目录 目 ...
- 【NLP】Tika 文本预处理:抽取各种格式文件内容
Tika常见格式文件抽取内容并做预处理 作者 白宁超 2016年3月30日18:57:08 摘要:本文主要针对自然语言处理(NLP)过程中,重要基础部分抽取文本内容的预处理.首先我们要意识到预处理的重 ...
- 【NLP】前戏:一起走进条件随机场(一)
前戏:一起走进条件随机场 作者:白宁超 2016年8月2日13:59:46 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都有 ...
- 【NLP】基于自然语言处理角度谈谈CRF(二)
基于自然语言处理角度谈谈CRF 作者:白宁超 2016年8月2日21:25:35 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务 ...
- 【NLP】基于机器学习角度谈谈CRF(三)
基于机器学习角度谈谈CRF 作者:白宁超 2016年8月3日08:39:14 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都 ...
- 【NLP】基于统计学习方法角度谈谈CRF(四)
基于统计学习方法角度谈谈CRF 作者:白宁超 2016年8月2日13:59:46 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务 ...
- 【NLP】条件随机场知识扩展延伸(五)
条件随机场知识扩展延伸 作者:白宁超 2016年8月3日19:47:55 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都有应 ...
- 【NLP】Recurrent Neural Network and Language Models
0. Overview What is language models? A time series prediction problem. It assigns a probility to a s ...
随机推荐
- es6 Symbol类型
es6 新增了一个原始类型Symbol,代表独一无二的数据 javascript 原来有6中基本类型, Boolean ,String ,Object,Number, null , undefined ...
- 网络最大流算法—EK算法
前言 EK算法是求网络最大流的最基础的算法,也是比较好理解的一种算法,利用它可以解决绝大多数最大流问题. 但是受到时间复杂度的限制,这种算法常常有TLE的风险 思想 还记得我们在介绍最大流的时候提到的 ...
- 版本控制工具(SVN/Git)介绍
文章大纲 一.SVN介绍二.Git介绍三.IDEA使用SVN和Git四.总结五.参考文章 一.SVN介绍 1. SVN服务器搭建和使用 首先来下载和搭建SVN服务器,下载地址如下: http:// ...
- (办公)MojoExecutionException
MojoExecutionException : mavan打包错误. 通过以下命令解决:mvn clean install (新改的内容生效)
- SQLServer之创建主XML索引
创建主XML索引注意事项 若要创建主 XML 索引,请使用 CREATE INDEX (Transact-SQL) Transact-SQL DDL 语句. XML 索引不完全支持可用于非 XML 索 ...
- 面向对象_classmethod_staticmethod
classmethod:类方法 主要用于改变静态属性 class Fruit_price: __discount= 1 def __init__(self,original_price): self. ...
- RabbitMQ广播:fanout模式
一. 消息的广播需要exchange:exchange是一个转发器,其实把消息发给RabbitMQ里的exchange fanout: 所有bind到此exchange的queue都可以接收消息,广播 ...
- tmpfs使用探讨
一. 什么是tmpfs? tmpfs是一种基于内存的文件系统,它和虚拟磁盘ramdisk比较类似,但不完全相同,和ramdisk一样,tmpfs可以使用RAM,但它也可以使用swap分区来存储. 而且 ...
- python3 json模块
import json '''把python对象转化为json串(字符串), ensure_ascii处理中文乱码'''dic = {"复联4": "好看吗", ...
- C# 将普通字符串转换为二进制字符串
1.因为项目的需要,在向数据库中添加人的信息时,必须要求是英文或数字,所以想了个办法,将我们人能看懂的字符串编译成二进制字符串转入就行了. 具体的逻辑实现代码如下: