【NLP】Conditional Language Modeling with Attention
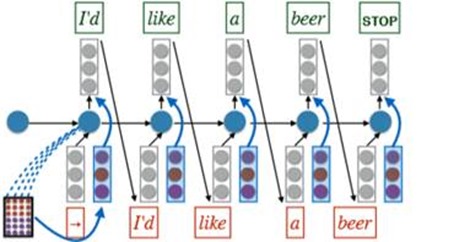
Review: Conditional LMs
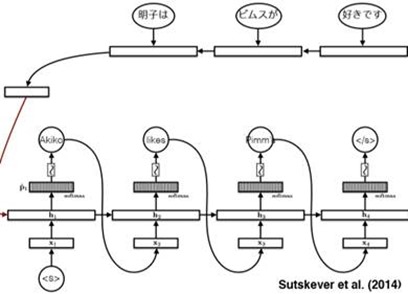
Note that, in the Encoder part, we reverse the input to the ‘RNN’ and it performs well.
And we use the Decoder network(also a RNN), and use the ‘beam search’ algorithm to generate the target statement word by word.
The above network is a translation model.But it still needs to optimizer.
A very essential part of the model is the [Attention mechanism].
Conditional LMs with Attention
First: talk about the [condition]
In last blog, we compress a lot of information in a finite-sized vector and use it as the condition. That is to say, in the ‘Decoder’, for each input we use this vector as the condition to predict the next word.
But is it really correct?
An obvious thing is that a finite-sized vector cannot contain all the information since the input sentence could have a very one length. And gradients have a long way to travl so even LSTMs could forget!
In Translation Question, we can solve the problem by this:
Represent a source sentence as a matrix whose size can be changeable.
Then Generate a target sentence from the matrix. (As the condition and the condition is transformed form that matrix)
So how does this do?
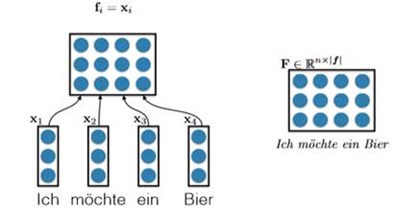
The very simpal way to fulfill that is [With Concatenation].
We have already known that the words can be represented by ‘embedding’ such as Word2Vec. And all the embeddings have the same size. For a sentence composed by n words, we can just put each word’s embedding together. So the matrix size is |vocabulary size|*n, which n is the length of sentence. That’s a really easy solution but it is useful. E.g.
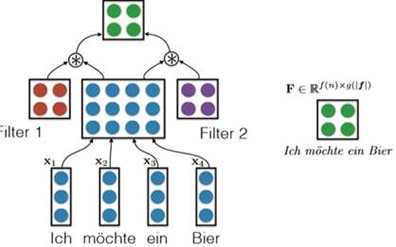
Another solution proposed by Gehring et al. (2016,FAIR) is [With Convolutional Nets].
It is to say, we use all embedding of the word from the sentence to form the concatenation matrix (just like the above method), and then we use a CNN to handle this matrix using some filters. And final we also generate a new matrix to represent the information. And in my opinion, this is a bit like extracting advanced features from image processing. E.g.
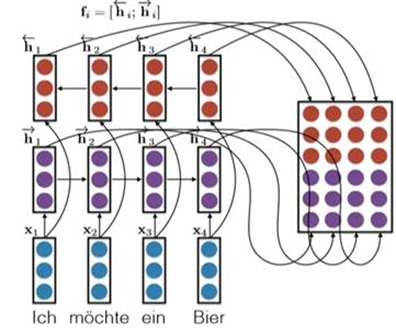
The most important method is [using the Bidirectional RNNs].
For one side, we use a RNN to handle the embedding, and we get n hidden layers which n is the length of the word.
For another side, we use another RNN to handle the embedding, but we reverse the input and finally we also get n hidden layers.
We put the 2n hidden layers together to generate the conditional matrix. E.g.
There are some other ways needed to be founded.
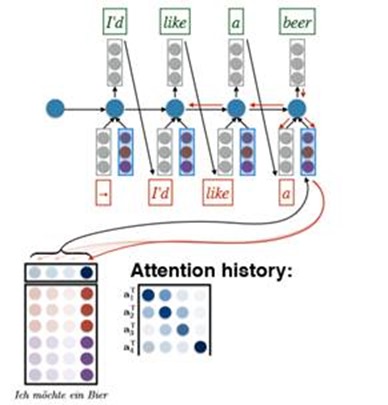
So next to the important part: how to use the ‘Attention model’ and use the attention to generate the condition vector form the condition matrix F.
Firstly, considering the decoder RNN:
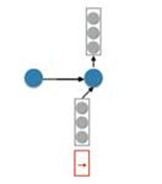
We have a ‘start hidden layer’ and then generate the next hidden layer using the input x and we still need a conditional vector.
Suppose we also had an attention vector a. We can generate the condition vector by doing this:
c = Fa. Where F is the matrix and a is the attention vector. This can be understood as weighting the conditional matrix so that we can pay more attention to the contents of a certain sentence.
E.g.
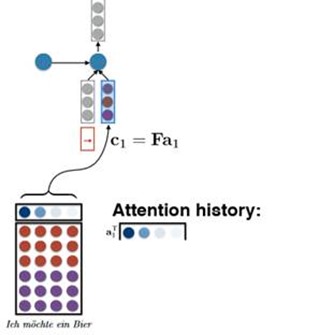
So How to generate the Attention Vector?
That is, how do we compute a.
We can do by the following method:
For the time t, we know the hidden layer Ht-1, and we do linear transformation to it to generate a vector r. ( r = VHt-1) V is the learned parameter. Then we take dot product with every column in the source matrix to compute the attention energy a. ( a = F.T*r). So we generate the attention vector a by using a softmax to Exponentiate and normalize it to 1.
That is a simplified version of Bahdanau et al.’s solution. Summary of it:
|
|

Another complex way to generate the attention vector is to use the [Nonlinear Attention-Energy Model].
Getting the r above, ( r = VHt-1) we generate a by: a = v.T * tanh(WF + r). Where v W and V is the learned parameter. How useful of the r is not to verify.
Summary
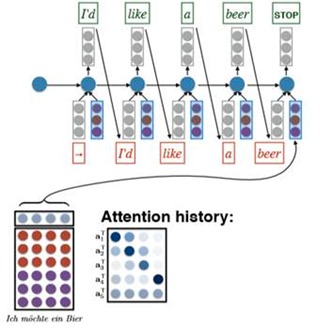
We put it all together and this is called the conditional LM with attention.
|
|
|
|
|
|



Attention in machine translation.
Add attention to seq2seq model translation: +11 BLEU.
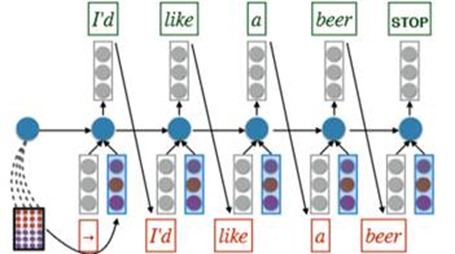
An improvement in computing:
Note the difference form the above model. But whether it is useful is not sure.
About Gradients
We use the Gradient Descent.
Comprehension
Cho’s question: does a translator read and memorize the input sentence/document and then generate the output?
• Compressing the entire input sentence into a vector basically says “memorize the sentence”
• Common sense experience says translators refer back and forth to the input. (also backed up by eyetracking studies)
Image caption generation with attention: brief introduction
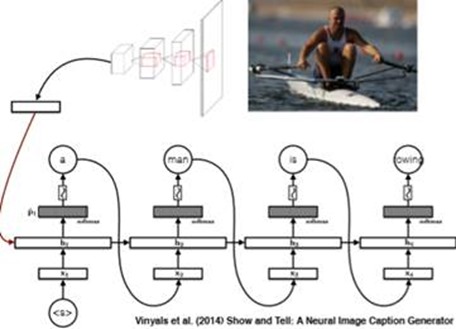
The main idea is that: we encode the picture to a matrix F and use it generate some attention and finally use the attention to generate the caption.
Generate matrix F:
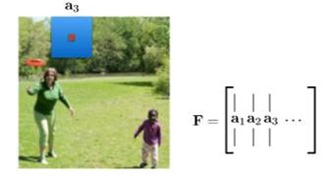
Attention “weights” (a) are computed using exactly the same technique as discussed above.
Other techinques: Stochastic hard attention(sampling matrix F idea and not like the weighting matrix F idea). Learning Hard Attention. To be honesty, I don't know much about this.
【NLP】Conditional Language Modeling with Attention的更多相关文章
- 【NLP】Conditional Language Models
Language Model estimates the probs that the sequences of words can be a sentence said by a human. Tr ...
- 【NLP】Tika 文本预处理:抽取各种格式文件内容
Tika常见格式文件抽取内容并做预处理 作者 白宁超 2016年3月30日18:57:08 摘要:本文主要针对自然语言处理(NLP)过程中,重要基础部分抽取文本内容的预处理.首先我们要意识到预处理的重 ...
- [转]【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理 阅读目录
[NLP]干货!Python NLTK结合stanford NLP工具包进行文本处理 原贴: https://www.cnblogs.com/baiboy/p/nltk1.html 阅读目录 目 ...
- 【NLP】前戏:一起走进条件随机场(一)
前戏:一起走进条件随机场 作者:白宁超 2016年8月2日13:59:46 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都有 ...
- 【NLP】基于自然语言处理角度谈谈CRF(二)
基于自然语言处理角度谈谈CRF 作者:白宁超 2016年8月2日21:25:35 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务 ...
- 【NLP】基于机器学习角度谈谈CRF(三)
基于机器学习角度谈谈CRF 作者:白宁超 2016年8月3日08:39:14 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都 ...
- 【NLP】基于统计学习方法角度谈谈CRF(四)
基于统计学习方法角度谈谈CRF 作者:白宁超 2016年8月2日13:59:46 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务 ...
- 【NLP】条件随机场知识扩展延伸(五)
条件随机场知识扩展延伸 作者:白宁超 2016年8月3日19:47:55 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都有应 ...
- 【NLP】Attention Model(注意力模型)学习总结
最近一直在研究深度语义匹配算法,搭建了个模型,跑起来效果并不是很理想,在分析原因的过程中,发现注意力模型在解决这个问题上还是很有帮助的,所以花了两天研究了一下. 此文大部分参考深度学习中的注意力机制( ...
随机推荐
- pthread_once()函数详解
转自:pthread_once()函数详解 pthread_once()函数详解 在多线程环境中,有些事仅需要执行一次.通常当初始化应用程序时,可以比较容易地将其放在main函数中.但当你写一个库 ...
- android.database.sqlite.SQLiteException: no such column: aaa (code 1): , while compiling: DELETE FROM users WHERE user_name=aaa解决办法
在写安卓登录注册时注销按钮闪退发现: 这是因为此处错误: 因为用户名为字符串,不是整型,数据库查询要引号,少了引号查询不了,导致闪退 解决后成功运行 正确用法: 下次谨记,细节决定成败呀!
- idea连接服务器上传jar并运行
.打开idea tools-deployment-configuration.. .打开如图 点击 + 号 .如 ...
- hadoop1.0 和 Hadoop 2.0 的区别
1.Hadoop概述 在Google三篇大数据论文发表之后,Cloudera公司在这几篇论文的基础上,开发出了现在的Hadoop.但Hadoop开发出来也并非一帆风顺的,Hadoop1.0版本有诸多局 ...
- GCD多线程的一个全面的题目
GCD多线程的一个全面的题目
- 利用ZYNQ SOC快速打开算法验证通路(2)——数据传输最简方案:网络调试助手+W5500协议栈芯片
在上一篇该系列博文中讲解了MATLAB待处理数据写入.bin二进制数据文件的过程,接下来需要将数据通过以太网发送到ZYNQ验证平台.之前了解过Xilinx公司面向DSP开发的System Genera ...
- php操作Memcache的一个类库
###php操作Memcache的一个类库 代码如下: <?php /** * Created by PhpStorm. * User: alisleepy * Date: 2019-03-14 ...
- PowerDesigner导出SQL,注释为空时以name代替
版本 操作步骤 打开Edit Current DBMS 选中Script->Objects->Column->Add 将Value中的内容全部替换为如下 %20:COLUMN% [% ...
- 我的第一个python web开发框架(29)——定制ORM(五)
接下来我们要封装的是修改记录模块. 先上产品信息编辑接口代码 @put('/api/product/<id:int>/') def callback(id): ""&q ...
- DRF 序列化器-Serializer (2)
作用 1. 序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串 2. 完成数据校验功能 3. 反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器 ...