Spark环境搭建(三)-----------yarn环境搭建及测试作业提交
配置好HDFS之后,接下来配置单节点的yarn环境
1,修改配置文件
文件 : /root/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/yarn-site-xml
插入
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
文件: /root/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/mapred-site.xml
插入
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2,启动yarn
命令: sbin/start.yarn.sh
3,验证yarn启动成功
1) 命令:jps
显示
7945 Jps
6227 SecondaryNameNode
6060 DataNode
5745 NameNode
5031 NodeManager
4922 ResourceManager
2) 浏览器:
http://hadoop001:8088/
4,提交作业到yarn执行(以wordcount为例)
1) 现将一个文本文件上传到HDFS中
2)执行一个Jar文件,使用命令
hadoop jar /home/app/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount /data/wc-text.txt /output/wc/
3) 使用浏览器查看任务
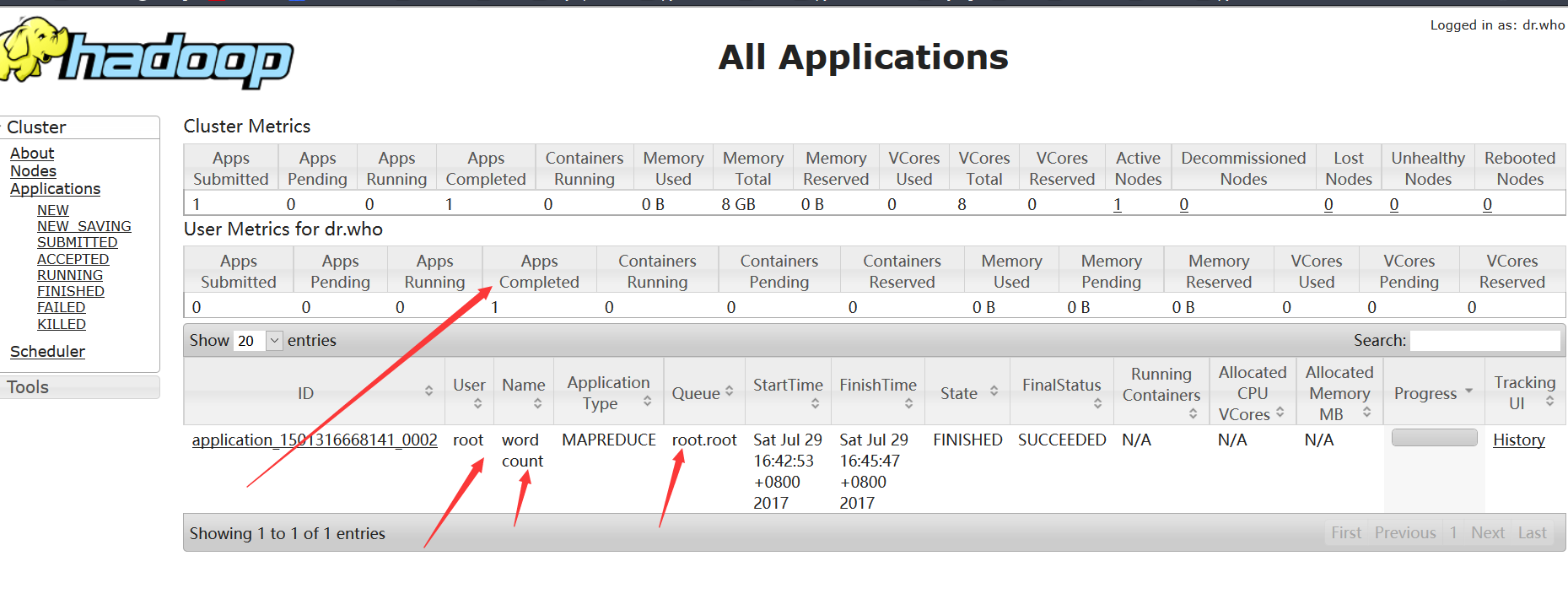
4)在HDFS中查看结果
命令: hadoop fs -ls -R /
hadoop fs -cat /output/wc/part-r-00000
5)结果:

原文件:

至此,yarn环境搭建完毕
Spark环境搭建(三)-----------yarn环境搭建及测试作业提交的更多相关文章
- 用IntelliJ IDEA 开发Spring+SpringMVC+Mybatis框架 分步搭建三:配置spring并测试
这一部分的主要目的是 配置spring-service.xml 也就是配置spring 并测试service层 是否配置成功 用IntelliJ IDEA 开发Spring+SpringMVC+M ...
- Java学习笔记之linux配置java环境变量(三种环境变量)
0x00 压安装jdk 在shell终端下进入jdk-6u14-linux-i586.bin文件所在目录, 执行命令 ./jdk-6u14-linux-i586.bin 这时会出现一段协议,连继敲回车 ...
- 【源码学习之spark core 1.6.1 standalone模式下的作业提交】
说明:个人原创,转载请说明出处 http://www.cnblogs.com/piaolingzxh/p/5656876.html 未完待续
- 用IntelliJ IDEA 开发Spring+SpringMVC+Mybatis框架 分步搭建二:配置MyBatis 并测试(2 配置spring-dao和测试)
用IntelliJ IDEA 开发Spring+SpringMVC+Mybatis框架 分步搭建二:配置MyBatis 并测试(1 搭建目录环境和依赖) 四:在\resources\spring 下面 ...
- 通过IDEA搭建scala开发环境开发spark应用程序
一.idea社区版安装scala插件 因为idea默认不支持scala开发环境,所以当需要使用idea搭建scala开发环境时,首先需要安装scala插件,具体安装办法如下. 1.打开idea,点击c ...
- IDEA搭建scala开发环境开发spark应用程序
通过IDEA搭建scala开发环境开发spark应用程序 一.idea社区版安装scala插件 因为idea默认不支持scala开发环境,所以当需要使用idea搭建scala开发环境时,首先需要安 ...
- Spark开发环境搭建和作业提交
Spark高可用集群搭建 在所有节点上下载或上传spark文件,解压缩安装,建立软连接 配置所有节点spark安装目录下的spark-evn.sh文件 配置slaves 配置spark-default ...
- 搭建Data Mining环境(Spark版本)
前言:工欲善其事,必先利其器.倘若不懂得构建一套大数据挖掘环境,何来谈Data Mining!何来领悟“Data Mining Engineer”中的工程二字!也仅仅是在做数据分析相关的事罢了!此文来 ...
- Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录
Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录 Hadoop 2.6 的安装与配置(伪分布式) 下载并解压缩 配置 .bash_profile : ...
随机推荐
- JavaXML整理
XML 浏览器的入口不同(访问路径),访问的资源也不同. 1.1XML语法 1.文档声明必须为<?xml开头,以?>结束; 2.文档声明必须从文档的0行0列位置开始: 3.文档声明只有属性 ...
- C# 另一种提交表单
一般提交表单的方式就是:Get,Post 以及关联action 今天看了一种方式感觉不错: 可以在submit里面写 PostBackUrl="XXXX",即回发的URL,可以实现 ...
- django - 总结 - ORM性能
QuerySet 1.惰性查询 2.缓存机制 3.可迭代 4.可切片 -------------------------------------------------------在一个新创建的查询集 ...
- [Everyday Mathematics]20150306
在王高雄等<常微分方程(第三版)>习题 2.5 第 1 题第 (32) 小题: $$\bex \frac{\rd y}{\rd x}+\frac{1+xy^3}{1+x^3y}=0. \e ...
- [物理学与PDEs]第5章第3节 守恒定律, 应力张量
5. 3 守恒定律, 应力张量 5. 3. 1 质量守恒定律 $$\bex \cfrac{\p \rho}{\p t}+\Div_y(\rho{\bf v})=0. \eex$$ 5. 3. 2 应 ...
- [物理学与PDEs]第1章第6节 电磁场的标势与矢势 6.1 预备知识
1. 若 ${\bf B}$ 为横场 ($\Div{\bf B}=0\ra {\bf k}\cdot {\bf B}=0\ra $ 波的振动方向与传播方向平行), 则 $$\bex \exists\ ...
- jpa返回List<Map<String, Object>>相当于jdbctemplate的queryForlist
public class Test(){ @PersistenceContext(unitName = "manageFactory") protected EntityManag ...
- sql注入学习 sqlliab教程 lesson1 (sqlliab搭建教程)
靶场搭建 小白建议直接用集成环境.推荐laragon (由于这套靶场较早,需要使用php7.0以下环境,安装完php laragon需要在安装php低版本,默认laragon只集成了一个7.0的php ...
- 【汇总目录】C#
[2019年04月29日] C# textbox 自动滚动 [2019年02月07日] C#利用VUDP.cs开发网络通讯应用程序 [2019年02月06日] C#利用VINI.cs操作INI文件 [ ...
- Kotlin 的优缺点
从Android 7.0开始,谷歌使用的API从Oracle JDK切换到了open JDK,这对于谷歌来说是一个艰难的决定.对于开发者来说,却倍感兴奋,这意味着长期的官司问题也许就此结束,Andro ...